I am struggling with some logic which I can’t implement with Knime.
I have a list of customers in a table, which has 3 columns for different phone numbers as strings. Let’s say 1 row = 1 customer.
Now I suspect different rows contain the same phone number, but not necessarily in the same column. I wish to see which rows contain the same phone number.
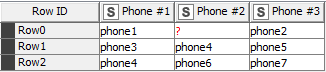
In this example:
I would like to extract rows 1 and 2, since both of them contain the value “phone4”.
Hi @PaulCombal , I think this should do the trick:
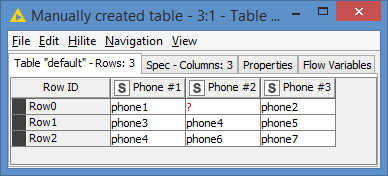
Input data (same as yours):
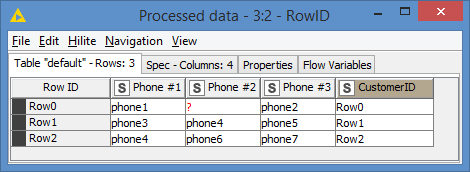
I added a “CustomerID” column using the RowID node, just so we can identify the rows in the results. This is optional, and I assume you would have some CustomerID column of your own:
I prefer presenting the results horizontally (from left to right) instead of vertically (one after the other), since you can clearly see which record matches with which record. Vertically, you would have to follow which lines are a set of match.
Of course if you want to do vertical results, there are different ways to add to the workflow.