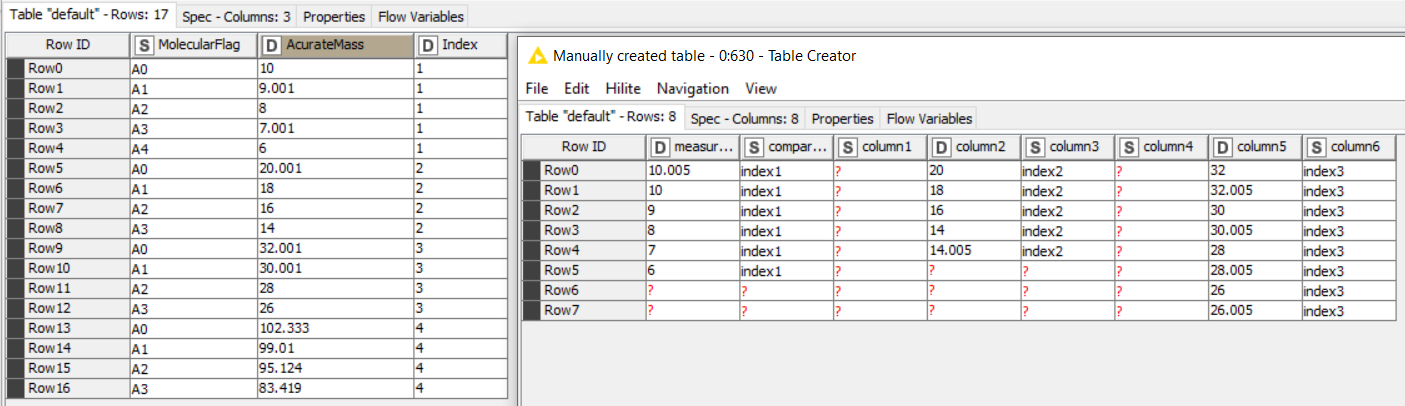
Ok, so the Similarity Search should be much faster (while using less CPU and RAM). There’s one difference in the final output though: The node looks for the nearest neighbor. If there’re multiple measurements matching the same reference value, only one of them will be in the final output. Since I don’t know how you’d want to map those “duplicates” onto the reference table, I figured that’s ok. See screenshot to see what I mean.
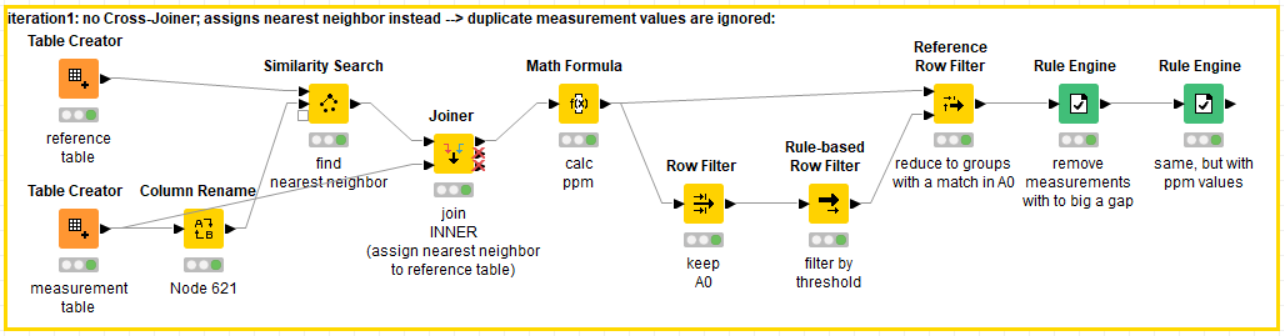
How it works:
- find nearest neighbor for each reference value
- join the nearest measurement value onto the reference table (SimSearch doesn’t do it for us)
- calculate the distance
- branch off and filter down to A0 values; filter them using the distance
- use that branch to filter by reference. keep only the groups not filtered out in the previous step
- remove false matches using the Rule Engine
fuzzy Join two tables with GroupBy and Reference.knwf (111.3 KB)