Hello,
I have a table with many records and I’m looking for a solution for the following case:
in the first column are short sentences,
in the second column is a different word,
It should be checked if this word appears in the sentence of the first column, if so, “TRUE” should be displayed in a third column.
Does somebody has any idea?
There is a way to do this using quoting patterns in regular expressions. See the attached workflow and let me know if it’s helpful.
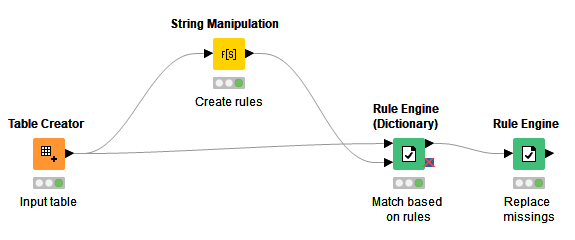

StringMatchingwithRegExRulesExample.knwf (11.2 KB)
Full disclosure: this is not entirely my own solution - I adapted the RegEx from https://stackoverflow.com/questions/39876564/filtering-data-from-one-table-based-on-terms-in-second-table-knime. Also, apologies for my weak approximation of your German text with my English keyboard. 
2 Likes
Hi Scott,
Thank you for your answer.
The solution sounds good and simple, unfortunately, I have not yet implemented the workflow, I have 1,230,500 records and the “Rule Engine Dictionary” node is stuck.
By the way, the text in the data example is not that important, of course I could have used English words as well 
Do you have an idea to handle this amount of data?
First, I would try with a small subset of your data, to make sure that it’s working at all. Assuming it works, I would then see if you have enough memory dedicated to KNIME in your knime.ini file (as discussed here: https://www.knime.com/faq#q4_2)
It’s also possible I have suggested a solution that just doesn’t scale well; I welcome input from our other forumers if that’s the case
The workflow works with some of the data, but it takes too long for only 9000 records. I will check the memory. Thanks
Edit: “This parameter can be changed for KNIME by appending the following option to the knime.ini file:
-Dknime.database.fetchsize=1000” don´t work better
Have you thought about using Streaming for this task? You would always just send a chunk of data through the node. Not sure what that would mean for 1,x million lines, but it might be worth a try. I am wondering if there can be any simple solution than Regex. Will maybe think about that too.
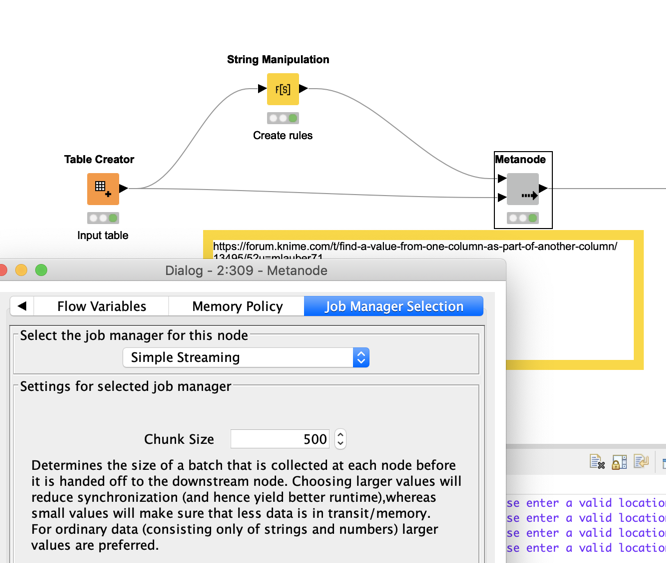
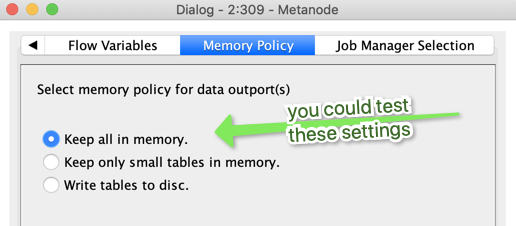
And you can check the performances tips, see how large you whole dataset is and think about forcing the nodes to keep everything in memory. That might speed up the process also.
StringMatchingwithRegExRulesExample.knwf (16.9 KB)
Hi, thank you very much, this node is perfect
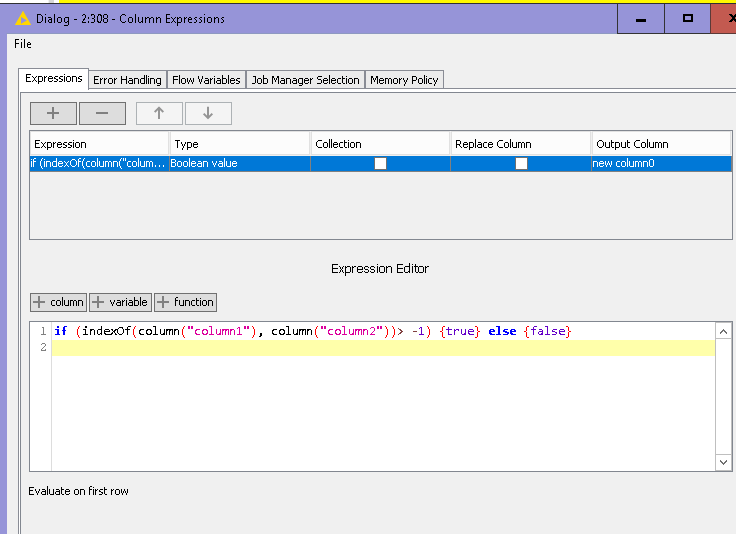
The Column Expressions node saves the day again! I can’t believe I forgot about it.
@nicole, if @izaychik63 's suggestion is working for you, could you please mark it as the solution for future users to search? Thanks!
1 Like
Hi,
same problem like Scotts idea, the node is suck.
The best and fastest solution is the node “Column Expressions”.
Many thanks.
1 Like
Hi Scott,
thanks for the hint, the button I had overlooked.
Hi @izaychik63
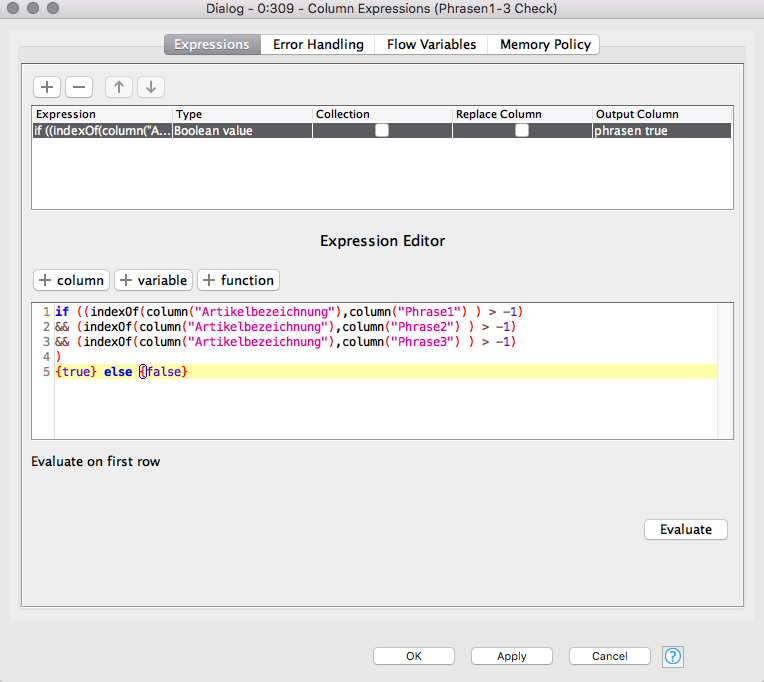
I have another question, how can I include two more columns in the test?
So if “Phrase1” AND “Phrase2” AND “Phrase3” are included in the “Artikelbschreibung” column, then = true, else = false?
Thank you for your patience

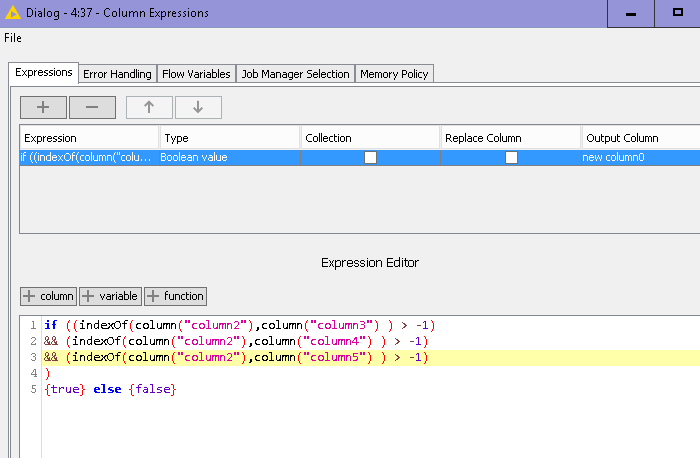
@izaychik63, thanks, but the end result contains only a few “true” lines, that is not right.
Do you have any idea?
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.