I’m used to Alteryx and am very new to KNIME. I have a json output from AWS Transcribe of an interview I did with a customer. I need to take the JSON output and format it either in word or an xls output. I need to extract the speaker field (three people total, so speaker 0, speaker 1, speaker 2) and the verbiage associated with that speaker. I uploaded a zoom video into AWS Transcribe to get the transcription. It’s formatted properly in the text preview box in AWS, I just can’t figure out how to get the JSON file to mimic that formatted output. Does someone have a simple workflow that addresses this use case they’d be willing to share?
Hi @ebarr and welcome to the forum.
Do you have a sample of the JSON data you could share, along with what the desired output would look like? That would be helpful in better understanding the issue.
1 Like
Hi @ebarr -
You might be able to do this in KNIME using a combination of JSON Path, Ungroup , and GroupBy nodes - but I suspect it will be easier to use a pre-existing, short Python script to do it, like this one I found at StackOverflow:
Maybe it would be worth trying that within a Python Script node?
I’ll take a look, but unfortunately, that may be above my skill level. I was hoping that since AWS has a predefined transcribe json output with multiple speakers, there would be a node for that. I’ll keep searching around. Thank you.
Good news - I figured out how to get to the single word outputs by speaker. The next issue is how do I do a multi-row formula like in Alteryx? I’d like to concatenate the words together into a sentence and group by speaker so that spk_1 will have a full sentence, then when it goes back to spk_0, i concatenate (and add a space between each each word to turn into a readable sentence), so, each word and space will continually aggregate so that at each change in user complete sentence will be formed, then delete the previous rows. The formula would be something like if row_current:speaker = row_previous row then row-1:contents plus row current::contents" " so that by the last speaker in the grouping, a complete sentence is formed . I’m not finding anything like that?
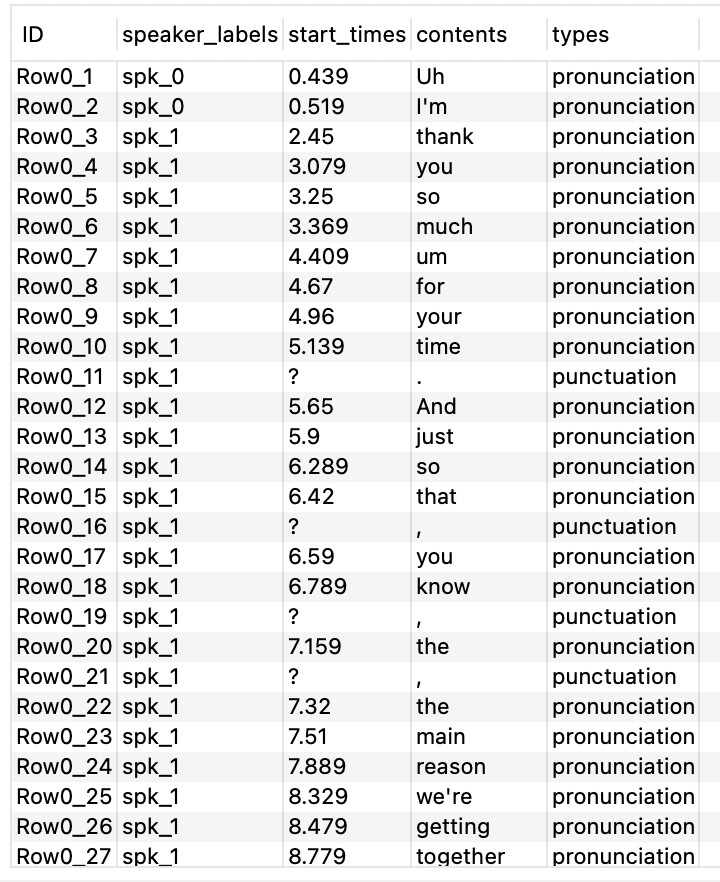
Hi @ebarr -
After thinking about this some more over the weekend, I came up with the following. It’s not the most elegant solution - maybe you can improve upon it? But there’s no Python involved, and only a tiny bit of scripting (just a few lines) in a Column Expressions node.
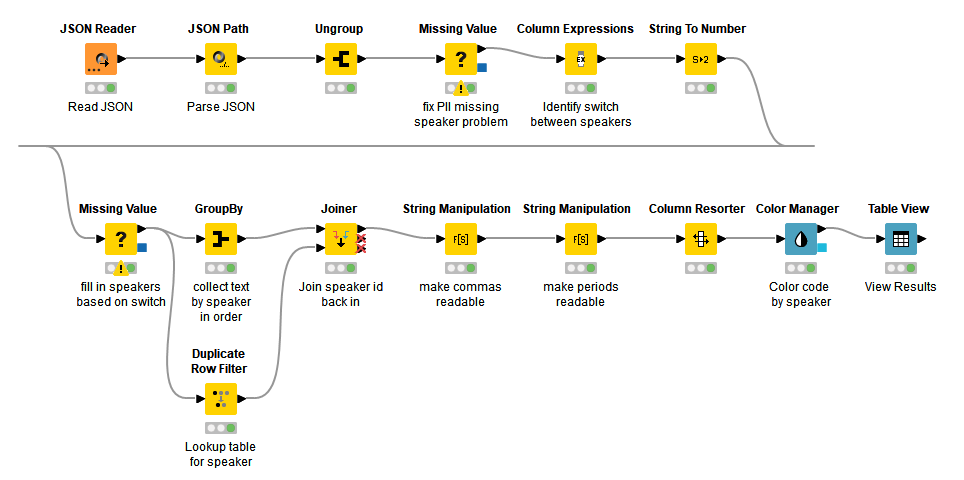
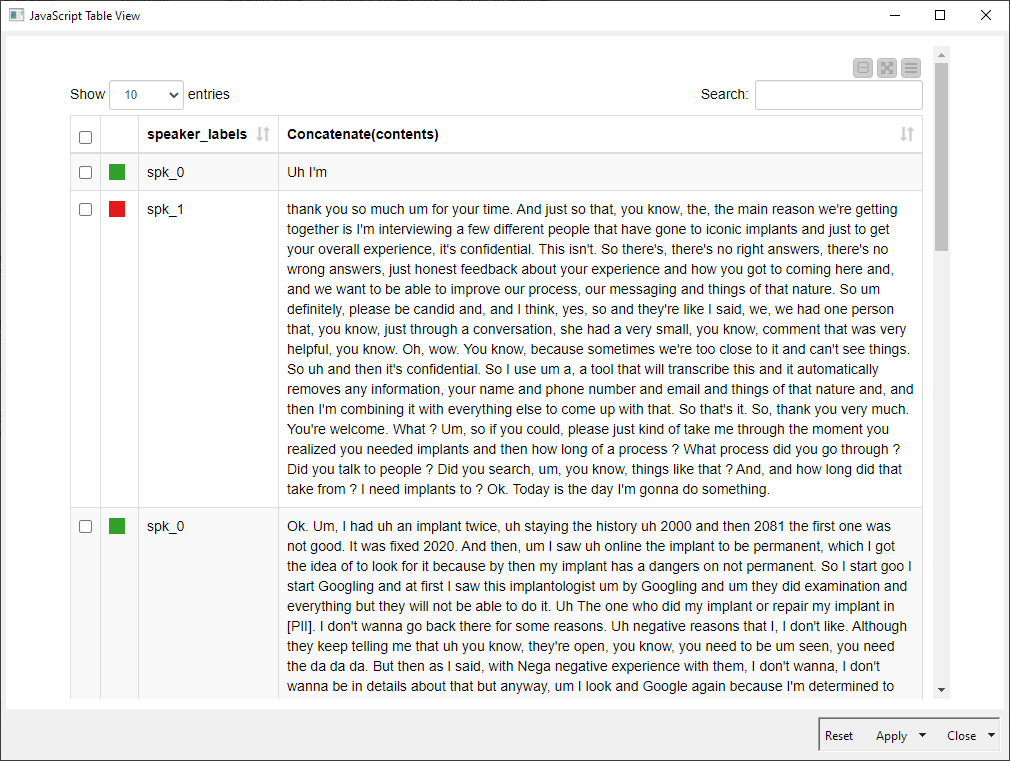
ParsingAmazonTranslateJSON.knwf (517.2 KB)
EDIT: Made some additional changes because I couldn’t help myself. This was a fun little challenge ![]()
1 Like
This is absolutely perfect - thank you very much!!!
1 Like
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.