The retrieved webpage is larger than 2000 rows (can be retrieved via GET or HTML retriever) and the data table is also after 2K rows thus the proper XPath was difficult but with the help of another tool, it was resolved
Couldn’t find an option to concatenate a string at the end of another string in String manipulation node, as the URL of data table is with the suffix “-earnings”
Attached workflow was able to retrieve only header of the table but not the complete data, I think XPath is not correct
Can anyone please have a look at the attached workflow and suggest what is wrong. I spent some time trying to use different XPath options but couldn’t manage to retrieve the full data table.
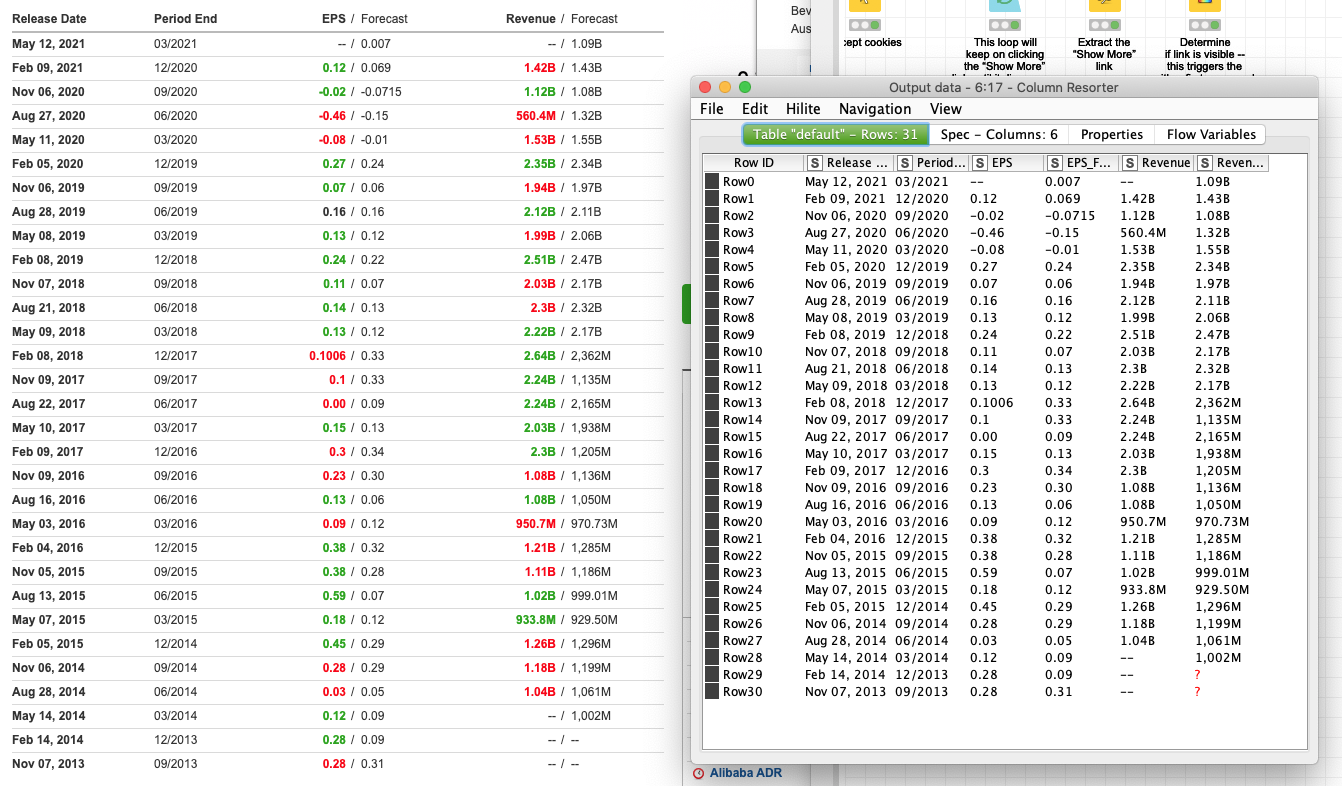
this is a super-perfect use case for the Table Extractor from the Selenium Nodes. The following workflow will expand the table until it provides no further data through a loop, and then simply convert the HTML into a KNIME table. Add some text cleanup using Palladian’s Regex Extractor, and you’ll get a table like this:
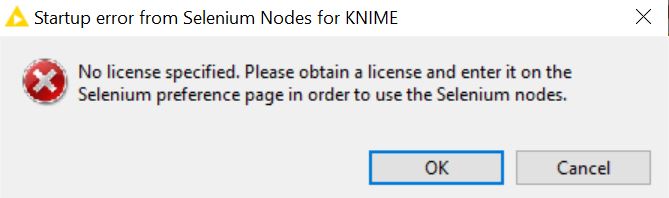
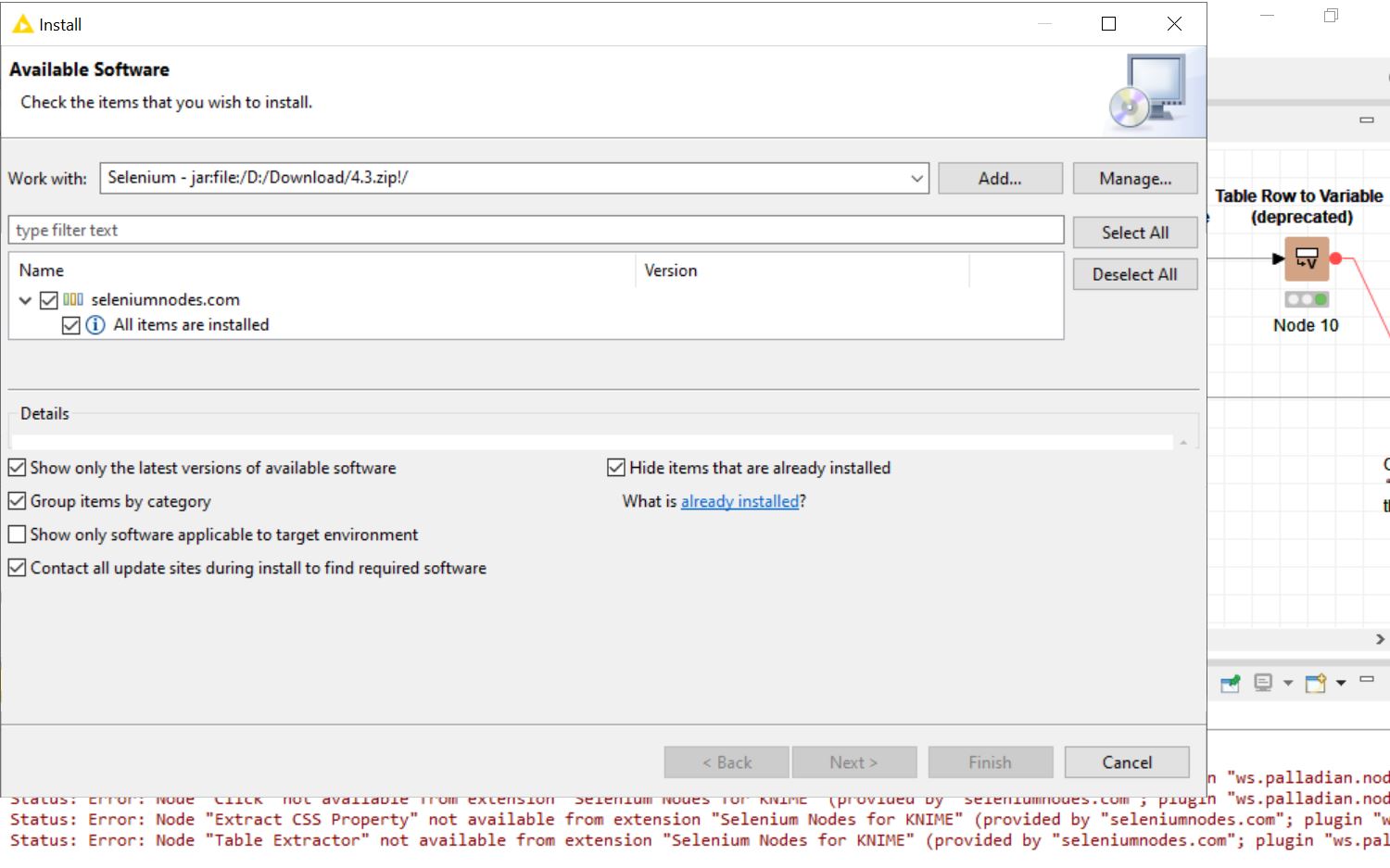
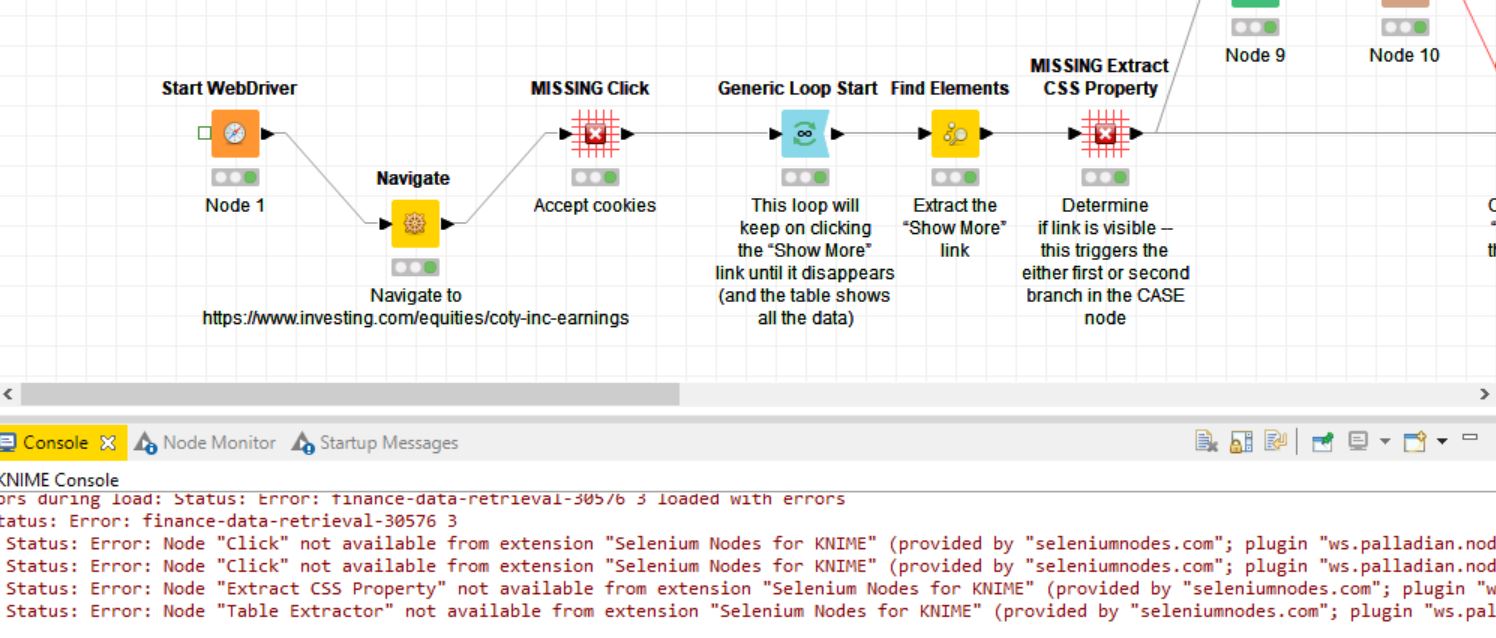
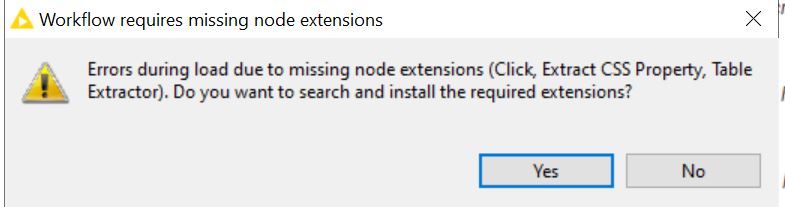
Sorry for the late reply. I tried your proposed approach but unfortunately it was not reproducible as I encountered different issues (i.e. Licensing, missing nodes etc). Please see attached screenshots.