Hi, Knimers,
I am facing a problem with diacritics, in a column named “Municipio” (the Portuguese word for “City”). The same issue to another column with has also a few diacritics, such as: “á”, “ã”, “é”, “í”, “ô”, etc.
The DataBase contains COVID open data, and is available at: <https://ti.saude.rs.gov.br/covid19/download>
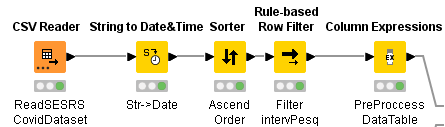
I tried to use the nodes: “Column Expressions”; “String Manipulation”, and “String Manipulation (Multi columns)”, with the same results:
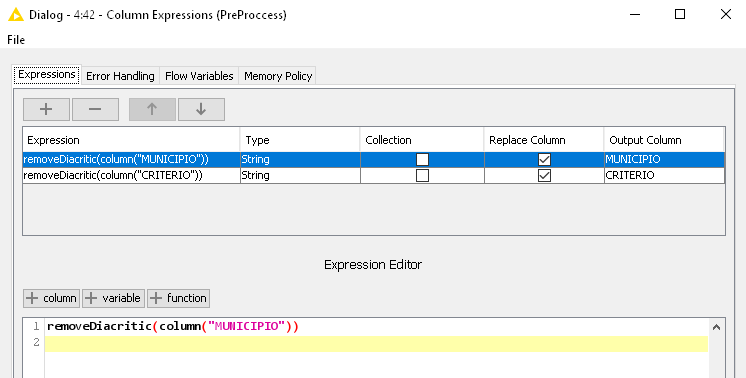
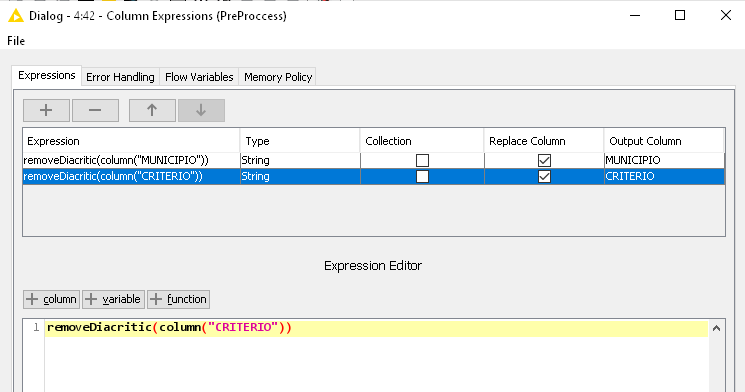
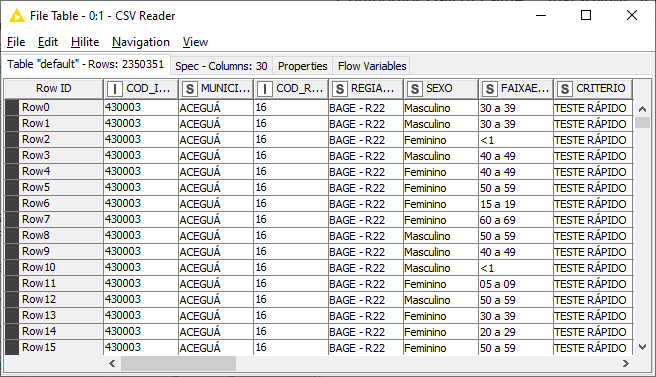
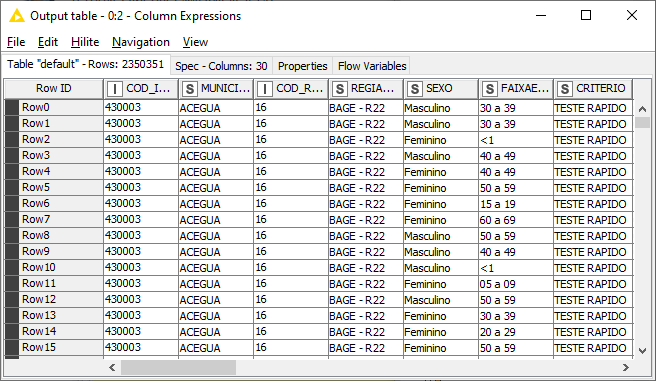
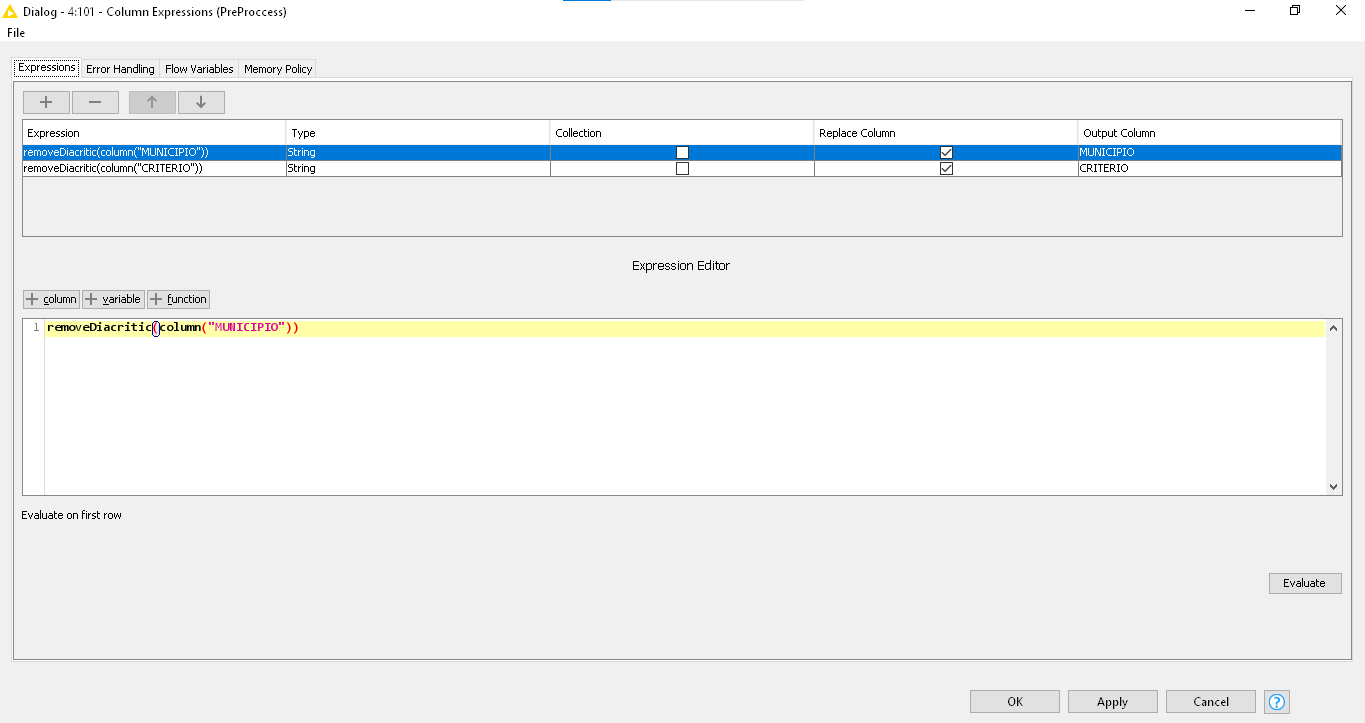
I used the funcion “removeDiacritic(str)” and selected the column “MUNICIPIO”, and got the expression: removeDiacritic($MUNICIPIO$).
Maybe I’m missing it, but I’m not sure I see where the problem is.
You say
I tried to use the nodes: “Column Expressions”; “String Manipulation”, and “String Manipulation (Multi columns)”, with the same results:
but you don’t say what those results were. Was this successful or not?
Then out of nowhere you say
I need to join two databases, but I can’t attain a proper inner join if the same data are written differently in the two datasets.
Where did this come from? How is this relevant? There are no database nodes in your screenshot. Did you just mean tables? What are the two tables and what’s stopping you from processing the data the same way for both?
Can you give more details about the problem you’re trying to solve?
Sorry, @elsamuel, for not posting the full workflow.
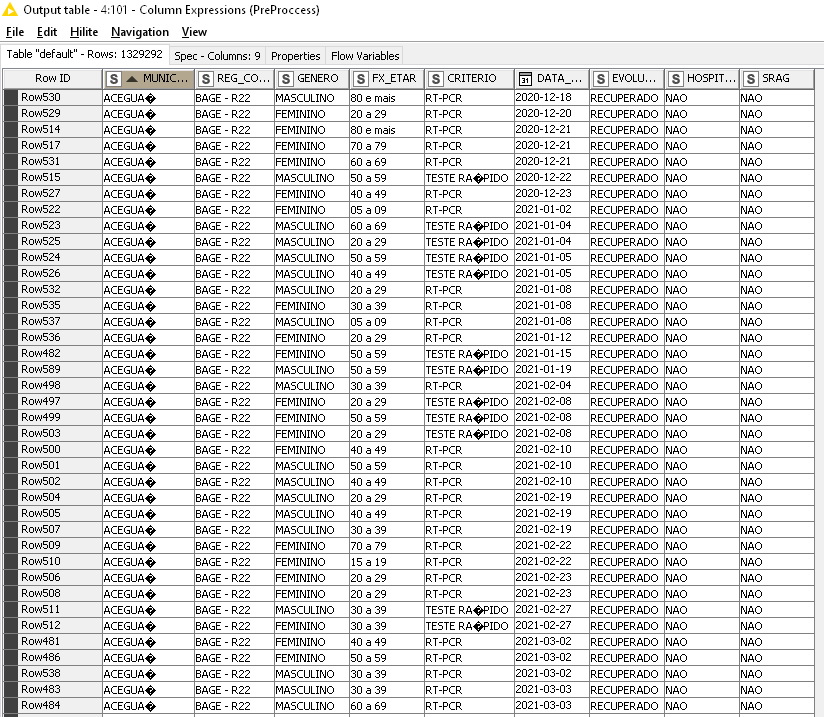
On the first database, I didn’t get the expected results; my results were: the diacritics remained on those two columns “Município” (which means 'city") and “Critério” (which means “diagnosis criteria”), even after the usage of the function “removeDiacritics(name_of_column)” on the listed nodes…
The data on the second database are protected under a confidence term. It includes several data collected by means of a survey with professionals of a specific industry. But I have no problems with these data, as soon as the nodes worked out pretty fine with them. My issue is with the first database.
I downloaded the csv file and I can successfully remove diacritics from those columns using the removeDiacritic function in the the Column Expressions, String Manipulation, and String Manipulation (Multicolumn) nodes.
Hi, @elsamuel and @bruno29a (and sorry for the delay on my reply…).
Thanks for all your answers,
By the way, I’m working on Knime 4.5.2.
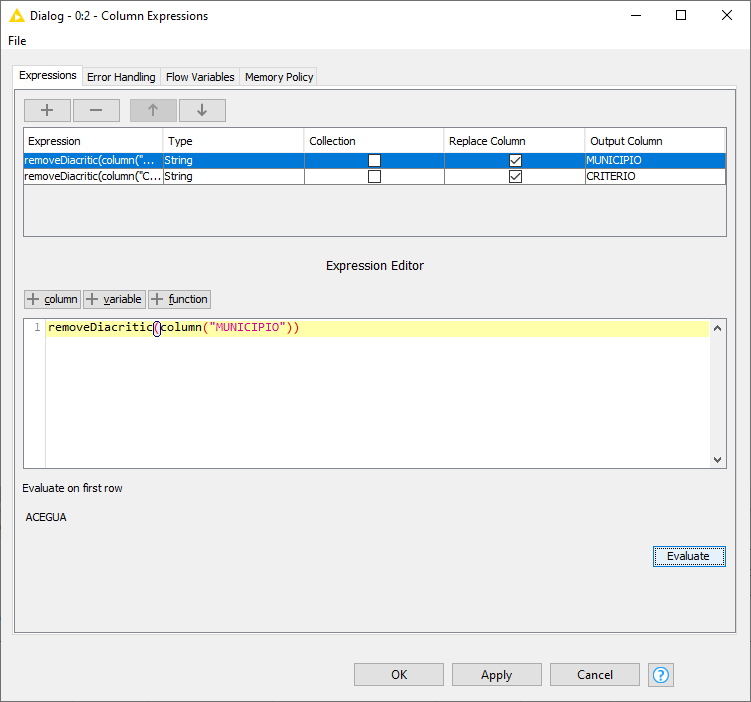
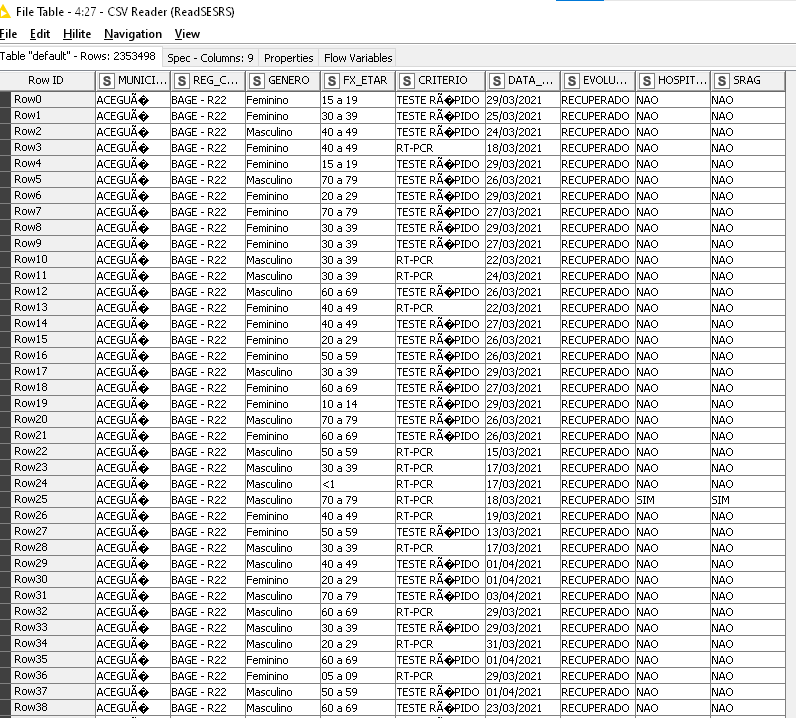
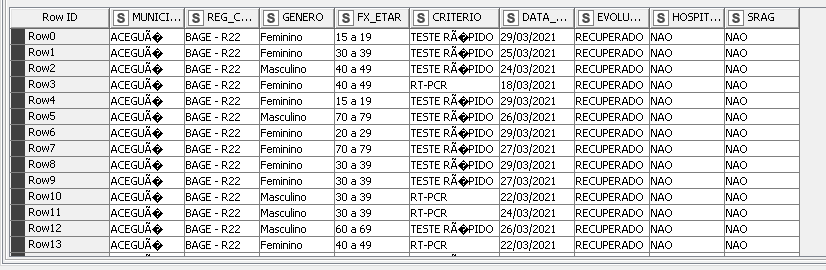
I downloaded again the CSV file, browsed once more the csv reader node, configured this node to work only with my 9 selected columns, kept them all as strings, and the data look like follows:
As far as I can see, I have done as well as you had shown me, but I’m afraid I’m still making the same mistakes (what you did right, I did wrong)… And I got no idea of where is my error.
Can you find my mistake? As I did it, it ended as it began…
Hi @rogerius1st , on the CSV Reader Node, double click on it. Look for the Encoding tab, then try select any alternative encoding than the one you’ve got, preferably UTF-8.
Hi @rogerius1st , the “accents” that you are seeing are not real accents. It’s basically an issue with character encoding, and it’s simply displaying like this because it does not know how to properly display the character. So, removeDiacritic() will not really apply on these as they’re not accented characters.
Try to set your character encoding to UTF-8 as @badger101 suggested - check the Advanced settings tab.
@rogerius1st, this is why I asked to take a step back and see the data in your workflow. My suspicion was that you hadn’t selected the proper character encoding. The workflow in my previous reply uses UTF-8, as @badger101 has suggested.
Dear @badger101, @bruno29a and @elsamuel ,
I followed your suggestion (to change the encoding type to UTF-8), and it worked out pretty fine. Thank you so much. I haven’t understood it yet why id didn’t work for me, but now it’s O.K.
You’re welcome @rogerius1st , I recognize the issue straight away once you’ve uploaded the Output Table.
Whenever you work with textual data downloaded from Excel/PDF files from third party websites, it’s generally best practice to first change the encoding type to UTF-8 before running the workflow.