Below are the same two H2O Random Forest Regression Workflows. The only difference is the top workflow is partitioning the data 80/20 Learner/Predictor, and the workflow below it feeds 100% of data to the Learner and the Predictor.
Why? it’s a small data set of 630 home sales and constitutes the full data set. There’s no sample–this is all there is.
Two questions: 1) is the second WF a correct set up (100% of data to Learner and Predictor, no partitioning) when using a complete data set, and 2) are the RMSE, MAPE, and R2 scores legitimate when using 100% of data at the Learner and Predictor nodes, or am I creating a self-fulfilling prophesy series of scores?
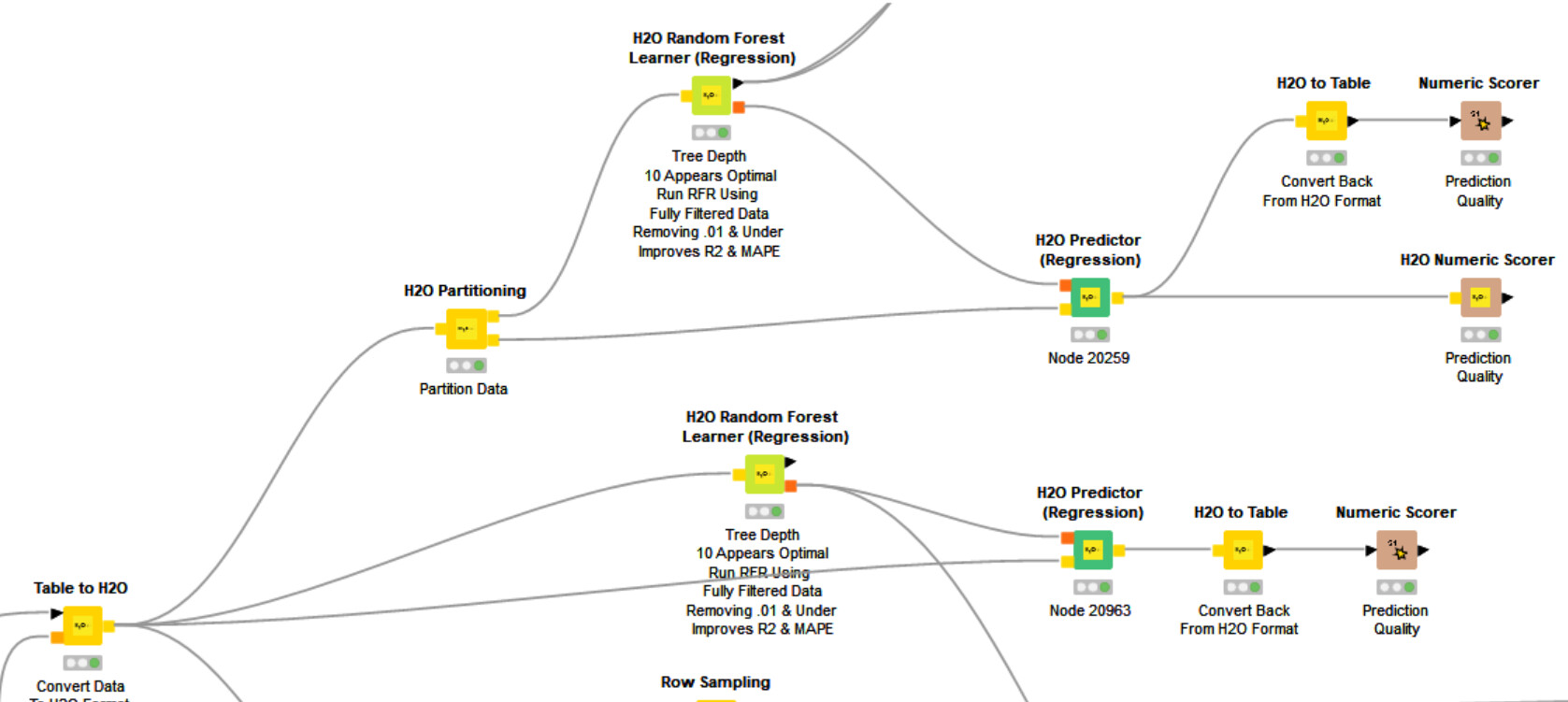
I realize this may be more data science philosophy than a question of structural KNIME workflow design, but I ask for your patience and kindness.
Thanks