Hi @abiasella , The attached workflow gives a possible mechanism for doing this. As I see it you have two complications. Namely that you know neither the row or the column containing the “plates” data.
I took your sample data and created two csv files in the data folder, with tab separated values. You may well have a workflow that connects to your google sheets, so you’d need to adapt it for that, but the body of the process would be the same.
Using the Line Reader as already suggested , it first of all uses regex in a Rule-based row filter to find a row containing the “plates” header. I’m assuming here that only one row per file will match this. If that’s not the case then a little additional thinking would be required on that.
Having found the row, it stores the row number in a variable and also calculates “row number + 13” to identify start and end rows in the current data file for the “plates” title and the 12 rows of data.
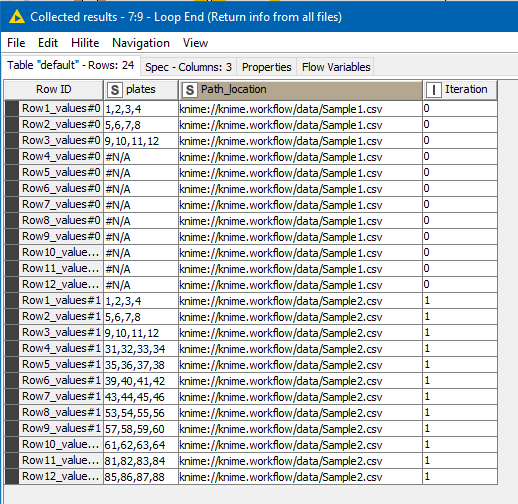
These variables are passed to a row filter to be used against the whole file and return just the rows of interest that can then be converted to columns and given the column names found in the first row of this subset of data.
It also records the file name for future use (if you need it) against each row.
After all files are processed, you end up with a data table containing the plates information from all input files, which you can then process in whatever way you require:
Find variable column and row position.knwf (52.0 KB)
During this exercise, I came upon an inconsistency in “row filter” which I have documented in red annotations on the flow. I documented it there because otherwise the way I derived the row numbers as variables to be passed to the row filter makes no sense! I should be passing 1 and 13, for example, but instead I have to pass 0 and 12 as the row numbers. This is different to the “usual” inconsistencies we find regarding 0 and 1 based row numbering, but I’ll document this elsewhere.