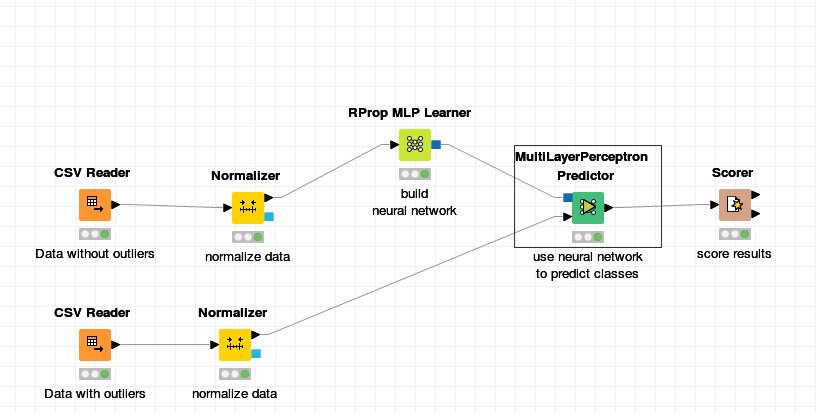
I want now to find these outliers. I used the class column cpu in the RProp MLP Learner and in the MuliLayerPerceptonPredictor also the cpu column but I got bad results.
So I’ not sure if it works this way.
In another series of test I tried with the above file but with an additional column for prediction (good/bad). This works very well.
So is my above method using the data without the prediciton class possible (using as prediction one parameter e.g. cpu)?
For unsupervised learning i looked already in DL4J but I’am at the early beginning
Thanks for any help.
Johannes
PS. I have to do this with neuronal networks so I can’t use other techniques/alogrithms
First: Why do you need to use a Neural Network? That sounds a little surprising to me.
Second: I guess with “I got bad results” you mean that the effectiveness of your trained model - the predictions are not as you hoped they would be. You dataset is most likely skewed. So you should not use accuracy as your measurement during training. You need to use a different measure, for example F1 score. However it seems that you cannot set this in the node. One workaround might be to multiply the outliers rows until you have as many outlier rows as normal rows. However, this is actually not a good approach for most datasets, and I feel a little ashamed even mentioning this. You might be lucky for your particular dataset though, but I would not trust the resulting model to be honest.
First of all, most people use the words “outlier detection” and “anomaly detection” as synonyms, but they are not. Outlier detection is a type of anomaly detection: Outlier detection is about finding outliers/anomalies within a given dataset (training data). Novelty detection is the other type of anomaly detection. Here we have training dataset of which we know that the training data is normal. Now we see some new data that has not been part of the training data and we want to know whether is like the training data (and thus normal) or whether it is not (it is an anomaly in regard to the training data).
You see that novelty detection is kind-of-supervised, but with a single class: All the training data is labeled, but with the same label. The data for outlier detection on the other hand does not have labels, we want to give the labels afterwards, so it is unsupervised.
What every you do, at the end you will get a number that tells you how normal you data objects are and you will need a cut-off to decide when each data object should be considered normal or not. Do find a good cut-off you can either do this human-driven by deciding e.g. you want 95% of your data to be normal (kind-of-supervised), or you can do it data-driven, but then you need labels (supervised).
Before you get to the cut-off, in both cases (outlier or novelty detection) and with any method you could use, you will need to fit some model parameters. You can do this by three means: using statistical analysis (unsupervised, and can be difficult, lots of research has been done though), again using arbitrary rules in combination with the previously discussed human-driven cut-off (kind-of-supervised, but starting to get a little arbitrary), using labels (supervised).
So it is a little difficult to answer whether it is supervised or unsupervised and how much at which step. There are many methods, but it would be the first time I heard that using a feed-forward neural network is one of them - I am pretty sure there is some research about using neural network for anomaly detection, because there is research with neural network about everything , but it most likely is going to be a special one.
If you have outlier detection, clustering is one way: Use clustering and say that clusters with few objects are anomalies. However, to get a good, robust approach is not as simple as just using any old clustering method and be done with it. Another good algorithm to start with might be KNN. A good, very pragmatic introduction might http://scikit-learn.org/stable/modules/outlier_detection.html which introduces other methods.
first of all I want to thank you for this nice explanation.
I was a person who thought, that outlier/anomaly detection is the “same”
After reading your post its more clear to me.
My idea was to look at the examples given by Knime. There is an example (04_Analytics/14_Deep_Learning/01_DL4J/03_Network_Example_Of_A_Simple_MLP) which, looks for me, similar to my project.
Is this possible to do novelty detection in Knime with neuronal networks?
Can you tell me an example or a workflow or furhter reading?
I tested it with my workflow from above but maybe I miss something or doing something wrong. I used some trainingdata (about 1000 rows) with only “good” labels on the CSV-Reader at the top. In the second CSV-Reader I give some testdata where the “cpu value” is not normal (its the only attribute which is anormal at a time). So my hope was that choosing class column “label” in the Rprop MLP Learner i would get any plausible results. But this was not the case. So is my procedure completely wrong?
Doing it full supervised (labels good/bad) i got more plausible results (best ~90% accurancy). See the workflow below.
Training a MLP only with one class does not make much sense. In that case even the normal classification with two class labels will be better - as you confirmed with your experiments.
Of course you can do classification with labels “good” and “bad”. Then this is not anomaly detection in the mathematical sense, but it is classification.
There are three different concepts: A task, a methodik*, and a method. The task is the “business goal”, the methodik is the mathemathical goal (or more precise, a methodik is the collection of all ways of reaching a goal), a method is e.g. a MLP. Choosing the right methodik for your task is a non-trivial matter in some cases, as it is here. So you have to ask yourself whether you want to to novelty detection or outliert detection or classification (three different methodiks).
You can use classification if your training data covers the feature space of all possible anomalies. In other words (less precise), it contains all possible anomalies that you expect to encounter. If you get 90% accuracy on the test set it is possible that this is the case here. And you can use classification instead of novelty detection for your task.
By the way. I see you use a hyper parameter optimization loop, but you are only using one partitioning. You should use three sets (so, two partitioning nodes): train, validate and test. Or you use a train set e.g. with cross-validation, and a test set. You should read up on some Machine Learning basics on this regard: https://en.wikipedia.org/wiki/Training,_test,_and_validation_sets
–
*The word “methodik” does not really exist in English, I took it from German. I don’t think there is a real equivalent in English. Most publications just talk about “tasks”, but mean “methodik”. The reason is that in most publications the word “task” is not required, so nobody notices that a distinction is required .
M42 already covered a lot of information but I would like to add some to it.
The problem your are experiencing with the MLP is that you are trying to predict a numerical target variable with a classification model, which is almost never a good idea.
If you are required to use deep learning, I’d suggest to take a look at Autoencoders.
They are basically networks that learn to reduce their input to a relatively low dimensional vector from which they reconstruct the input again.
When used for outlier detection, one hopes that the autoencoder will have a large reconstruction error on those outliers (after training), while having a small reconstruction error on inliers. The reconstruction error is e.g. the euclidian distance between the input and the reconstruction.
Another note on normalization: If you use data dependent normalization (e.g. z-score) then it is important to use the same parameters for training and testing data. This can be achieved by normalizing the training data with the Normalizer node and then using the Normalizer (Apply) node for the testing data.
Very good aspect. I understood that he had kind of both - the label “good”/“bad” and the numeric CPU values and that he could kind of decide on how to approach. I am not sure on the details though.
Also good point. This should work, as long as the anomalous data is not within the embedded space - the manifold produced by the autoencoder. To check one needs labels again, I guess. It does have another advantage though: You can use it for both, outlier and novelty detection. Let’s hope the professor did not explicitly mean regular MLPs, as I understood - but checking the first question, there just “neural network” is mentioned.
Am I correct in assuming that you are from Germany? If this is the case is there a place where i can talk german to you? Maybe my problem would become more clear
Beside this, i try to outline the whole Project. The overall goal is to find anomalies in HPC-Jobs. So i got data from a lot of HPC-Jobs containing the following parameters (e.g. the user who start the job, the start time of the job, the name of the application, and a the system parameters) written below:
By Anomaly is meant e.g. User A (userid 1002) is always using the application 3 or 5, always using between 10-20 cpus (in the example 15 respectively 19) and so on, so there is a kind of corridor inside the user can move and everything is ok (This corridor vary from user to user.). If he uses suddenly 50 Cpus and maybe application 4, then the neuronal net should detect this.
The best would be, if this could be unsupervised my Prof told me.
At the moment i have only data from “normal” jobs. As I learned from M42 it’s novelty detection.
Reading about the neuronal networks is the one thing, but I find it difficult to put this into practice in Knime.
Do someone know an example of a novelty detection neuronal network in Knime?
Thanks for the Link i read this
I used this only for passing different parameters to RPropLearner to test different hidden layer and nr of neurons in a neuronal network. I read a lot of valdiation but doing things in Knime is without previous knowledge to Knime and Machine Learning not so easy
Thanks for that hint, I’ll look into it, maybe i got better results with autoencoders.
He only said neuronal network. I used this because i thought, the example (04_Analytics/14_Deep_Learning/01_DL4J/03_Network_Example_Of_A_Simple_MLP) i found was similar to my problem.
Then autoencoders might be just what you are looking for, as they are as unsupervised as it gets.
Doing cross-validation is actually pretty simple, once you know where to look for it See this workflow for an example.
It’s also easily combinable with your parameter optimization (just make sure to have the optimization loop as the outer loop).
Well, technically autoencoders for this kind of data are usually also MLPs ;).
Two more things:
There are multiple id columns in your data, which should not be used for training as they are usually very descriptive for the training data but are completely useless for the testing data (except maybe for the case that e.g. the same users appear in both but even then it’s probably not a good idea).
The MLP Learner is quite old and we have invested quite some effort into expanding KNIMEs deep learning capabilities with the DL4J and Keras integrations. They are a bit harder to learn but I believe the flexibility they provide is worth the extra effort.
There are some new developments, which - I guess - are not MLPs anymore, like denoising, variational, contractive, deep and sparse autoencoders. But I am no expert on autoencoders. Hugo Larochelle has a couple of nice youtube lecture on them.
I don’t know how to write personal messages via the KNIME Forum system - maybe an admin can explain how to do it? I wouldn’t feel comfortable to post personal information here.
Thanks, for the example of cross-validation and the hint for autoencoders. I’ll already reading about them, hopeing they help me to reach my goals
I used only the userid column, but i see your point. How would you handle this problem) Because I need the connection between user (userid) and the system parameter, which should be placed within the allowed corridor for the user.
If I unterstand you correctly, you want your network to learn what behavior is tolerable for a user. This depends on certain variables like the amount of cpus used but it should not depend on the identity of the user. Therefore you need to exclude the Id from the training. During prediction, the model will only use the columns that were used for training, all other columns are ignored.
Yet another remark: You should invest some time in understanding what your variables mean and most importantly preprocess them accordingly. From what you wrote it sounds like application is a categorical variable but it is represented as number in your example. The learner will interpret it as a number which is semantically incorrect. For such categorical variables encoded as numbers, convert them to strings and use the One to Many node to get a one-hot representation.
Yes thats the idea behind my project.
But something its not clear to me. If I exclude the ID from the training, how would the network be able to build a connection between a user and the system parameters, which are possible for the user?
So lets say “User A” is allowed to use between 1 and 10 CPUs (I use CPU as an example, it could be any other parameter), “User B” is allowed to use between 20 and 30. And “User C” is maybe allowed to use CPUs between 15 and 25. How is the network able to recognize if the configuration is allowed for the user?
You are right. Behind the numbers are different applications. I switched the names to numbers because i wanted to adapt the data to the sample data given in Old Examples(2015 and before)/002_DataMining/002002_NeuralNetwork as good as possible and test it with my data. It wasn’t the best idea, as I learned.
As a next step i think i look first into novelty detection. I found some papers about this topic at the moment I read some of them. Is it possible in Knime to create a neural network which is able to do novelty detection?
This evening I played a litte bit around searching for “novelty detection” in Knime. I found the KNFST Learner/Novelty Scorer. Where I was able to produce some plausible results (for me). But it is not a neural network
It sounds like you have categories of users.
An ID sort of also categorizes your users but no model can generalize from that because each category contains only a single user.
Which brings me to another question: How much data do you have? Because for deep learning you usually need a lot of data to make it work properly.
There are actually multiple possible ways to build such an autoencoder in KNIME.
You can use either the H2O, DL4J or Keras integration but I believe H2O is best suited for you, as they do exactly what you want to do.
If you need more options to play around with, DL4J and Keras are the way to go but you will need a lot more knowledge of deep learning.
That is correct, the KNFST algorithm learns to map all instances of a class to a single point in a high dimensional space.
New datapoints are then mapped and the distance to the class representatives gives you an indication of its novelty.
It works pretty well if your dataset is rather small but it’s basically unusable for larger datasets because it will take ages to calculate.
However, you can use the Local Novelty Scorer in this case.
What would you suggest to solve these kind of problem? I have too little experience in ML at the moment.
I have access to different cluster with different quantity of jobs/users.
E.g. One cluster hast about 100+ users and 6000-7000 jobs a month. I 'am able to go back in the past to get more job data if necessary. If you think its too spare, I could use data from two or more cluster, so i think it would be enough. What do you mean?
So at the moment I’am looking into H20 hoping to get better result
this is by no means an easy task and I don’t know of any approaches using deep learning that go in this direction.
However, this is not my field of research and as M42 already pointed out, there is essentially some deep learning paper for any kind of problem. Still I would like to share some thoughts on the matter:
I see this problem as follows: You have different users and you have different behaviors.
A behavior is not necessary linked to a single user (although it might be in practice) because many users might behave the same (or a similar) way.
Your goal is to decide if a user’s behavior is acceptable for the respective user.
One way to model this in deep learning would be to create an embedding vector for all users (i.e. a relatively low dimensional space in which a user is represented by a unique vector) and learn a vector that describes a behavior. These two are then combined in order to decide if the behavior is acceptable for the given user.
If this really works, I guess there is some paper somewhere that already does something similar
Regarding your dataset: It might be enough but there is no way to tell unless you try it.
 , but it most likely is going to be a special one.
, but it most likely is going to be a special one.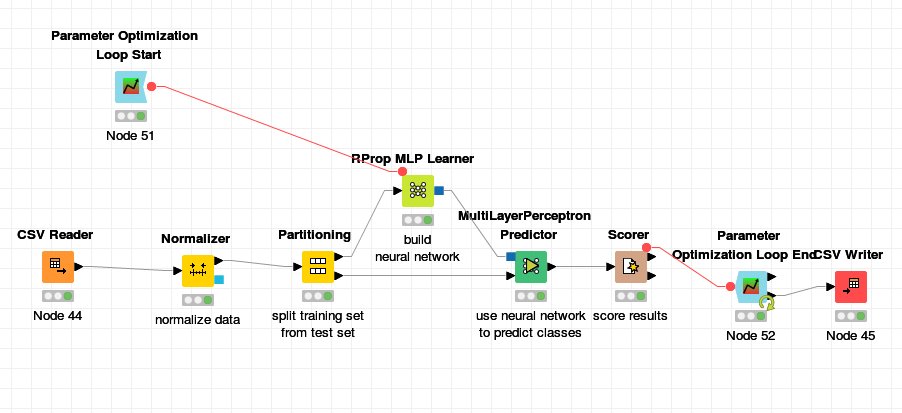
 .
.