Hi @summer_le,
The answers above should give you the max and min values so I won’t elaborate further on the max/min of the dates, as they may well give you all you need.
One thing you mentioned though, was a method of determining the “read and write groupings”. Again the above solutions do provide grouping but what we don’t know is if your data could ever have more than one set of read/write groups per Code. If they can, then the solution of grouping might require some additional work to identify separately the multiple read or write groups within code.
In this case, you could draw from the following solution, oddly enough from within the past 24 hours:
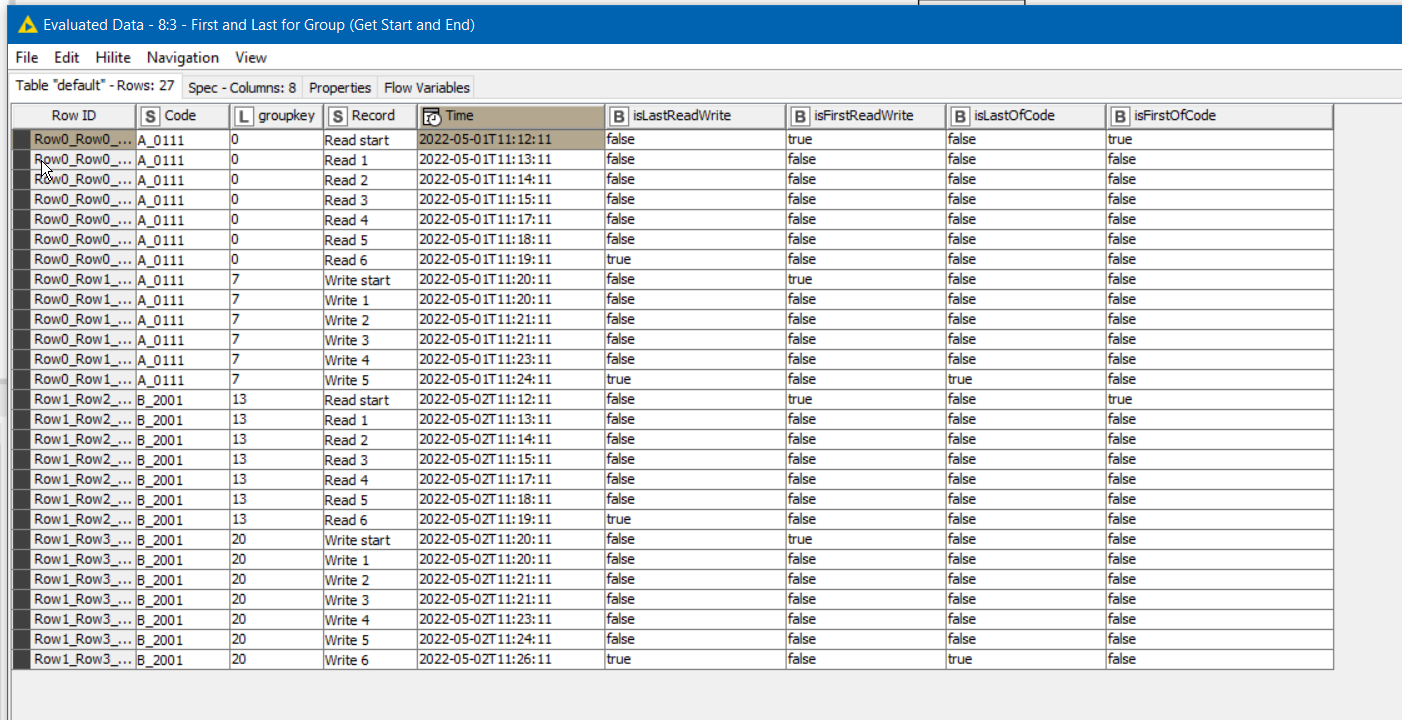
Taking from that idea, groups would be identified by containing the word “start” within the Record. Use a Rule Engine to place the ROWINDEX into a new column where ever the word “start” appears in Record. Follow this with a Missing Value node to copy down GroupKey from previous value where it is missing. (Ignore the annoying in-your-face “warning” on the Missing Value" node. Anybody know of a way to turn that off? ![]() )This then provides a unique “group key” for each read or write block.
)This then provides a unique “group key” for each read or write block.
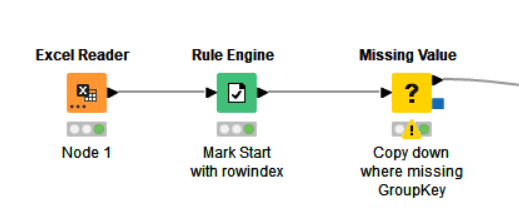
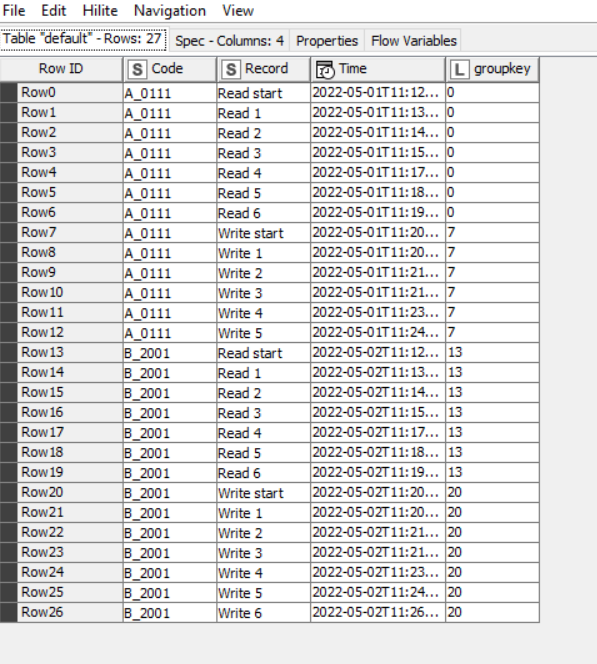
After this, you can then group using that groupkey.
As an aside, some time back I also wrote a component “First and Last for Group” which can be used to indicate the first and last rows of a group identified by a grouping column such as this “groupkey”. It can occasionally be useful, and if you are wishing to perform other actions based on a row being first or last, it might be handy.
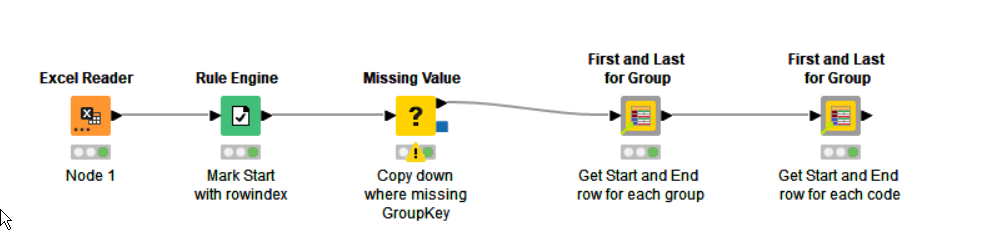
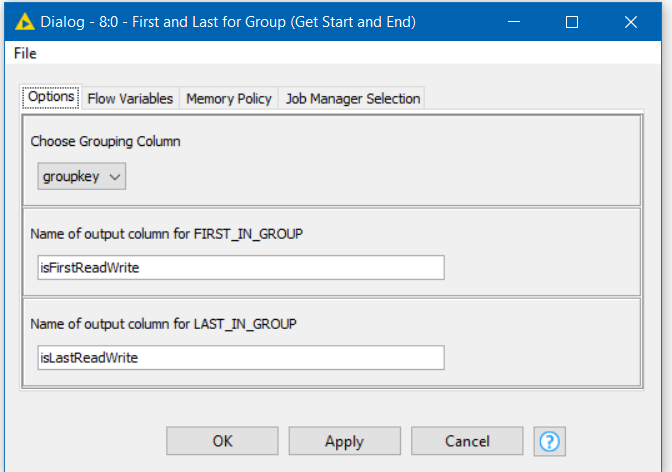
Finding first and last in group.knwf (69.1 KB)