I’m facing a challenge that I hoped shouldn’t be a challenge at all
I have two input tables:
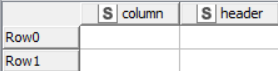
The first (sample) table with header row and data below. Header might contain ‘ #’ string or not
The second (sample) table with reference header row. No ‘ #’ string here
I would like to filter out some columns and keep those columns from 1st table which have headers ‘similar’ to reference header row, like below
Of course, the full list of columns is longer then in the above example, and the set of reference columns is dynamic (it changes each time the workflow is executed).
How to do this?
I have tried several ways, but nothing that works for me so far.
Hi @HansS
Yes, I have tried Reference Column Filter.
The think is that Reference Column Filter (and Reference Row Filter, too) finds exact matches. Thus, it matches ‘column’ columns, but doesn’t match ‘header’ columns. In case of ‘header’ the real match refers to ‘header*’ with the wildcard and I don’t know how to apply wildcard in any reference node.
Thank you,
Kaz
you are right. Reference filters are for exact matching. What you can do is prepare regular expression based on your column names and feed it as flow variable to Column Filter node where you can filter based on Wildcard/Regex Selection.
I have executed your workflow on sample data and it worked like a charm.
Then, I have used real data and the workflow still worked, however I have discovered that variety of column names is bigger then expected. There are the following reference headers in your workflow:
column
header
abc
and regular expressions refer to ‘column*’, ‘header*’ and ‘abc*’.
Unfortunately, there are columns named ‘column’, columns named ‘column #…’, and columns named ‘column something’. The expected matches are ‘column’ and ‘column #*’, while ‘column something’ should be omitted.
So, how to modify your workflow to get regular expressions that identify: column or column #* where * stands for wildcard, header or header #* where * stands for wildcard, abc or abc #* where * stands for wildcard?
a bit too much as I’m not good at explaining regular expressions
In short it does what you are looking for. List of words in OR expression followed by either space and # char or end of string/line ($). You can check this web page for playing with and learning regular expressions: