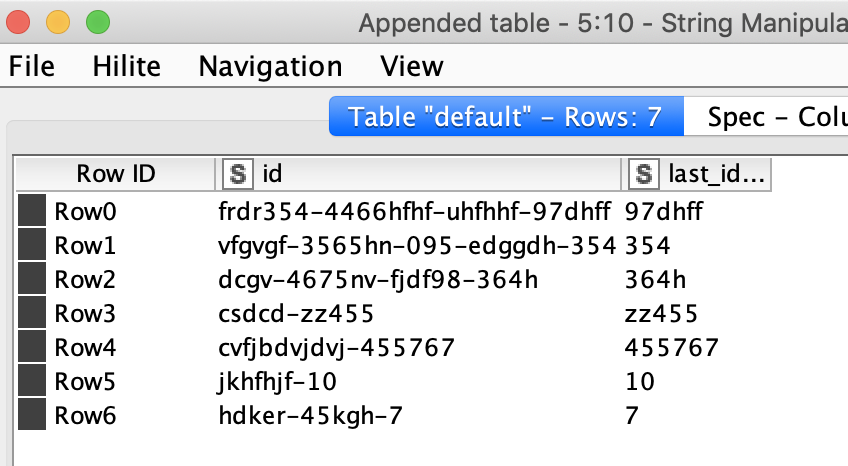
Here is a method to extract the last portion of the ID after the “-”
Pattern p = Pattern.compile("\\-(?:.(?!\\-))+$");
Matcher m = p.matcher($id$);
if(m.find()) {
return m.group(0);
}
else {return "";}

You could then decide what to do with the results, how to sort them; you might extract the numbers or come up with some logic.
kn_example_text_number_value_regex.knwf (18.6 KB)