I have a free form text data field that also includes account numbers. The account number is six numeric digits that seem to always start with 0. Sometimes it is in the front, sometimes it is somewhere in the middle, and sometimes it is near the end.
A field could look like any of the following:
“012345 company A deal 34”
“company A 012345 deal 34”
“company A deal 34 of 012345”
Is there a way to use a node that will scan this free form field and return those six digits? The actual free form fields are far more complicated than what I showed, just trying to illustrate what I meant by where the acct # could be.
Hi,
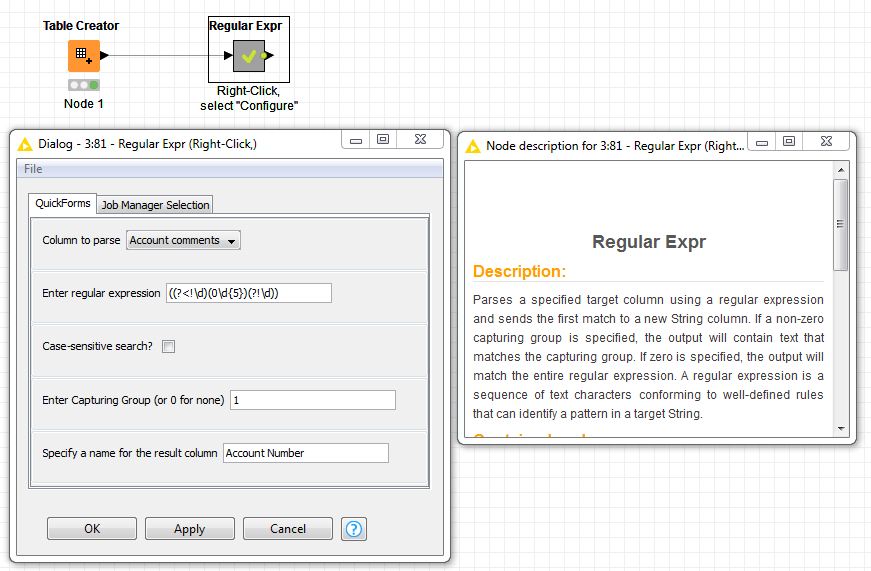
This can be done using a regular expression (or regex). A regular expression is a sequence of characters that define a text search pattern. The regex for a six digit number is “(\d{6})” and the regex for a six digit number starting with zero is “(0\d{5})”. To exclude numbers with more digits, the regex is “((?<!\d)(0\d{5})(?!\d))”. This says find numbers starting with zero and containing six digits that are not directly preceded or succeeded by a digit.
Now the task is to find a node that will search a String column using a regex and return the first match. I haven’t been able to find such a node (though I haven’t searched exhaustively of late). However some time ago I did create a metanode that performs this task. See the attached workflow.
Hope this helps,
-Don find account nums by regex.knwf (16.5 KB)
I figured I should let you know that this worked perfectly on my data. Thanks for including the difference between 0/d{5} and /d{6}; turns out there were a few that did not start with 0.
I’ve been meaning to learn how to use regex for a while now, I think you spurred me to work further with them.
I’m glad it worked for you. This is a metanode I’ve used on several occasions. Perhaps if there’s enough interest, KNIME can make this a new function in the String Manipulation and/or Column Expression nodes?
check Metanode you created (which is nice btw) and was wondering about your idea “making this a new function in the String Manipulation and/or Column Expression nodes”. Can you explain it a bit more detailed?
The String Manipulation node already contains the function regexMatcher(str,regex), but that returns a boolean value if the whole string matches the given regular expression.
What we want here is to return the first substring in the text that matches a specified capturing group of a regular expression. This allows us to flexibly find substrings (like account numbers or patent numbers, etc) that match given patterns.
The use of capturing groups increases flexibility by also allowing us to optionally specify surrounding text patterns. This is useful when we’re interested in say, the last 4 digits of a social security number
possible function signatures:
findMatch(text, regex, capturingGroup)
findMatch(text, regex, capturingGroup, caseSensitive)
description:
Returns the first substring of the text that matches the specified capturing group of the regular expression. Capturing groups are specified using parentheses. The first parenthesis denotes capturing group 1.
technical notes: In my regex metanode I allow the user to specify whether the regex is case-sensitive, so the second function signature above adds a corresponding parameter.
However, another way to specify case-insensitivity is adding the prefix “(?)” to the regular expression itself. So, technically the second function is not required, it just makes it slightly easier.
In my metanode, if case-sensitive check box is checked, the java code looks like:
Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
But I haven’t tested to see whether this flag overrides the (?) prefix if specified in the regex. The flag also may impose a slight performance penalty, hence the first function signature above allows avoiding this penalty.
Thanks
Don
P.S. I’m an intermediate regex user. Perhaps any advanced users have additional comments / ideas?
I see. Tnx for bringing details in. @armingrudd can you give us yours opinion? Have a feeling you were dealing with this kind of use cases in KNIME already. Is it with combination of regex functions or some other node?
The Metanode looks interesting. As an alternative approach, one can use this expression in the Column Expressions node:
if (regexMatcher(column("Account comments"), ".*(?<!\\d)0\\d{5}(?!\\d).*")) regexReplace(column("Account comments"), ".*?(?<!\\d)(0\\d{5})(?!\\d).*", "$1")
This gives us exactly the same result.
If the last match is needed then we can remove the first ? character in the regexReplace function: if (regexMatcher(column("Account comments"), ".*(?<!\\d)0\\d{5}(?!\\d).*")) regexReplace(column("Account comments"), ".*(?<!\\d)(0\\d{5})(?!\\d).*", "$1")
tnx @armingrudd. So it is a combination of functions. What do you think about adding this as a new function in the String Manipulation and/or Column Expression nodes?
The string manipulation can be used if we are sure all the rows contain the value we are looking for. The Matcher is used to return null in case there is no match, the Replacer alone will return the whole string in this case.
Thanks @armingrudd for the insightful analysis. You are correct in that it isn’t necessary to include the functions I propose since one could write an expression using the replace function. However when one is looking to find a pattern of characters one might not think of using the replace function (unless perhaps one is as experienced as yourself). It requires the user to think of bracketing the regex with .* and using “$1” as the replacement text (BTW perhaps support for backreferences in the replace parameter should be documented?).
The function I propose is a convenience function that makes the expression simpler and more intuitive:
findMatch(column(“Account comments”), “((?<!\d)(0\d{5})(?!\d))”, 1)
Does it warrant a new function? I think so, but I understand your position too.
Cheers,
Don