Greetings esteemed Knime lovers - I’ve run into a conundrum.
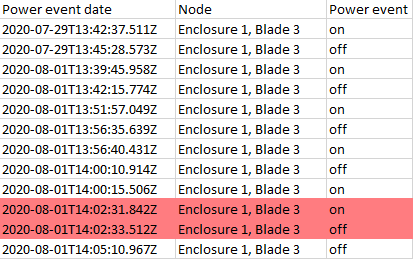
Power events from an estate of compute nodes is collected and this data must be used for various functions, this much is not an issue. However, within the data (simplified example shown below) records sometimes show duplicate events (for known good reasons) that mean the time-associated events aren’t just “on, off”. In some cases, rows will emerge in the data that mark “on, on, on, on, off” events.
To complete a waypoint in my work on this, I need to clean this data back to absolutes, “on, off” and so, for this example data set below, need somehow to remove the rows between the absolutes (marked in red)
I’ve looked at the time functions but this is an issue of specific row subtraction based on a cell value in a variable sub-set loosely associated with time and date - I can’t fathom it.
There are many ways to achieve this task. Maybe someone will propose something simpler. In the meantime, you could :
duplicate the “power event date” column, & keep all char until the minute, and remove the rest (i.e.: 2020-08-01T14:02) using “String Manipulation” node and regexp or not,
group by the new column with the “first value”, this way you’ll keep the first event occurred (On or OFF).
If you share some data (even dummy, changed or false data but with the same format as yours), I’ll try to do it on Knime for you.
Hey Samir, very good of you to engage this challenge.
This however, is the path I originally took, to focus on the time aspect and use Knime’s powerful Date&Time functions, but the problem with this is that the times of many of the double starts can sometimes be hours apart and even next day due to initiating power event at 23:40 followed by a reset at 00:01 the next day for example. This ruined my idea to use the date and hour, group and purge - things went quickly wrong there, but I think you’re along the right lines
Ultimately though there is a ‘set’ being defined with the first “on” for a server after the last “off”. Whilst this this “on” has a time I’m not sure it’s relevant because the end of the ‘set’ is defined specifically by the pattern of the last “off” before the next “on” for that specific server. Anything in between the start and end events is superfluous and should be culled.
I can visualise it in my mind, but can’t articulate it in Knime.
As per your request, I’m attaching a simplified data-set, I’ll keep plugging away here too - there must be a way. - Correction: I can’t seem to upload a .csv here - how does one do so?
… I think the issue here is that the next Row decision is based on the previous Row’s third column value… I reckon it’s going to take some coding to solve this :0(
I understand what you’re saying. Indeed, it will be easier to play with date&time series for this kind of tasks.
Import your CSV file in a Knime Workflow and export the workflow with the CSV Reader node in “green light”. If you reset the node before exporting it, the CSV won’t be exported.
To sum up, you would like:
— to keep the “start record” & the “end record” ?
— to remove everything in between ?
Moreover, it’s not possible to use the date as a string to summarize because sometimes an event occurs on two days range (i.e., between 23:00pm and 01:00am, so not the same date close by an hour or two) ? Are all my assumptions correct ?
My idea is to create two additional columns, where your third column is shifted by on row e.g.,
Original Column | Original Column (-1) | Original Column (+1)
on | ? | off
off | on | on
on | off | on
on | on | off
off | on | ?
Based on these columns we can now use the rule-based row filter node to define in which rows we are interested e.g.,
Original Column = on AND Original Column (-1) = off => TRUE (Switched from on to off)
Original Column = off AND Original Column (+1) = on => TRUE (Switched from off to on)
In addition we need some rules for the edge cases, where we have a missing value in the first or last row due to the shifting
Original Column = on AND Original Column (-1) = ? AND Original Column (+1) =on => TRUE
Original Column = off AND Original Column (-1)= on AND Original Column (+1) = ? => TRUE
This workflow on the KNIME Hub creates the two additional columns and implements the rules for the example table. Below is a little workflow which allows you to test the rules.
thank you, both for educating me on how to share a workflow, and on accurately summarising the challenge.
You’re spot on: the date&time info seems like the “go-to” aspect of the data to use to control and define the set, but it’s a red herring - the first “on” for a given server, after it’s last “off” is the definition of the “start” and conversely, the last “off” before the next “on” for the given server represents the end of the set. All on-off events in between are “noise” to be wiped.
The date&time detail is only useful to uniquely identify the first “on” for a given server, after it’s last “off” and of course to mark the time consumed at the last “off” before the next “on”.
In short, yes, your explanation is correct and (I think) I’ve shared an example herein.
Last night, consumed by this puzzle, I sat on the couch with a notebook and pen and drew out the relationships between the rows and the emphasis to them of the data-series vertically in col3.
I haven’t fully absorbed or tested what you’ve suggested (yet!) but this immediately matches the gist of my thinking last night. Let me test this and revert.
Dear all, I thought it appropriate to provide a conclusive update and thanks.
@SamirAbida - my apologies for my lack of familiarity with posting example data to the forum to aid community support. You were first to answer the call but I failed to get you what you needed to help. Apologies.
@Kathrin - Kudos to you, your solution led me to success. I’d have never stumbled across the Lag Node were it not for this problem and your solution offering, whilst I had some data pre-organisation to complete (52,000 lines of organisation), the lag (-1) and lag (+1) approaches worked magnificently, in fact I used this approach to solve two issues: the one published and also a “definition of each on/off data subset” per server ahead of pivot.
Sincere thanks to @Kathrin , @SamirAbida and all who contemplated this issue - the experience was very “elves and the shoemaker” - enough to encourage me to start trying to help solve community issues. …we’ll see.