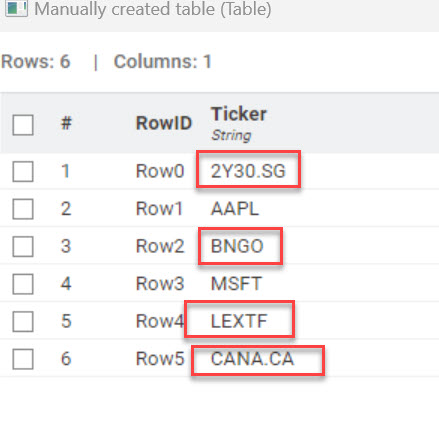
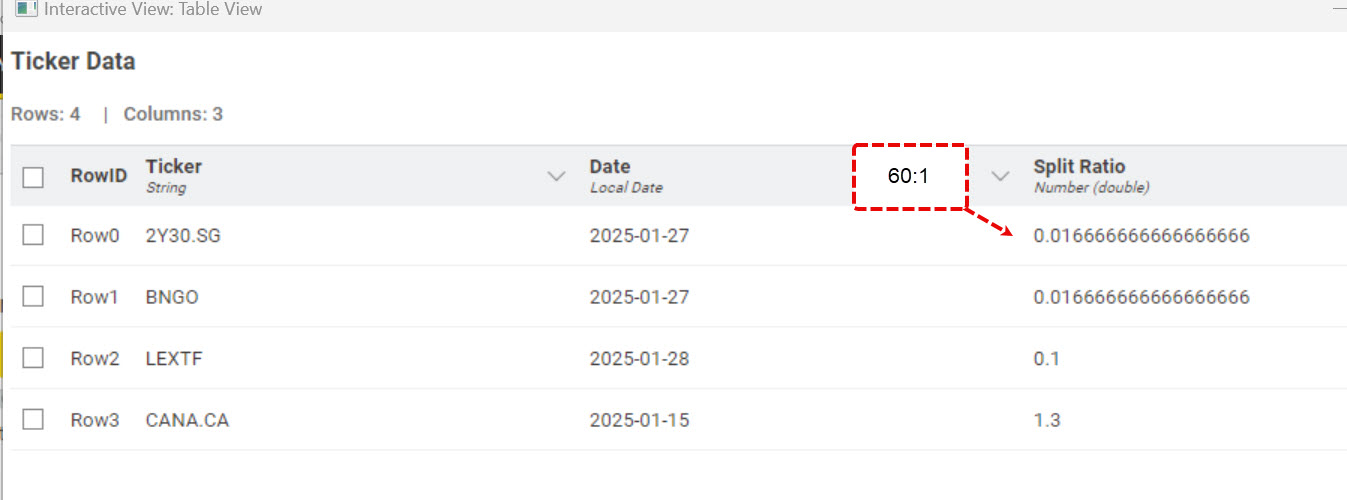
I think there are two issues at play - one minor and probably an oversight and one bigger one…
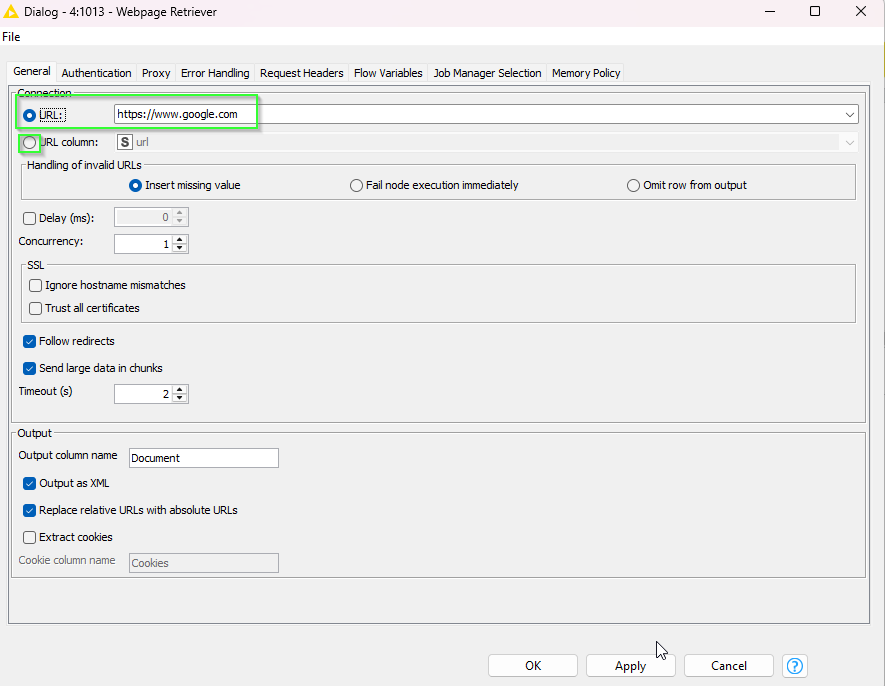
The small one: As far as I can tell from your workflow you are right now getting google.com homepage as response - you may want to select your URL column rather than having the default google.com address scraped
That said, it looks like yahoo does not like to be pinged this way - the node responds with 503 error.
My gut feeling is that you may have to opt for using the KNIME Web Interaction Extension to have KNIME open the website in a browser and then grab the data. There was a just KNIME it challenge to extract economic use from yahoo finance using exactly this extension.
Here’s the solution thread with plenty of options to pick from to see how it can work:
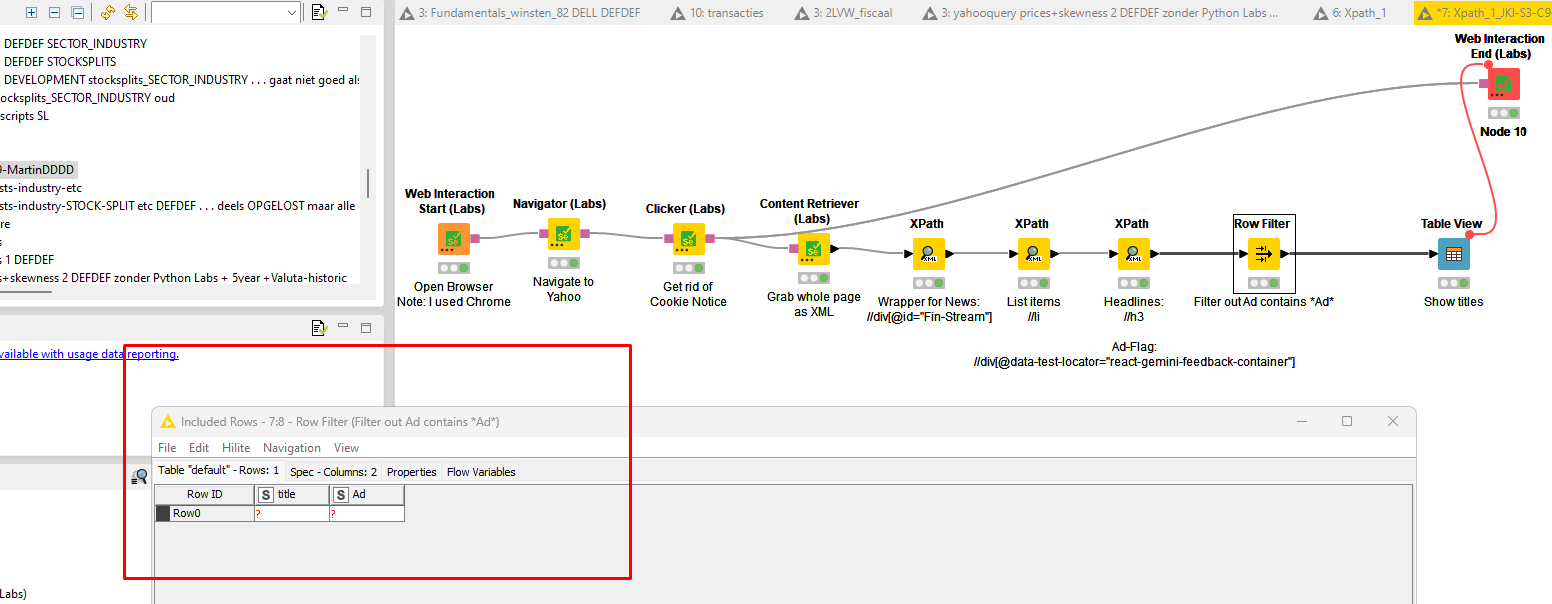
That produces the following error . . . ERROR Navigator (Labs) 5:2 Execute failed: HTTPConnectionPool(host=‘localhost’, port=30459): Max retries exceeded with url: /session/a72344c9fef2b061b15aa84e3c85a12f/url (Caused by NewConnectionError(‘<urllib3.connection.HTTPConnection object at 0x0000023659746AA0>: Failed to establish a new connection: [WinError 10061] No connection could be made because the target machine actively refused it’))
Strange because the mentioned URL is an existing page. An also tried “Refresh”.
Any idea why it produces this error?
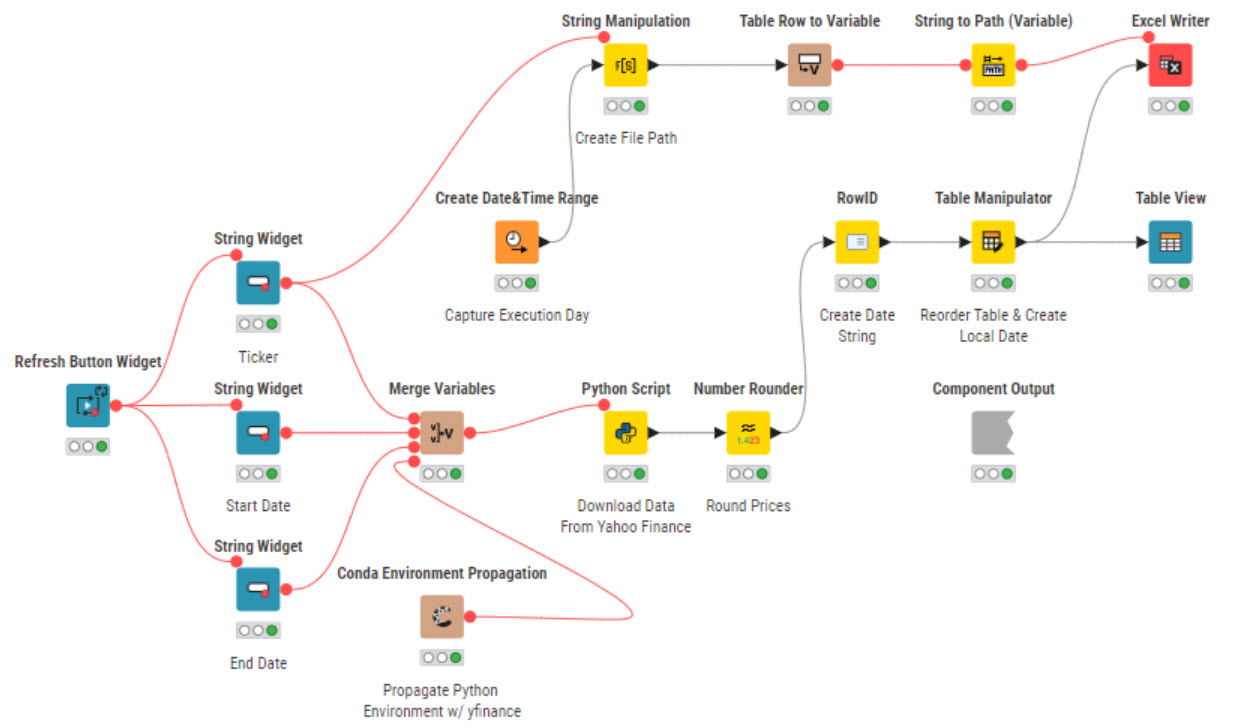
Take a look at this. It pulls single ticker data but can be modified to pull other data.
I’ve modified the original to include conda propagation for the required Python environment as well as writing an output. You’ll need to change the location of the Excel Writer in the String Manipulation node.
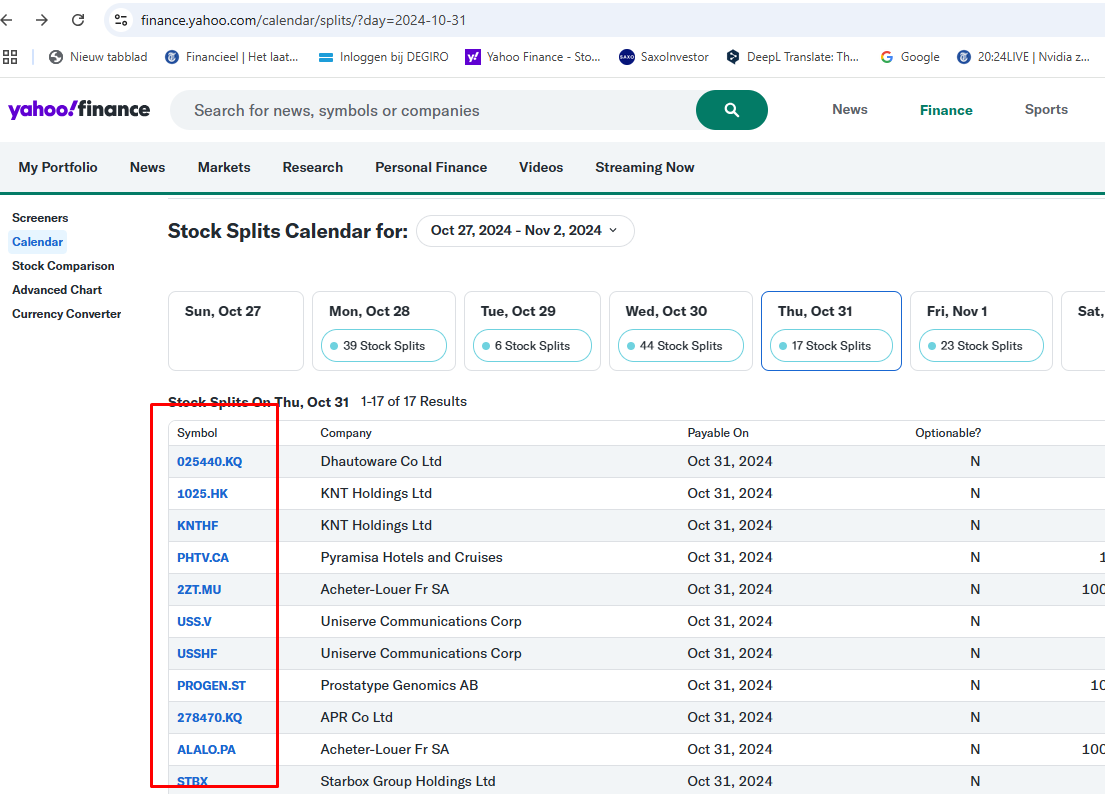
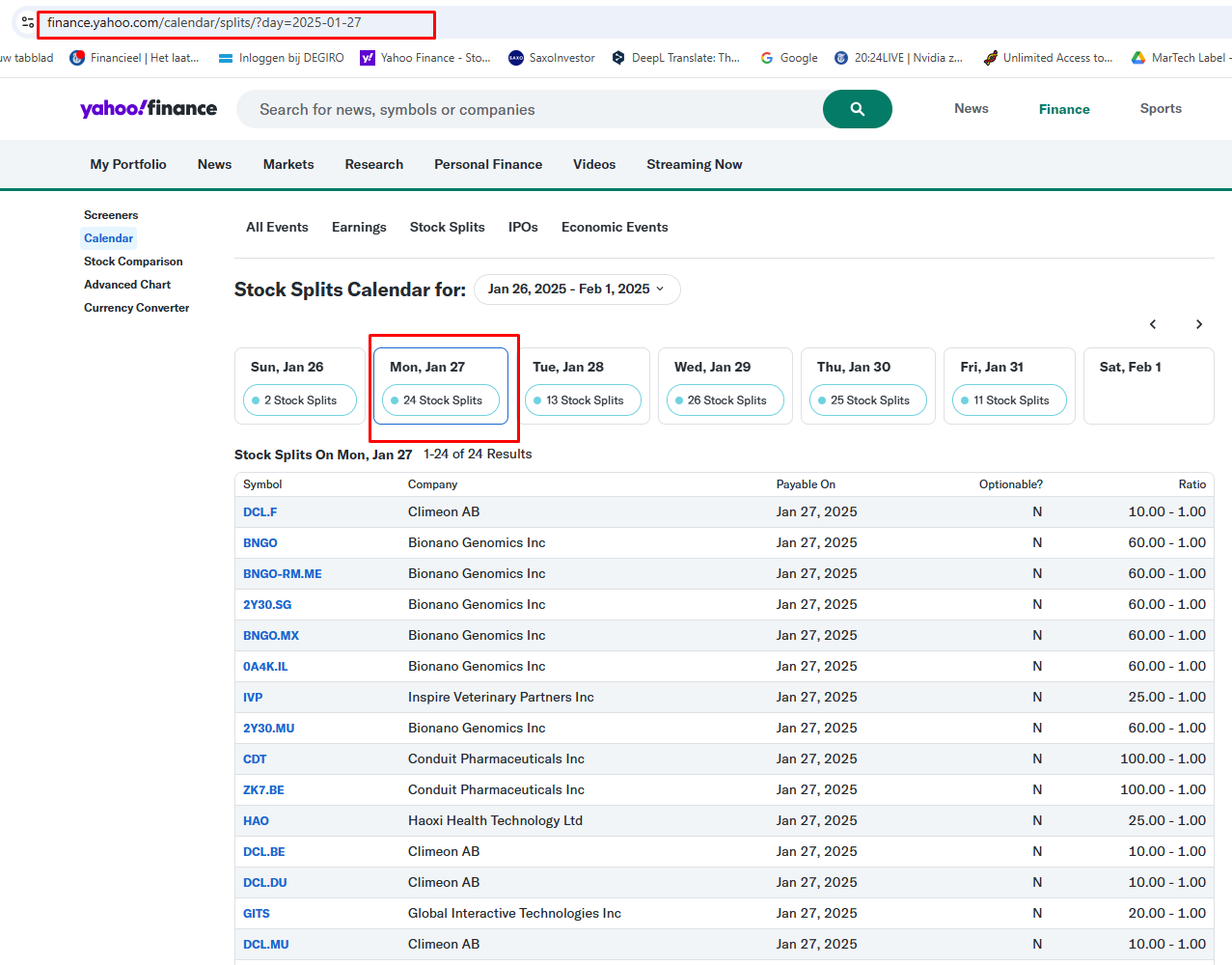
I carry out this check every month. So download the finance.yahoo split pages for every day of a specific month, e.g.:
…calendar/splits/?day=2025-01-01
…calendar/splits/?day=2025-01-02
…
…calendar/splits/?day=2025-01-31
Later on in the KNIME flow I check for all the funds in my portfolio if there was a stock split. But that’s not relevant my actual problem
Until recently the flow worked fine with Webpage Retriever and Xpath.
Attatched the relevant part of my workflow Xpath_1_extended_example.knwf (102.6 KB)
I suppose something changed at Finance.Yahoo but I don’t know what.
So my problem . . . how to download the tables for every day. See screenshot.
thnx for your latest contribution . . . VERY VERY GREAT . . . it gave me lot of insights and I learned a lot of it
Your approach is first to collect all the split data of the portfolio. Something you could not know is that my model is only interested in te most recent splits.
Further it takes a lot of running time to collect all the split data of my portfolio (about 800 funds and that takes 45+ minutes runtime). A well known problem that Python loops are very slow
With your contribution in mind I started tweaking . . . and developed the attached flow.
My approach is to collect all the split data over the e.g. last 60 days. Of course with a lot of reduncy (funds not in the portfolio). Later on in the flow (not attached because it is ordinary KNIME) I join all the split funds with my portfolio (joined by yahoo ticker).
The advantages of this approach are:
runtime about 15 seconds
less redundant split data
I only could came to this thanks your feedback . . . 1000x thnx
REMAINING QUESTION . . .
Has someone an idea why the HTTP Retriever node reads all the data on a certain page (abovementioned page_. And Webpage Retriever does not ???
. . . maybe this is a question to someone close to the KNIME development team