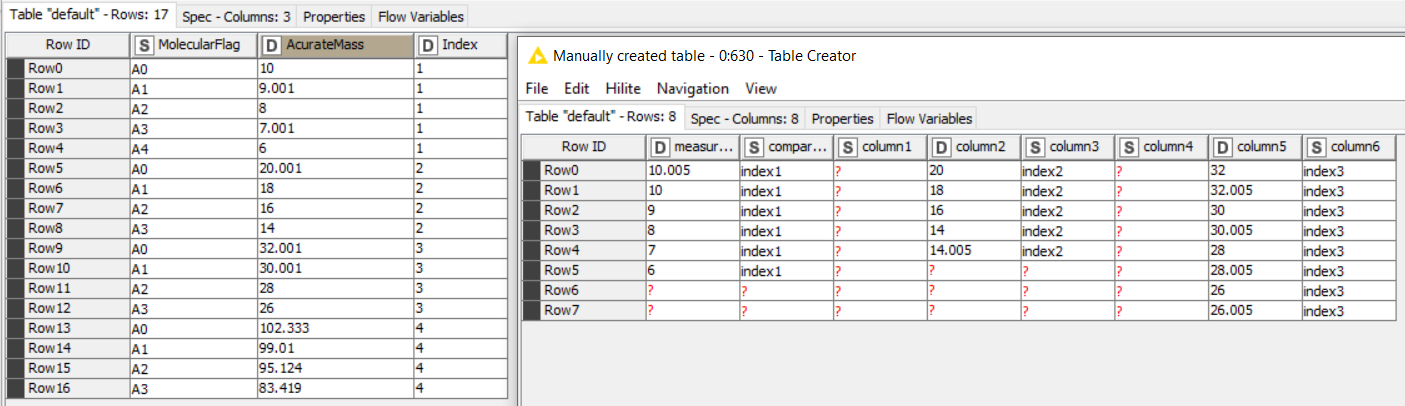
Probably a very easy task however I am not able to obtain what I expect. I have table 1 (reference table) that contains the following information (3 columns): Flag, Mass and Index. The second table contains only mass (sample table). I would like to divide my data in the first table according to the Index and keep the order of the rows. Basically, in my dummy data I would have 3 separate tables/groups on which later on I would apply specific math operations.
Anyway, My first task is to compare each individual cell from table one (column mass) with the second table (column mass) and based on the mathematical formula, calculate the certain values and filter the values based on TRUE or FALSE. (I am able to do that with the cross joiner - math formula). At the end, I would like to extract not only data that match based on TRUE/FALSE but also rows which belong to the same Index from table/group if there is a TRUE value in row A0 (every new group starts with A0).
Basically, If A0 row for each group has a match of [TRUE] extract all rows that belong to this group/table.
Can you explain a bit more what the general goal of this task is? Especially the formula that determines whether or not two rows match each other. Maybe there’s an easier way to solve your problem, cross-joins are very expensive and should be avoided if possible.
Maybe you can also share your workflow? It seems like you managed to make some progress already, it would be helpful to see it. If your data is sensitive, that’s fine, just fill in dummy data instead. You can export workflows by right-clicking on them in the KNIME Explorer.
Thank you so much for your reply.
My general task is to create a workflow that will be used for data analysis in chemistry.
The Very first step (which I described above) is comparing measured masses of molecules with reference masses (I am comparing each measured mass WIth the reference mass from the second list - that’s why I am using a cross joiner) - when I say comparing - I mean calculating error between those two masses and then filtrating them. The molecular formula is: (measured mass-reference mass )/reference mass x 10^6. Basically, I need each individual cell from column 1 (reference table) compared with each individual cell in the measured column (measured table) table 2.
What I was asking is to extract all molecules that belong to the same class which in my dummy data indicates “Index column”. IF there is a match at A0 - “extract all rows that belong to the same group and recognize them as a group”. Why is that? Because later on in my workflow I am calculating the score for all matched masses and I have to include all members that belong to the same group even though not all members from the same group had a hit.
I hope that makes more sense.
I am using a small dataset that I posted yesterday.
So the filter value is the relative error * 1M. How is a match defined? The lowest filter value for each measurement, or with a threshold (everything below x is kept)? or something else?
Another important question that ties into that: Will there always be a match with at least one row of the reference table? In your example data there many rows with values far away from the reference values. If that’s also in your real data, what do you want to do with such measurements?
After the filtering, when we have only TRUE measurements, I understand you want to return all matching rows, plus the entire group of matching A0 rows?
Do you want the output to be free of duplicates, or with one row for each matching measurement value?
It would be great if you could at least share the desired output for the sample data (including intermediate columns). It helps a lot if I can actually see the result.
Probably I should mention which kind of data I use Well, those data are from one measurement where we measure masses of molecules.
For the error match I am using: Double configuration node, Rule engine and Row filter node. Everything below the threshold is filtered out.
I have attached a simplified workflow with two remarks below the last node.
Additionally, at the beginning I don’t filtrate duplicates because I don’t know to which group the certain mass belongs.
Ok, based on your comments in the workflow you want only reference groups where there’s a match for A0. All of the groups rows should be present in the output. Please confirm the results with the attached workflow.
The Cross-Joiner is really expensive to use*. If your actual data is small enough that it’s no problem for your machine, then it’s ok as it is. If not, I can optimise the workflow, but it will add more complexity.
*The row count of the output is the product of the row counts of the inputs. The column count is the sum. To give an example, a 100x3 table and a 1 000x5 table yield a 100 000x8 table. 5300 cells turn into 800 000. fuzzy Join two tables with GroupBy and Reference.knwf (60.0 KB)
t works Thank you so much for your help. I just replaced nodes with older versions as I am using KNIME 4.0 and the nodes that you used were not available for me. Anyway, thank you very much.
At the beginning I was using an R script for mass error calculation however that wasn’t the best solution therefore the cross joiner was the second option. I was planning to exchange for something faster as my measured data contains about 50 000 masses and the database that I am using has around 25000 entries therefore if there is a better way to deal with it - that would be great!
Yes, I can see that 1 billion rows might be too much too handle. I have one important question though: Is it possible that there are multiple measured values for a single reference value?
I hope the answer is no, because then the Joiners in the workflow I already sent you won’t properly work as well.
Do you need the measured values in the output? If not, I can trim the workflow a lot more.
Good evening,
There might be a possibility that the reference mass will be linked to more than one measured masses however that shouldn’t be an issue as I am validating them at the end of the workflow.
The measured masses I need in the output as I’m using them throughout the workflow.
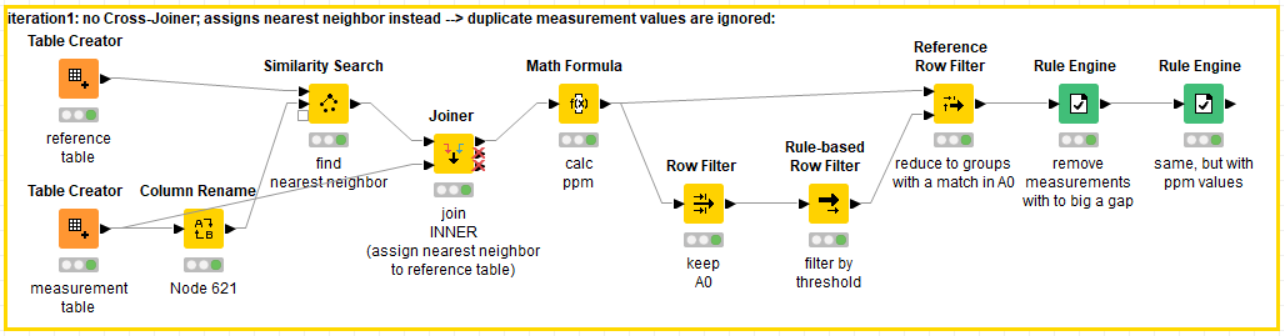
Ok, so the Similarity Search should be much faster (while using less CPU and RAM). There’s one difference in the final output though: The node looks for the nearest neighbor. If there’re multiple measurements matching the same reference value, only one of them will be in the final output. Since I don’t know how you’d want to map those “duplicates” onto the reference table, I figured that’s ok. See screenshot to see what I mean.
How it works:
find nearest neighbor for each reference value
join the nearest measurement value onto the reference table (SimSearch doesn’t do it for us)
calculate the distance
branch off and filter down to A0 values; filter them using the distance
use that branch to filter by reference. keep only the groups not filtered out in the previous step
Thank you so much. It works perfectly Tomorrow I will try on real data and compare the results just to see if there is some deviation or missing masses. You helped me a lot. Thanks
did you have time yet to verify my solution with the real data? Would like to know if there’s more tweaking to do.
If not, please select a post as working solution to this question. Thank you.

 Well, those data are from one measurement where we measure masses of molecules.
Well, those data are from one measurement where we measure masses of molecules.