Estoy creando un flujo que me toma una tabla maestra de datos y que cada mes se le agregan meses nuevos, quiero hacer un flujo que me detecte un archivo nuevo en la carpeta que destine para esas descargas y que me agrege de esos archivos solo los meses que necesito sin que deba recorrer o leer toda la carpeta
Si he entendido bien la pregunta, hay que buscar en un directorio los archivos existentes.
El nodo List Files/Folders List Files/Folders — NodePit puede utilizarse para este fin.
Esto le dará la lista de todos los archivos.
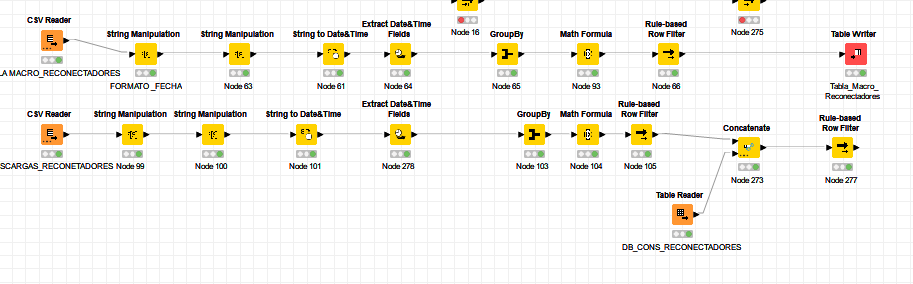
El tema es el siguiente tengo un flujo donde con el excel reader me lee todos los archivos de una carpeta luego los organizo en un formato de fecha que requiero pero la idea es que cada mes se agregan nuevos datos y no quiero que me lea nuevamente todo sino el archivo nuevo que puse en la ruta y el dato que esta alli me alimente una tabla donde tengo estos registros
Hola @cplaza8908
Sería bueno que guardes un registro de los datos que ya has leído y tengas una columna con algún identificador de fichero, en toda la data que lees.
El proceso es el siguiente:
Como te dice @knimediger , lees los ficheros de tu carpeta con el nodo List Files/Folders y lo comparas con los registros que ya leíste en procesos anteriores.
Te quedas sólo con los nuevos registros en en tu lista. Mandas esta lista incremental al lector de ficheros
Le agregas a la data leída el identificador de cada fichero
Por último agregas (concatenas) la nueva data a la data que ya tenías.
depronto tienes algo que me explique esto , soy algo nuevo manejando esta herramienta
Como te dice @knimediger , lees los ficheros de tu carpeta con el nodo List Files/Folders y lo comparas con los registros que ya leíste en procesos anteriores.
"Como los puedo comparar?
Te quedas sólo con los nuevos registros en en tu lista. Mandas esta lista incremental al lector de ficheros " como se hace esta parte?
Le agregas a la data leída el identificador de cada fichero
No eh podido entender ese flujo que enviaste, si tengola datos en una ruta de mi computador con que nodo haria lo que me enviaste en el ejemplo que reemplace al de google drive ?
vi que dentro de la table creator hay dos campos pero no logro hacer que me funcione no se si me puede explicar bien esa parte ?
@cplaza8908
Con los ficheros en local es más sencillo. Sólo tienes que crear las variables ‘Path’ para leer y salvar tus procesos. Puedes eliminar los conectores.
Un saludo