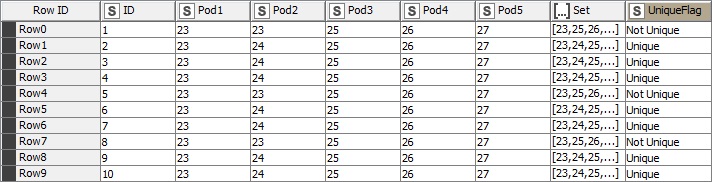
As you can see there is a duplicate on the second row (26 and 26) but the first row only contain unique values. I would now like to classify each row based on if all the column values for each row are unique or not, with this ideal output:
Could you please explain better, if every product number in a separate columns or your data presented of a strings where fields separated by dashes? Ideally you can provide a file with couple of lines of a real data.
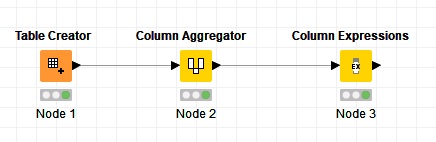
Use a “Column Aggregator” node and choose all the columns that you want to check and in the option tab choose “Set” as the aggregation method.
Then a “Column Expressions” node and use this expression:
if (column("Set").length < 5){ "Not Unique" } else "Unique"
I used 5 because in your example you have 5 prod columns but you can change the number.
Thanks for the advice on this and your solution worked perfectly. To continue in the workflow I would like to find a way to replace duplicate Pod1-5 values where the row indicates ‘Not Unique’ in the UniqueFlag, effectively trying to make all row have the flag ‘Unique’ as a final output. Conceptually, I have thought of something like this from a flow perspective:
Filter out all rows that are ‘Not Unique’
Create a reference table of some sort to list say 50 product ID that could we used as a replacement if the row is not unique
Lastly, and this is the tricky bit I think, somehow insert product id’s from the reference list where there is a duplicate value in the original table row (as indicted by the ‘UniqueFlag’).
Ideally I would like to create some sort of loop that replaces values until there are no more flagged ‘None Unique’ rows left
Any ideas on how I can implement this practically? Thanks for your continued help.