Newbie question on my first workflow! I’ve spent hours searching the forum and other online resources but to no avail!
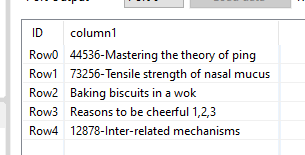
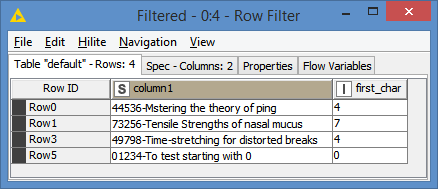
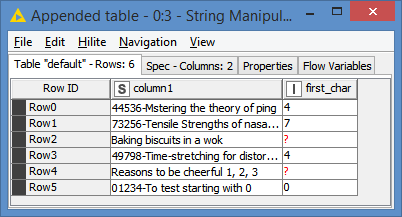
I have a data column that is a string with items of varying lengths, some of which begin with numerical characters (which I want to keep) and some alpha characters (which I don’t) - see example below:

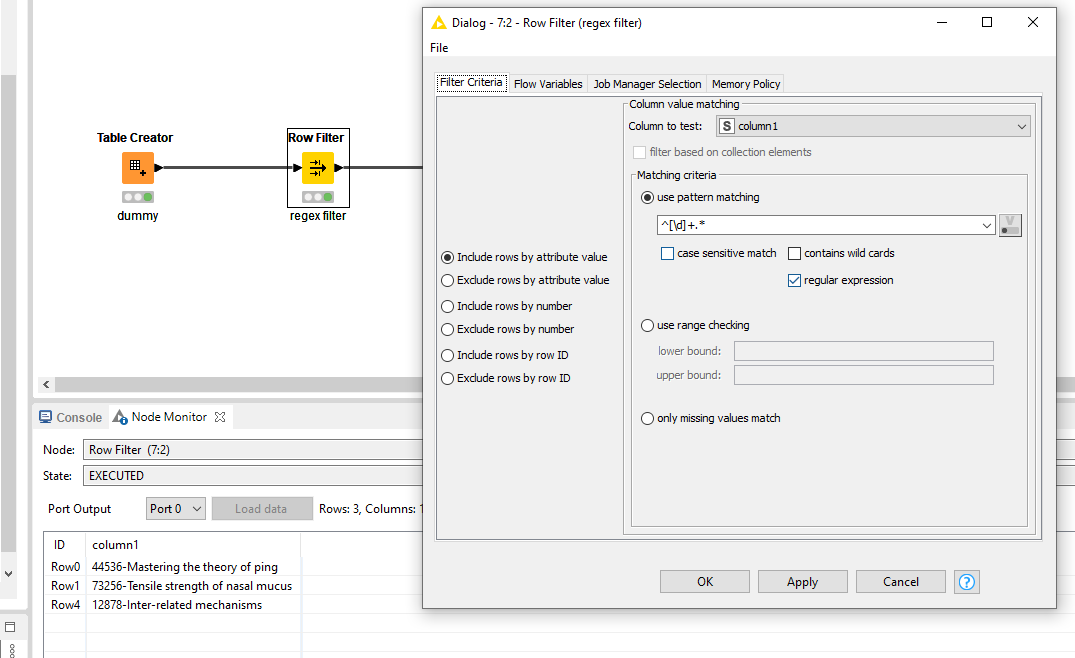
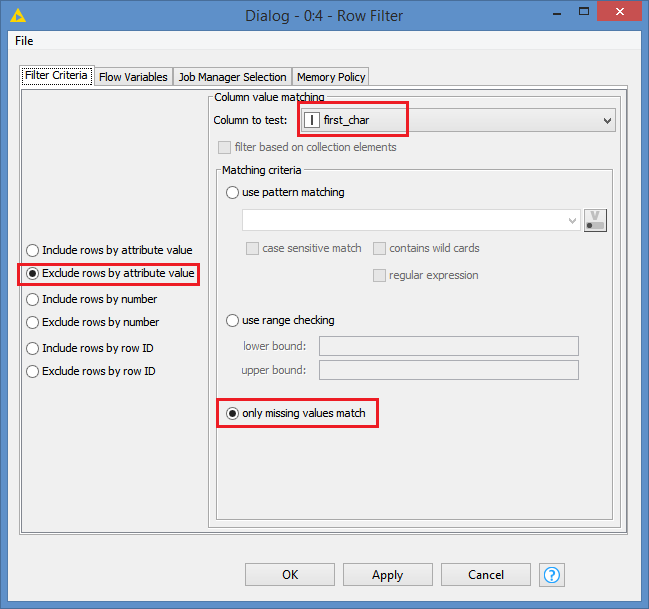
How do I do this? I’ve tried a Row Filter node with some regex, which I’m not that familiar with so am failing to get the syntax or the node settings right:
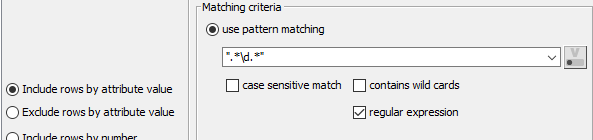
I’ve also tried with the Rule Based Filter node using the following (to select only records which start with a number) - $Activity code$ MATCHES “.([0-9]).” => TRUE but this returns an empty table!
Is there an easy way to do this or do I just need to learn regex (not ideal as the workflow needs to be shared with other non-IT types, so I want to keep it reasonably simple, even if more long-winded!)
*Bonus query - *
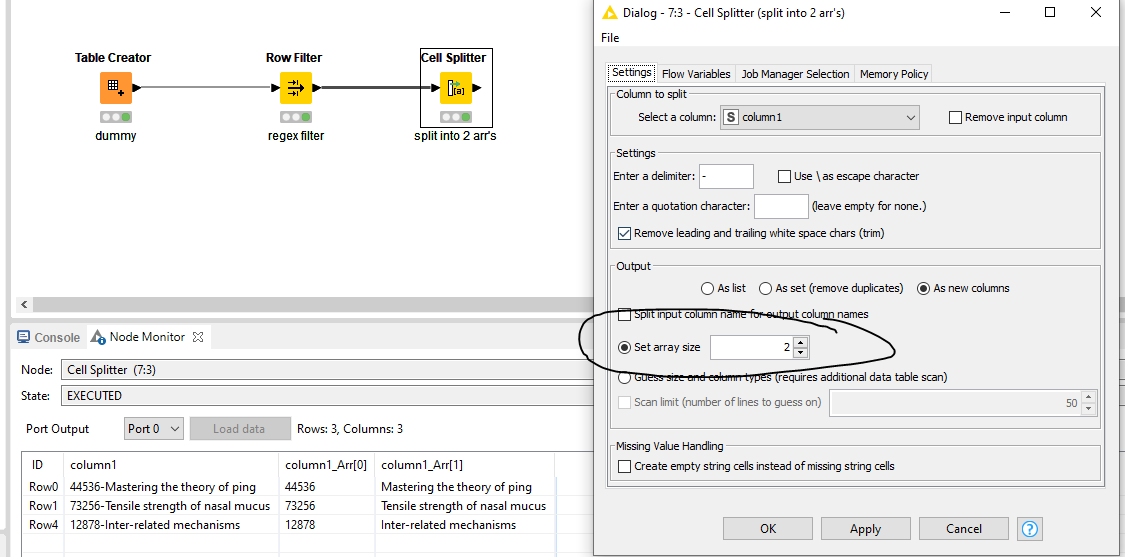
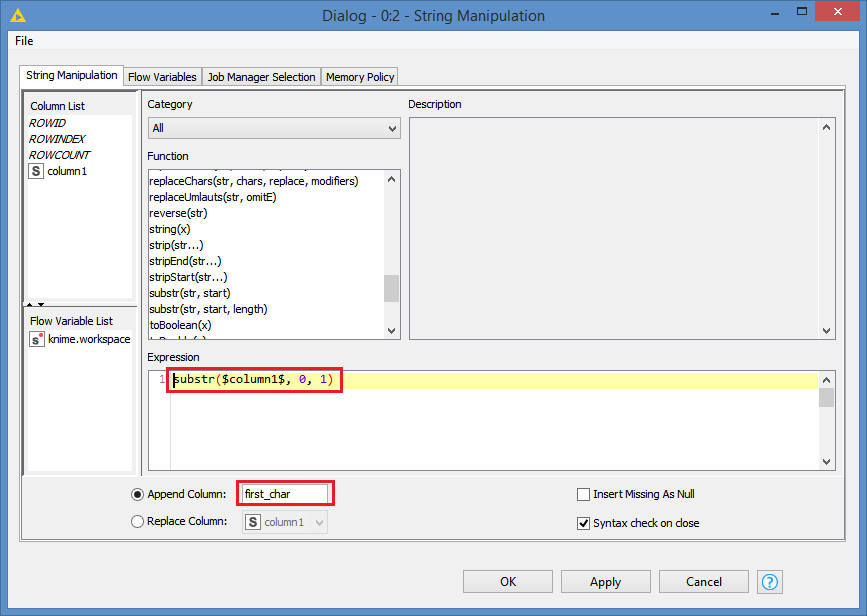
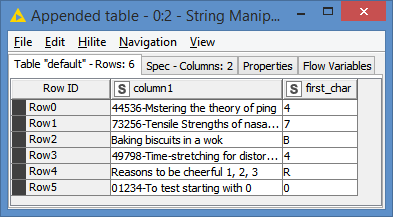
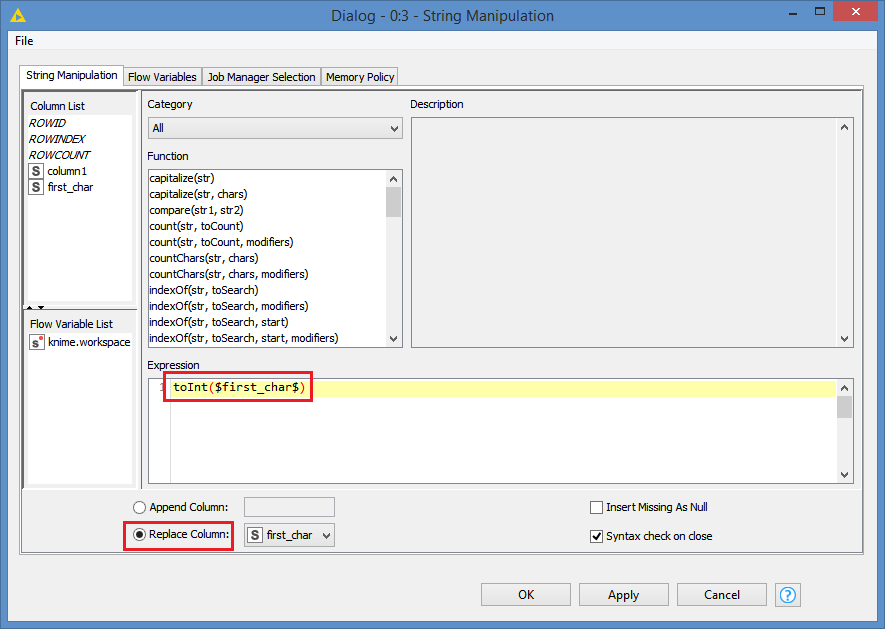
I then need to split the remaining number first cells into two using the ‘-’ delimiter, but some strings have a second ‘-’ delimiter, for instance: “12878-Inter-related mechanisms”. I want to split into “12878” and “Inter-related mechanisms”. I’m using a String Manipulation node to find the first delimiter location and split a substring as follows:
substr($Activity code$,indexOfChars($Activity code$,“-”)) which does seem to work but is there a better way?
Thanks in advance!!