I have several files that have added to one table. I am trying to reformat the table so I have all the headers in two rows at the top. The table has each tab below the other from a file and the subsequent files and tabs below including the headers from each tab. I want to first move all headers into just two rows at the top creating additional columns across for all sizes within the headers. Then I want to pivot the headers to Rows from columns and have the 1 and 0 values in columns to right of all the other rows. I have attached a sample file to show the table structure. I highlighted the headers rows and used red font o show that headers below are a different size below the first header even in the same column. I am fairly new to Knime and would appreciate some help if possible.
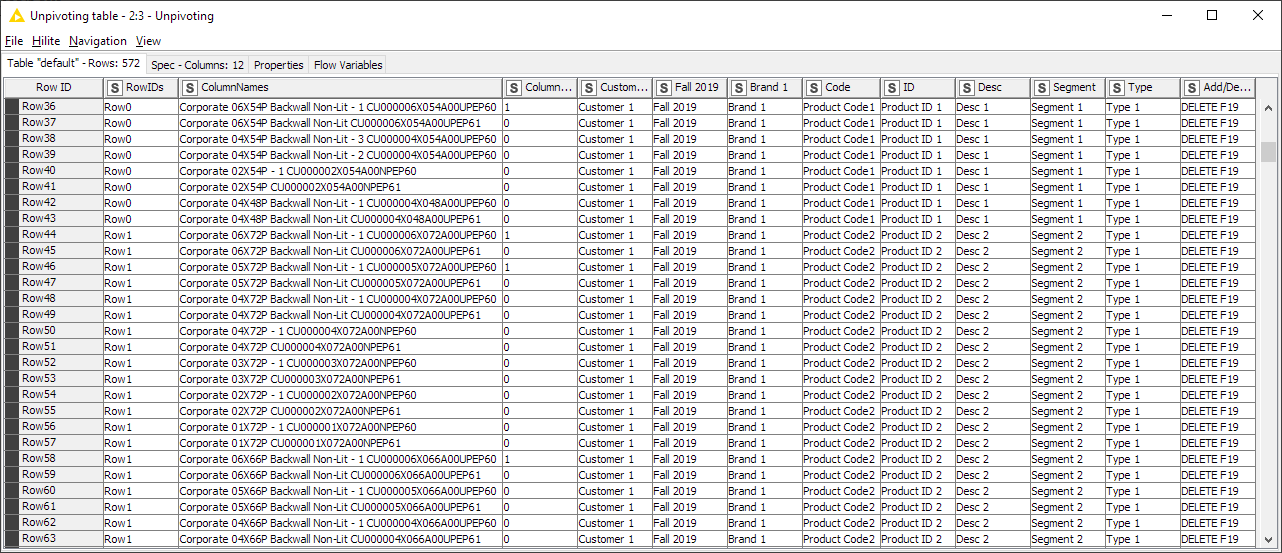
I think the best way to approach this might be to do some unpivoting on each individual table BEFORE combining them all together. Since I wasn’t 100% sure what you’re aiming for, I took a stab at it in the workflow below using just the first “chunk” of data - mainly to get your feedback before attempting the whole solution. As I see it, there are two main problems to overcome with the raw data:
The header information is broken across rows. I fixed this manually in Excel - outside of KNIME entirely - to start (again, not 100% sure if this lines up with what you wanted) but we could do it in KNIME too with a little more massaging.
You have information from different backwalls in the same column when combining multiple tables together. This is the primary reason I think the unpivoting should come first - we can always combine the tables using a loop afterward.
If the output of this initial data chunk is what you were envisioning, let me know and we can think about how to deal with headers and looping. Or if it’s completely off target let me know that too.
Thank you for the reply. What you have is what I am trying to get to for the end product with the exception of the column order which is easily fixed once we solve the header and pivoting issues. I have 200 plus files with multiples tabs I am trying pull together in this format. You are correct when you said I have information from different backwalls in the same column when combining multiple tables together. That was something I could not fix when running the initial loop with my limited experience. I was trying to unpivot after instead of first and do not have a good understanding of the unpivoting node. I greatly appreciate any assistance you can provide.
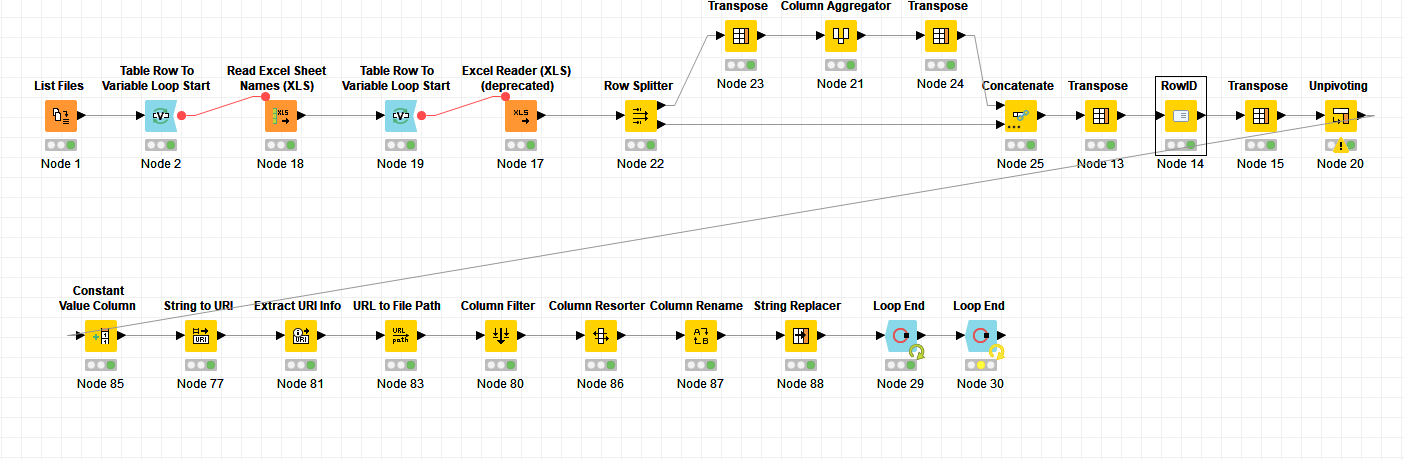
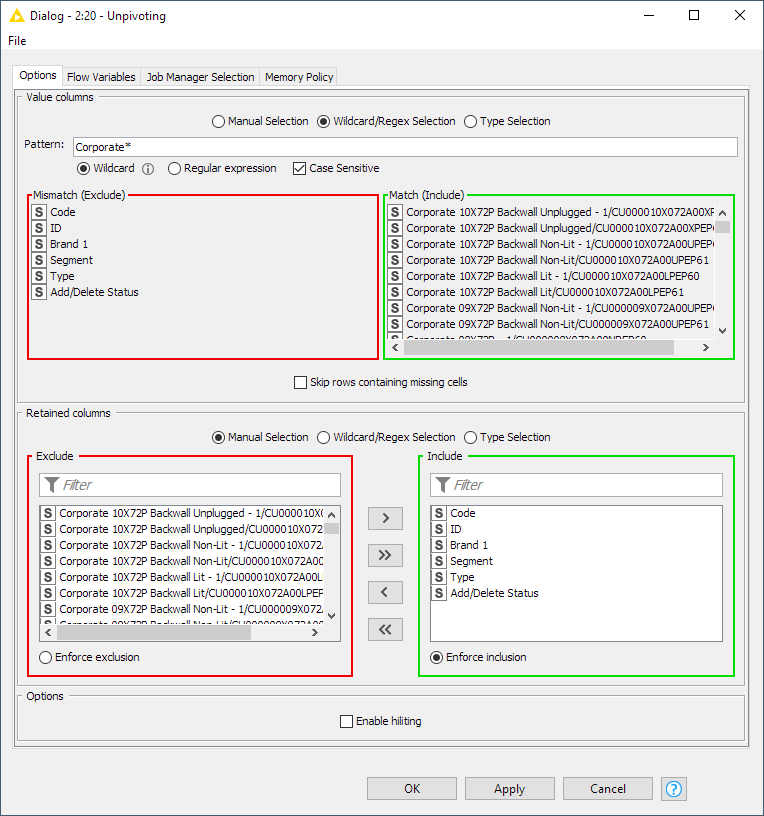
I have built a workflow that does what I need with one file. The problem I have now is that I need it to run for all files but I am getting the warning below at the time of the unpivoting node. I have also copied a screen print of my workflow. I put the Unpivoting in after I combined my header infornation into one row as you did in your example and made it the RowID for my table so it would unpivot as I need it but it not able to loop because of the warning.
WARN Unpivoting 0:20 Some selected value column(s) are no longer available: “Corporate 06X72P Backwall Non-Lit - 1/CU000006X072A00UPEP60”, “Corporate 06X72P Backwall Non-Lit/CU000006X072A00UPEP61”, “Corporate 05X72P Backwall Non-Lit - 1/CU000005X072A00UPEP60”, … <41 more>
See attached Workflow and example files that are a small sample of what the files are like for you to add to the list file nodes to see what I am trying to accomplish with the workflow. It works perfectly one file at a time but need it to loop through multiple files. The issue in the loop is with the Unpivoting node because of the varying columns. Please let me know if you have any questions.
Your outer loop is for file selection, and your inner loop is for sheet selection within each file. So you need them both.
I didn’t look closely at the output from the final Loop end node, but it seemed at a glance to be OK. Are you seeing a particular error, or is the resulting data just not what you expect?
Below are the errors I am getting and what My work flow looks like when I execute the last Loop End.
WARN Excel Reader (XLS) (deprecated) 0:17 Node created an empty data table.
WARN Row Splitter 0:22 Node created empty data tables on all out-ports.
WARN Transpose 0:23 Node created an empty data table.
WARN Column Aggregator 0:21 Please select at least one aggregation column
Looks like for whatever reason, the Excel Reader isn’t loading your file (or sheet) properly, and then you get an empty table downstream from that.
Check out the attached workflow, which ran OK for me. I did have to make a change to the flow variable assignment in the Read Excel Sheet Names node, but that was minor.
That was the issue with my workflow and it works now. Now I am going to try it with the actual files to see if it works. Thank you so much for all your help. it is greatly appreciated.