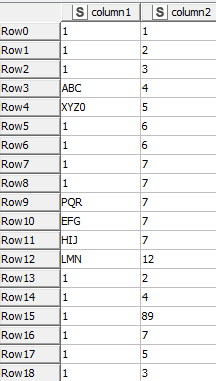
Hello I have the following data set. which has “1” or some other string/int or a mix in the column 1.
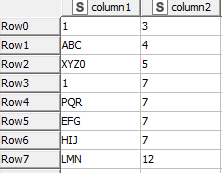
The required output is as below.
The logic behind the two datasets is that, I need to filter out the column 1 rows, which does not have “1” in it however, need to keep just the row above the filtered out row which will contain “1”
Is there any way I can do this.
I have attached the two datasets in the post for the convenience.
This is exactly how I like questions to be posed on the forum.
This is doable in Knime.
If you receive no help within the next 24 hours (which I doubt), I’ll spare some time to solve it for you. But I’m sure other contributors will come and do it fast.
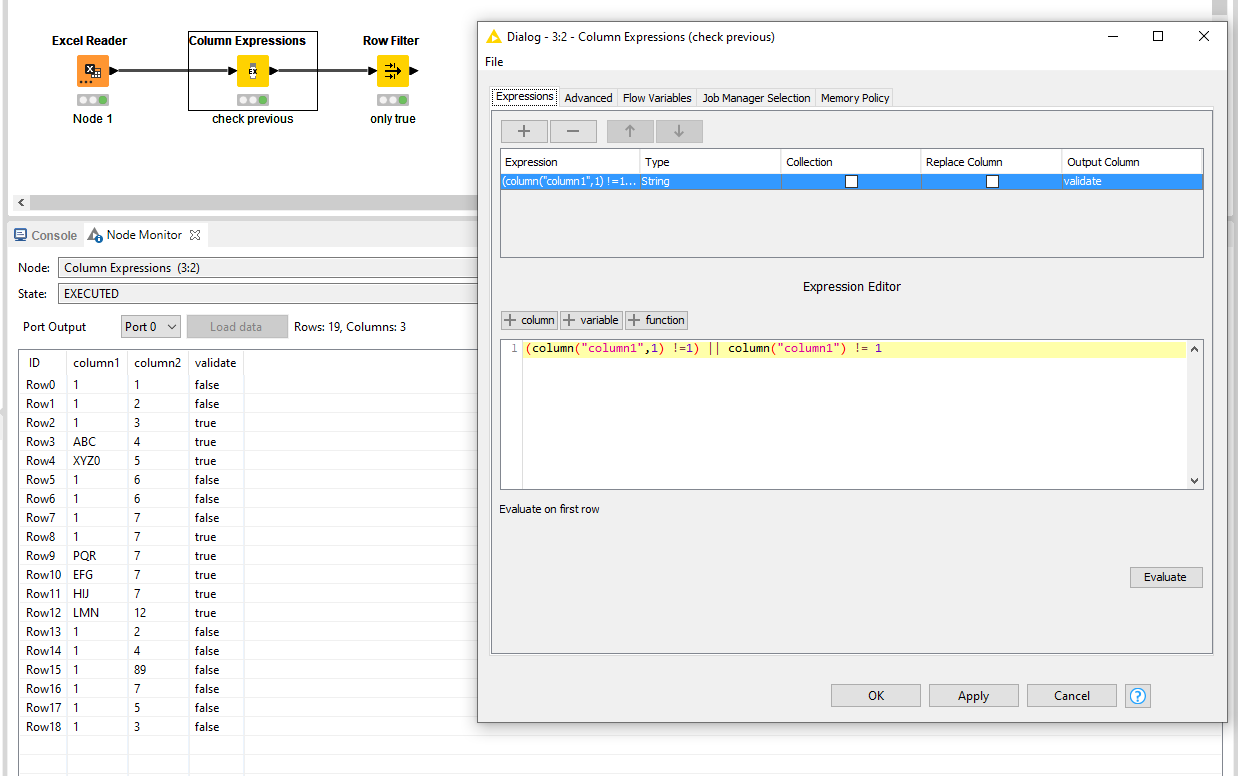
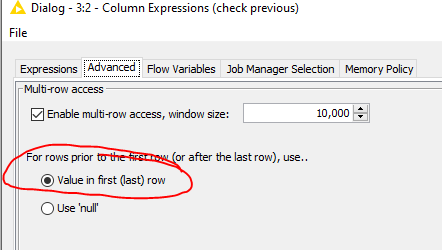
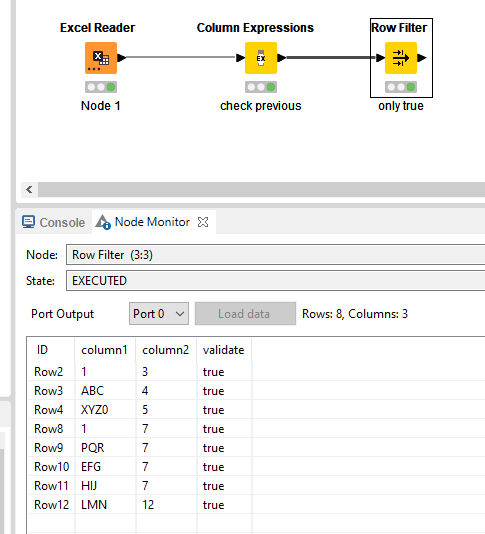
It checks whether the previous column is not equals to 1 and checks if the current column is not equal to one. In the Column Expression under the Advanced tab, ensure that you have the checkbox selected, a sufficient windows size defined and the option Value in first (last) row selected.
If you subsequently filter for true results with a row filter, you’ll get your desired output.