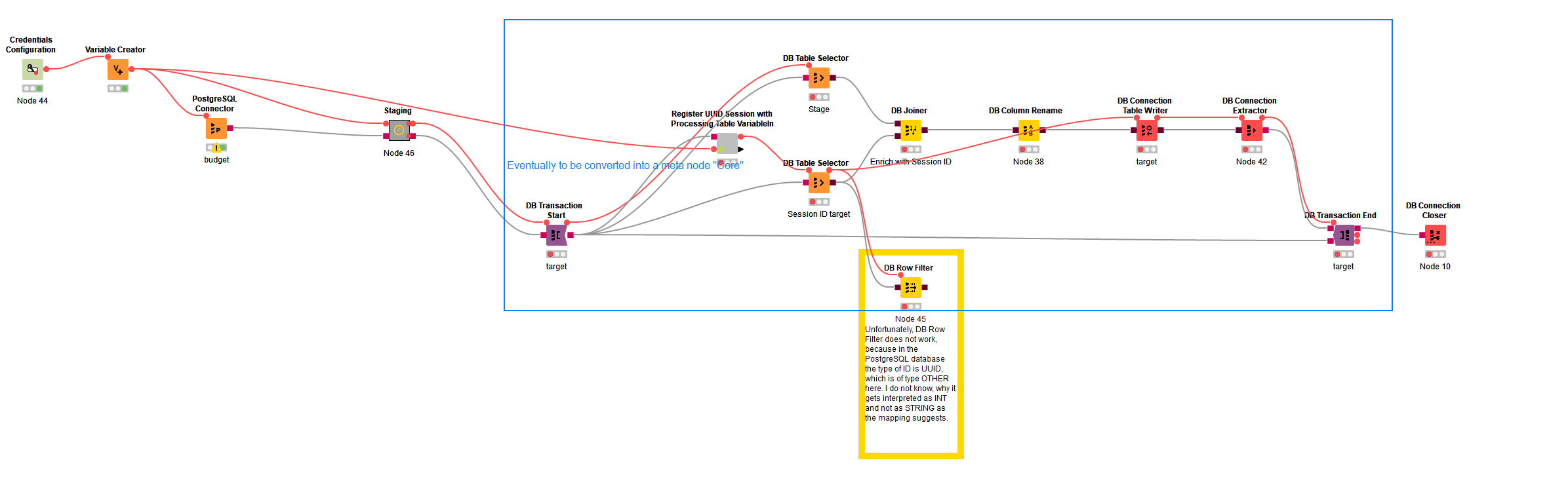
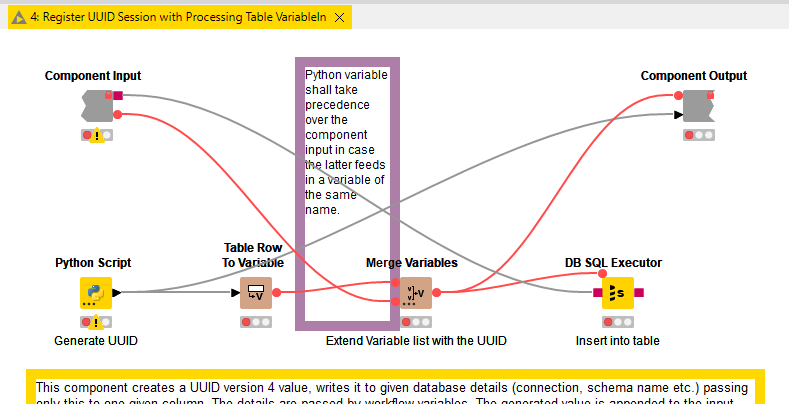
I presume, my knowledge of the flow variables is just faulty. I have a workflow (part of it, see below) where I want to use the beginning state of flow variables in a late node - shaded in blue. Therefore, I connected the flow variable port of the variable creator, shaded in green, to it too - start and end shaded in yellow. However, there are two variables that originate from the shared component framed in red. What are the rules for the visibility of flow variables? I mean, there is no flow variable connection other than the initial state to the node in question.
Hi Thiemo,
The relevant part of your workflow is cropped, but I assume there is a table connection between the red-framed component and the blue-shaded one. Flow variables are not only passed along the red connections, but also along all other types of connections. The red connections only exist for cases where you want to pass a variable without any other connection existing. So since your variable creator passes its variables to the red-framed component and that has some connection to the blue-shaded one, the red connection from green to blue is not even necessary.
I hope I could clear it up! Let me know if you have further questions.
Kind regards,
Alexander
Thanks for picking that up, and I am sorry to not have responded earlier.
I am a bit puzzled about the question whether there could be a table connection to the blue-shaded node when the blue-shaded node has no table input port at all. Is there something like hidden table connection, like it is with flow variables?
If I understood you correctly, the implicit flow variable propagation takes precedence over the explicit. If so, how can I impose an execution order dependency without passing the latest set of flow variables? In my case, e.g.
I have an ETL process that should load data from files into a staging table and if that has completed successfully, the just loaded data should get loaded into a core table with conversions and what not. Both use the same shared component to register the load with a table returning the load id to be used in the data loading, thusly the first load id generation interfering with the second. I could split the workflow into to workflows and use a scheduling software to handle the dependency but I wanted to go without such means for my private project.
I am a bit puzzled about the question whether there could be a table connection to the blue-shaded node when the blue-shaded node has no table input port at all. Is there something like hidden table connection, like it is with flow variables?
I think here I was not precise enough. The blue-shaded component has an input from the DB Transaction Start, which in turn has inputs from the right side of the workflow, which I assume has connections from the variable creator. Flow variables always flow along all connections, and I think the variables from bottom ports always take precedence over variables with the same name from an upper port.
So the main problem for you, as I understand it, is that the variables interfere with each other and here it’s unfortunate that KNIME has no concept of “filtering” or deleting flow variables from the flow.
Components isolate their flow variables inside and let out only those that you explicitly allow in the component output node’s configuration. Could that be a solution for you to avoid the name-clashes? The only other solution I see is renaming one of the variables, but that’s probably not so nice either.
Alexander
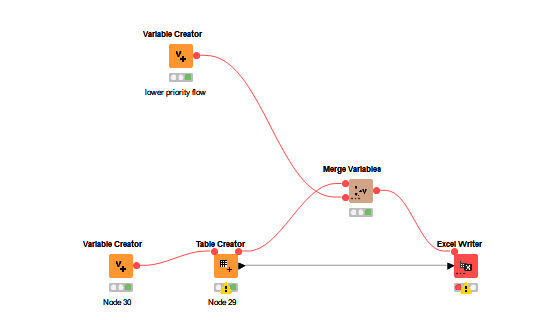
Hi @Thiemo.Kellner , if you have a set of flow variables on one flow that should take precedence over another set on another flow, join them first with a Merge Variables node. Attach the “priority flow” to the top input.
e.g. in this mock-up, the variables on the lower branch containing the Excel Writer will continue to exist after the Merge Variables even if there are conflicting variables of the same name on the incoming “control” flow.
@AlexanderFillbrunn
Actually I tried with renaming, but the old variable UUIDv4 remained, “stage_session_id” being the new one (red-framed in the first screenshot). It seems, I borked it somehow though.
Out of curiosity. We do the implicit variable take precedence. To me, this is counter-intuitive. If I explicitly connect a variable connection, I assume those are taken. What else would be the point of connecting them as I did from the beginning (Variable Creator) into the middle of the workflow. At least, I would expect a warning, that there is a workflow variable conflict. Just my two dimes.
Hi Thiemo,
I agree it would make sense to have a warning if there is a flow variable conflict. I have created an internal ticket for our developers. The ticket number is AP-21440, for future reference. Having just created the ticket, I cannot promise any time for delivery yet, though.
Alexander