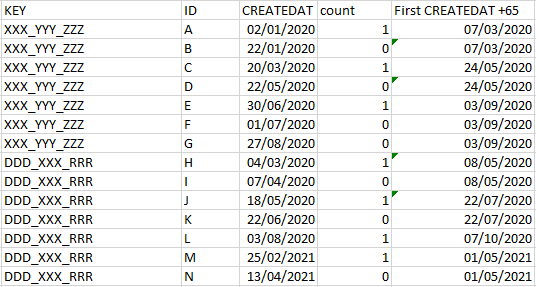
I want to consider only the rows where the first record for each 65 days.
For example: A occured on the 02-01-2020 B occured on the 22-01-2020 so A =1 and B=0
C occured on the 20-03-2020 (wich is more than 65 day since the first record) so C=1;
D occured on the 22-05-2020 so D =0 because it’s <= Occurance of C+65 days.
Hope I’ve made myself understand.
I have no idea how to accomplish this in Knime.
Can someone help, please?
I’m not exactly sure on the solution, but you may considering looking at the Lag Column node, Date&Time Shift Node, and Date&Time Difference node, along with the Rule Engine node (to get a 1 or 0)… The only really tricky part I foresee is getting it to evaluate the next row above if the immediate row above is not +65 days.
with standard KNIME operations, it’ll be quite complex in my opinion.
However, using a Java Snippet, it’s achievable.
The approach of @Snowy is correct.
Please find the workflow attached. I tested with a threshold of 10. That can be changed to 65 with the help of the input widget.
I saw that you already hopefully have the answers you need from a much more compact workflow, but I’ve done this as a learning exercise and just for laughs(! ), to see how I might implement such logic. I also wondered how it would be to do the logic to work across multiple rows at once without using the LAG column.
It appeared that the KEY was a grouping so that A-G were in one KEY group and H-M were in another.
Therefore my understanding is that the date matching was to only occur within those groups, and maybe wasn’t actually necessarily dependant on the order of the rows themselves. If they were wrong assumptions then obviously my subsequent logic will be slightly off, but anyway, here it is… enjoy!
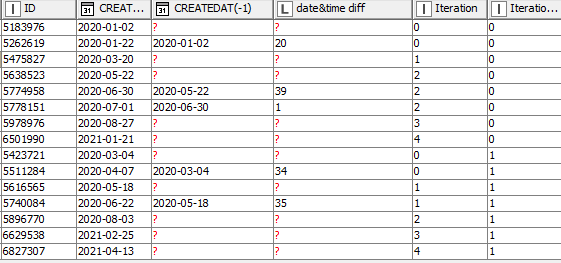
The process in my head was more straightforward than my resultant workflow:
Group each of the rows by KEY (e.g. XXX_YYY_ZZZ and DDD_XXX_RRR) and for each of those find the current minimum date.
Mark the row that was the minimum date in each case as “START” to show it was the START of a 65 day period
Within each group, then join all the other rows to this START row and compare dates. Any rows that were within 65 days of the START should be marked as “DESELECT”.
Collect all rows that are either START or DESELECT and remove them from the input data stream.
The new input stream for the next iteration consists of all remaining rows.
Return to step 1 and repeat process until there are no rows remaining that are not either START or DESELECT
On completion of the loop, all START rows are marked as”1” and all DESELECT rows are marked as “0”
Dry running that process:
Iterations
1 START: A, H DESELECT: B, I
2 START: C, J DESELECT: D, K
3 START: E, L DESELECT: F,G
4 START: M DESELECT: N
That felt relatively straightforward. Then I attempted a workflow…. And yes, it did come out very complicated (maybe more complicated than necessary), but at the end of it, it did return the result from the example data, and as a learning exercise for some of the constructs it is maybe useful.
Oh I love this!
I will definitely look into it, specially since I’m new to Knime it’s always good to see different ways of thinking and different ways of doing things!
Thanks a lot for the help, what a great community!



 ), to see how I might implement such logic. I also wondered how it would be to do the logic to work across multiple rows at once without using the LAG column.
), to see how I might implement such logic. I also wondered how it would be to do the logic to work across multiple rows at once without using the LAG column.
