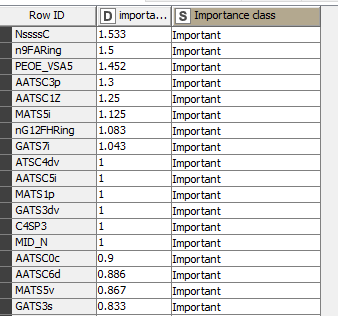
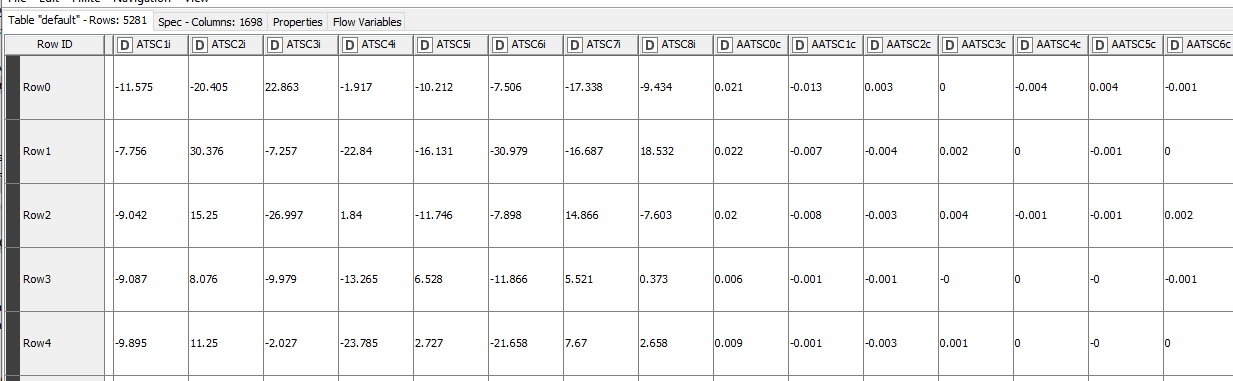
I would like to filter my original dataset to only retain the columns that are considered “Important” in the reference data table.
Is there a way to automate this? I know I could manually filter down the columns by name, but I would like to change the importance value and analyze the differences. Plus I am working with 5,000 columns.
I am struggling because I would need something like a rule-based column filter that would also take my importance table as an input. Any insight?
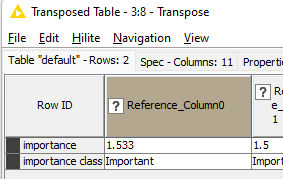
I’ve made a manual example workflow for you, with a couple of column trying to replicate your use case. The key steps here are Transpose of your reference/importance table and the a Reference Column Filter Node with both table.
Please download the workflow so you can follow the steps:
Tranposing the importance table, will create a table with the Row IDs as columns, so you can use those columns as reference and then filter the original table. I’ve filtered the importance class, because the transpose will create a row with the importance values and with the importance class, and that is mixing the types, you can see the ? there.