Actually I see that it isn’t possible to change dynamically via variables configuration of Fixed Width File Reader. Is there any solution? Or will it be introduced for this node?
Thanks
Actually I see that it isn’t possible to change dynamically via variables configuration of Fixed Width File Reader. Is there any solution? Or will it be introduced for this node?
Thanks
What makes you say that?
It certainly is possible to use flow variables to define the width of columns in this node.
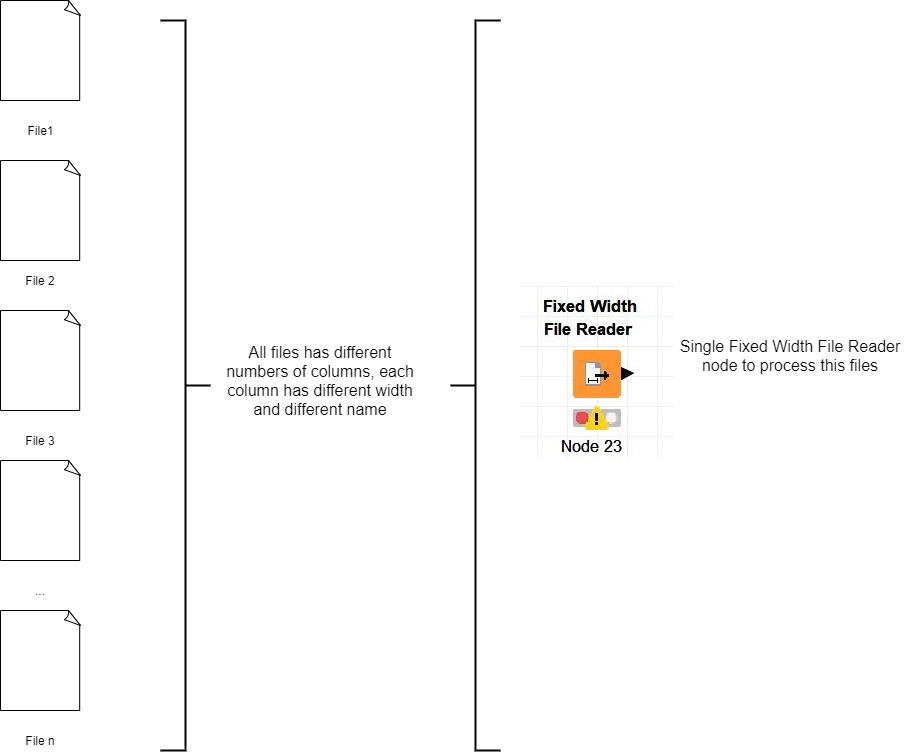
For example I want to read with this node files that have different number of columns, different column names, different columns width. So I need to do a generic Knime that depending on configuration could read different files.
I guess I still don’t understand what the issue is.
We need details and context here.
I take it that you want to define the column names and widths using variables, is that correct? If so, what’s preventing you from doing it now? What have you tried? How are you defining the variables? How are you calling them in the reader node? What’s the specific error that you’re getting?
This might’ve been sorted out days ago if you were more forthcoming. If you could provide example data, an example of your desired output, and ideally a workflow, anyone could jump in and try to assist.
See please the following image:
So, the idea is to have a single KW, that will first read configuration of the file from DB: number of columns, column name, column width, column type and read the file based on it. Each file has different configuration.
Hi @natashullea , can you please share your File1.csv and File2.csv?
The files are in KW archive. They are in csv format, I cannot attach them here.
I could not find them, and I don’t think they are in the workflow as your Fixed Width File Reader nodes are pointing to absolute path (file:/C:/Knime/knime-workspace/FixedWidthFileReader/File2.csv)
To include the csv files, they should be in a “data” folder inside the workflow folder.
EDIT: Ok, I found them in the workflow folder itself
Hi @natashullea , looking at your workflow, I don’t understand what is the issue. It looks like you are able to configure the Fixed Width File Reader nodes dynamically.
From what I understand, you will be reading these configs off a db table, and your Java Edit Variable nodes are simulating that, and you were able to read both the File1.csv and File2.csv successfully, with both having different structures (different number of columns). It is what you have been trying to achieve according to your first comments, isn’t it?
I am not sure I am following what you want. Is it that you want to have this in 1 workflow? Reading off a DB table will allow you to run this as 1 workflow. For an example workflow like you provided, you had 2 workflows because you are providing the configs individually and separately.
Is this what the issue is, to have it in 1 workflow? If so, can you please provide a sample of what the config would look like from the db table? And what happens to the data from the files after it is read (concatenate, merge, …?) ?
Yes, I need to have a single KW.
For example, when I do my KW, I configured FixedWidthFileReader for 2 columns, but my current file has 5 columns, in this case the node will read only 2 configured columns.
If I configure FixedWidthFileReader node for 10 columns, but try to read a file having 2 columns I will receive and error Errors overwriting node settings with flow variables: Unknown variable “col3_width”.
Hi @natashullea , can you show us where you will be reading these configurations from? How does the configuration data look like?
See please this KW FixedWidthFileReader-with-config-change.knwf (43.9 KB)
And also, do you really need to use Fixed Width File Reader? The 2 csv files you provided are actually TAB delimited, they don’t have fixed width. You could use File Reader or Simple File Reader where you would not need to provided any width info
Yes, Fixed Width File Reader.
These two files are test files.
A db table will have three columns: column_name, column_width, and column_type
Here’s your workflow modified to use the Simple File Reader.
FixedWidthFileReader_with_SimpleFileReader.knwf (46.8 KB)
You can connect either workflow to that node, and it will work for both workflows
No, it isn’t that I need. Files that I try to read doesn’t have delimiter, I know only number of columns, their name, type and width.
Hi @natashullea , ok no problem.
Nodes like Fixed Width File Reader are not straight forward to understand how to pass the widths and names - only once have I been able to use another similar node successfully, but I can’t find this workflow anymore.
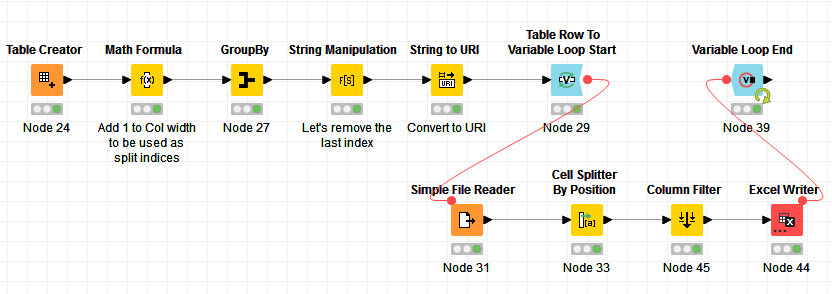
As an alternative I am going to use Cell Splitter by Position which should be quite close to what Fixed Width File Reader would do, but it tells you clearly how to present the dynamic data:
This is what the workflow looks like:
Basically, the Table Creator contains the config you would retrieve from the db, for example:
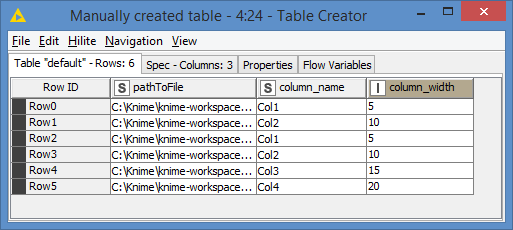
Since Cell Splitter by Position deals with split indices instead of width, we can adjust the width to become the indices, and we prepare the indices and the names - that’s basically what these nodes before the String to URI are doing.
I then use a Simple File Reader to read each file, and then split the columns accordingly. You would usually then process the data. Here, I simply wrote back to an Excel, but each file that has been read is saved under a different Sheet. So you will end up getting sheet 0 and 1 in this example, and columns splitted based on what is in the config.
Here’s the workflow: File Reader with files with different column width.knwf (113.1 KB)
Thank you.
In your example column_width is in increasing: 5, 10, 15
In my situation is a mix of width: 1, 5, 1, 15, 30, 4, 8 etc.
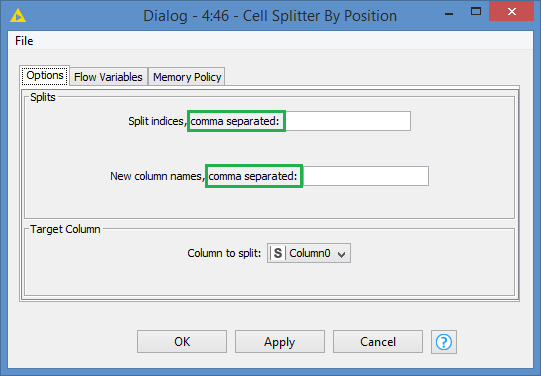
The following WARN is received: WARN Cell Splitter By Position 7:33 Errors loading flow variables into node : Please specify strictly increasing split point numbers
Form node description:
Split indices
Enter the position(s) of the splits, separated by a comma. For example, the string “ABCDEFG” with the split points “2,4” creates three new columns carrying the results “AB”, “CD”, and “EFG”. The specified split points must be strictly increasing numbers larger than zero.
see my post below please