My new challenge is to shorten a big list of our products (round about 120k) by their responsible R&D guy. Well this would be easy with the “group by”-node.
My challenge is now to find the smallest common product id. The product id is of course unique and a 12 to 16 digit/letter combination.
It’s like 1ab2345-6cd78-9ef0. One group can end with at least 6 digits/letters another with 8 or 4.
Is there a node for that? Did somebody such a job in the past? I am open any help.
Hi
I am not fixed to a certain amount of digits/letters. It should be the most least number of digits/letters, depends on the variance of products and responsible persons.
In my first try I grouped by product family (first 3 digits/letters) and the responsible person. For example, now I 6 row with kindly different product Id’s. 1ab222, 1ab245, 1ab285, 1ab269, 1ab612 and 1ab902. The first four should end after 5 digits/letters and the last two can end after 4 digit letters.
How can I shorten them automatically?
So the first part of the IDs (the digits/letters before the first -) relates to the product family and the responsible person and you want to take last part (the digits/letters after the last -) of the IDs.
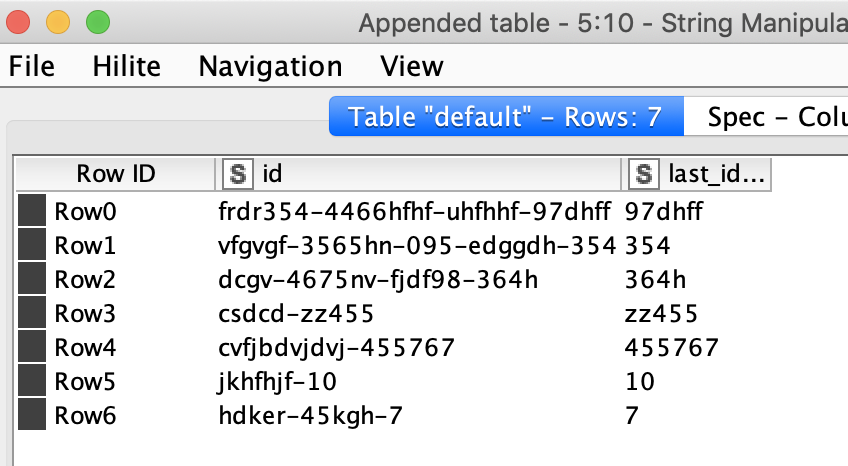
If that’s the case then the solution by @mlauber71 is doing what you want and also you can use this expression in a “String Manipulation” node to do that for you: regexReplace($column1$, ".*(?=-)-", "")
But if this is not what you want I need more explanation.
Thanks for your answers, but I think this is not exactly what I’m searching for.
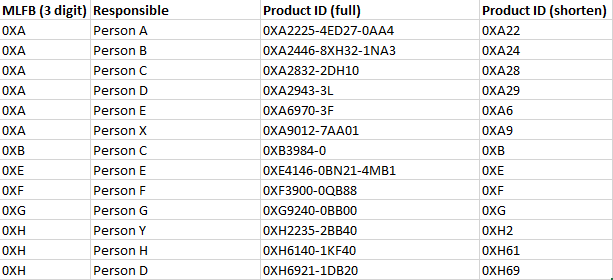
It is not only the last part. Please have a loo at this example table:
The minimum count is 3 digits, like the first column. I hope this makes it clearer.
Oh, just for your information, 0X can also change.
Edit:
As I investigated my table I realized, that I did not catch all possible groups, because e.g. Person A is also responsible for 0XA21 and Person B for 0XA23. I configured my groupe by node with “last”.