I have an issue where I need to find the difference between two date/times, grouped by a unique ID but within each unique ID, there is a ‘read’ process and a ‘write’ process.
How can I find the start and end of each read and write to calculate the time difference (that part I know how to do): I have a screenshot of an example and also attached a dummy data spreadsheet with sample data for testing
See this wf read_write_time.knwf (32.0 KB)
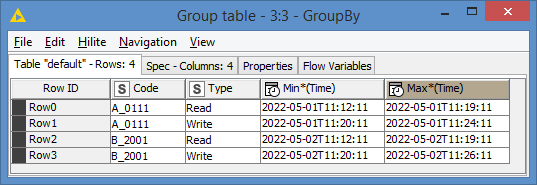
First identify the Read and Write records, than you can do a pivot within Code to extract the first and last timestap (be aware your data is sorted in the right order).
gr. Hans
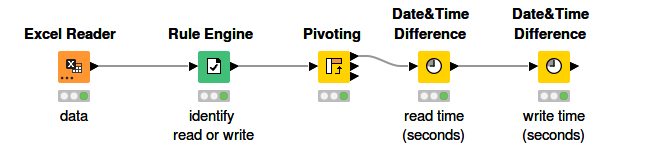
Hi @summer_le , since you know how to calculate difference, I will not look into that part, but only how to get start and end of time. One way to do this is as follows:
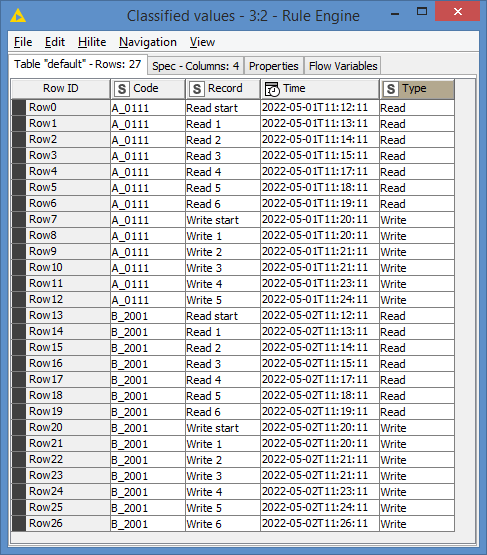
Identify which rows are reads and writes into a column. This can be done via Rule Engine:
$Record$ LIKE "Read*" => "Read"
$Record$ LIKE "Write*" => "Write"
And say I write this result to a new column called “Type”:
The answers above should give you the max and min values so I won’t elaborate further on the max/min of the dates, as they may well give you all you need.
One thing you mentioned though, was a method of determining the “read and write groupings”. Again the above solutions do provide grouping but what we don’t know is if your data could ever have more than one set of read/write groups per Code. If they can, then the solution of grouping might require some additional work to identify separately the multiple read or write groups within code.
In this case, you could draw from the following solution, oddly enough from within the past 24 hours:
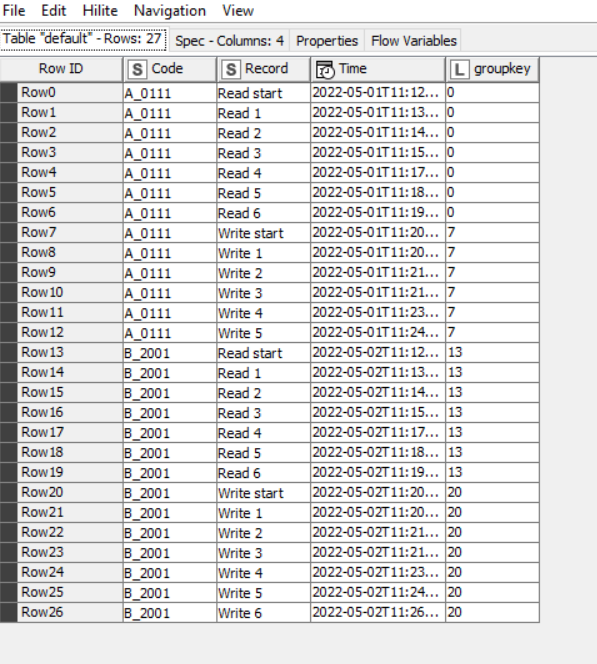
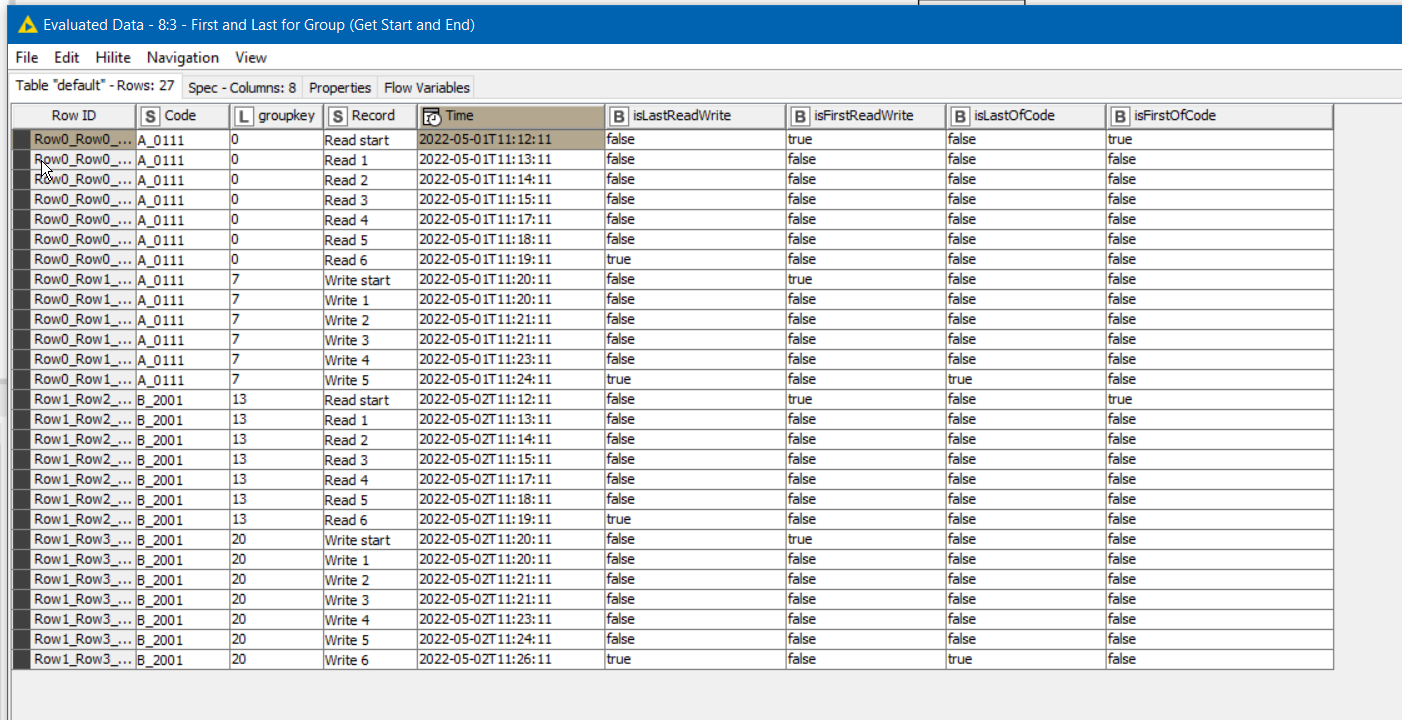
Taking from that idea, groups would be identified by containing the word “start” within the Record. Use a Rule Engine to place the ROWINDEX into a new column where ever the word “start” appears in Record. Follow this with a Missing Value node to copy down GroupKey from previous value where it is missing. (Ignore the annoying in-your-face “warning” on the Missing Value" node. Anybody know of a way to turn that off? )This then provides a unique “group key” for each read or write block.
After this, you can then group using that groupkey.
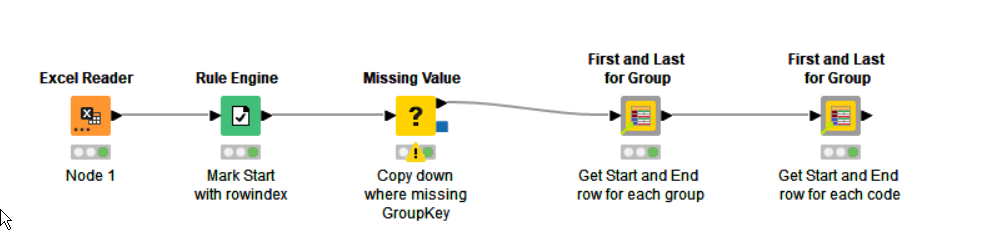
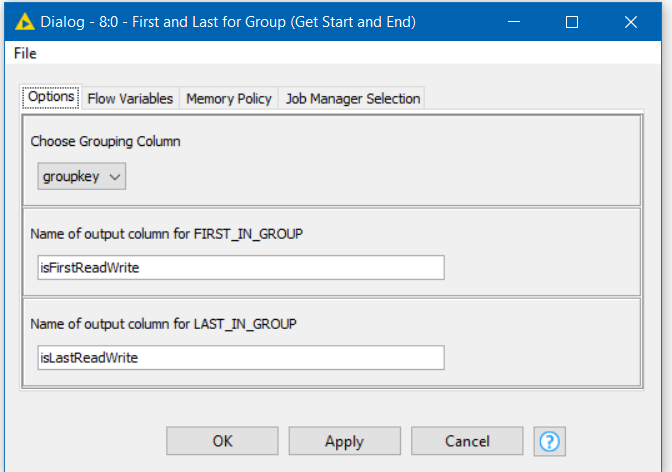
As an aside, some time back I also wrote a component “First and Last for Group” which can be used to indicate the first and last rows of a group identified by a grouping column such as this “groupkey”. It can occasionally be useful, and if you are wishing to perform other actions based on a row being first or last, it might be handy.
Hi @takbb, yes you are correct that the ‘read’ ‘write’ in some instances can be other words, sometimes very messy words/comments because there isn’t consistency in how the data is put in. Thank you so much everyone, I am going to try each of the solutions and see which one works best and I’ll mark the best solution.