I think I could split the synonyms field and then use rule engine to check if the name appears in any of the synonym split columns, but then I am not sure how to actually remove. I also only want to check across rows, i.e. any duplicates which may appear in e.g. ID 1 or ID 4 should not be removed. Any ideas? I was also trying unpivoting, but then not sure what to do next.
Hi @zhuma,
Maybe you can simply use a String Manipulation node? You could first replace any occurrence of the name in the synonym with an empty string and then clean up the separators. For only replacing, that would be: replace($SYNONYMS$, $NAME$, ""). Keep in mind, though: this will mess up potential synonyms that contain the name, like name=abc, synonym=abcdef, output=def. This can be alleviated by replacing only when the name is preceded or followed by a space:
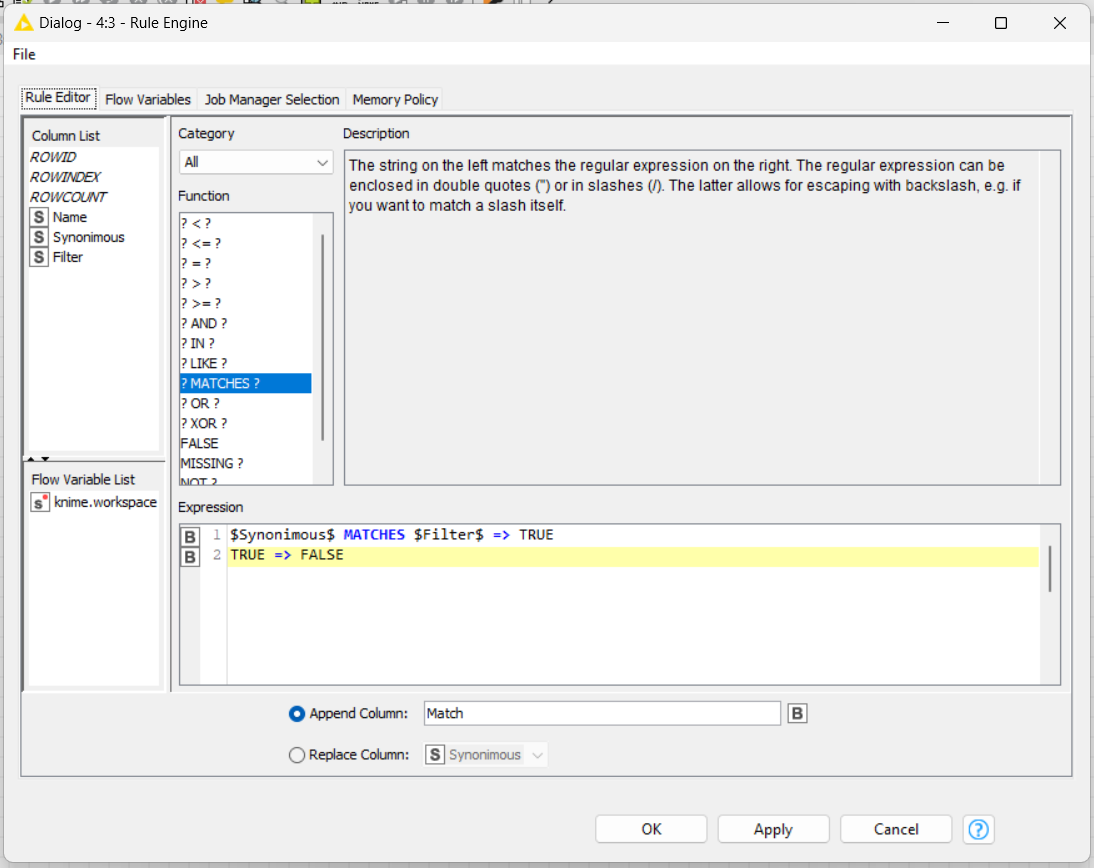
This does not deal with the case where the synonym is just the name. For that you can add a Rule Engine node and check. Now to clean up, you can use the regexReplace function:
This replaces any $$ with surrounding spaces in the beginning or end of the result, and any pattern where $$ appears twice, separated by spaces.
Attached you find a screenshot with my results using that expression.
Kind regards,
Alexander