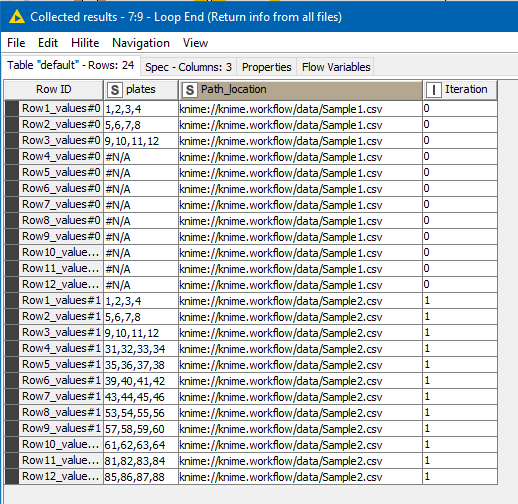
Hi @Daniel_Weikert, I had to go back and check 
Ok, so the regex I’ve used to find the term “plates” as a column heading, in the Rule Based Row Filter node was this:
(^|.*\t)plates(\t.*|$)
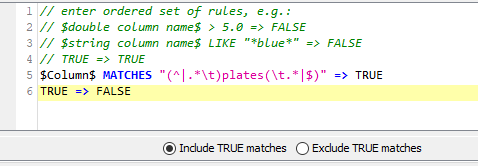
The quick and simple answer is that the pipe character “|” allows alternative matches. That may be all you need, but I’ll elaborate further as it may assist others. (btw, somebody else may have a different/better way of achieving this, and it’s (very) possible that my regex solution isn’t perfect, but it appears to work from the tests I’ve done with it, but if you/anybody spots something wrong please let me know!  )
)
My intention here was to find all rows where it contained the term “plates” but was a column heading in its own right. My first assertion was that column headings would be separated by tabs, so the word “plates” must be surrounded by tabs for it to be considered an actual heading and not just the string “plates” appearing in something like “contemplates” or “he threw some plates”
So initially I tested my regex as this:
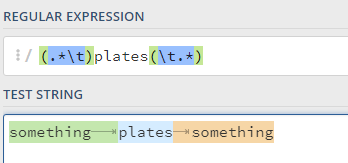
(.*\t)plates(\t.*)
and I included “capture group” brackets even though here they aren’t needed right now as it keeps it separated and it’s also easy to review the different parts of the “match” on a site like regex101.com.
This would happily find “plates” in a string with something followed by tab followed by plates followed by something
e.g. Using regex101 to demonstrate the example (and I’ve put a link to this example at the end if you want to give it a try), by using the capture groups, we can see different portions colour-coded when it makes the match:
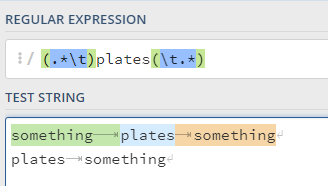
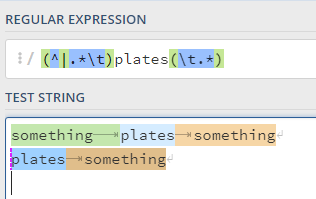
However, what if the word “plates” were the first column:
On regex101, we can see that this pattern won’t work:
In this case, we need to allow for the word “plates” being preceded by either "something and a tab, or by the start of line, and this is where the first pipe character comes into play.
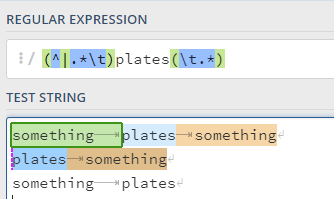
(^|.*\t)
This is now finding a match with either start of line or something and tab, but as you can see from the next example, it doesn’t find a line ending with plates
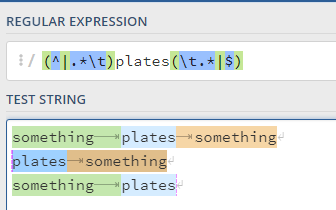
So, at the other end of the regex, I have done the same with “end of line” ($) and provided that as an alternative match using a further pipe:
and just for giggles, and completeness, here is my full test:
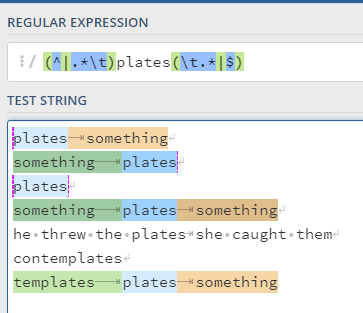
which appears to match all lines where “plates” is a column name in its own right.
Here’s a link to the above regex example. To enter tabs into regex101, I pasted the examples in from an editor, but you can also (on Windows) use Alt 009 (with the 009 entered on the numeric keypad)
I hope that helps!