I have attached some example data and the expected outcome (second worksheet).
I want to compare the string values in one column to see whether there’s similarities among them. Please note my original file has thousands of lines and a multitude or descriptions that I’m not really aware of.
My goal is a first attempt to categorize/group similar lines together for me to further analyze the content of the file.
What would be the best way for handle this?
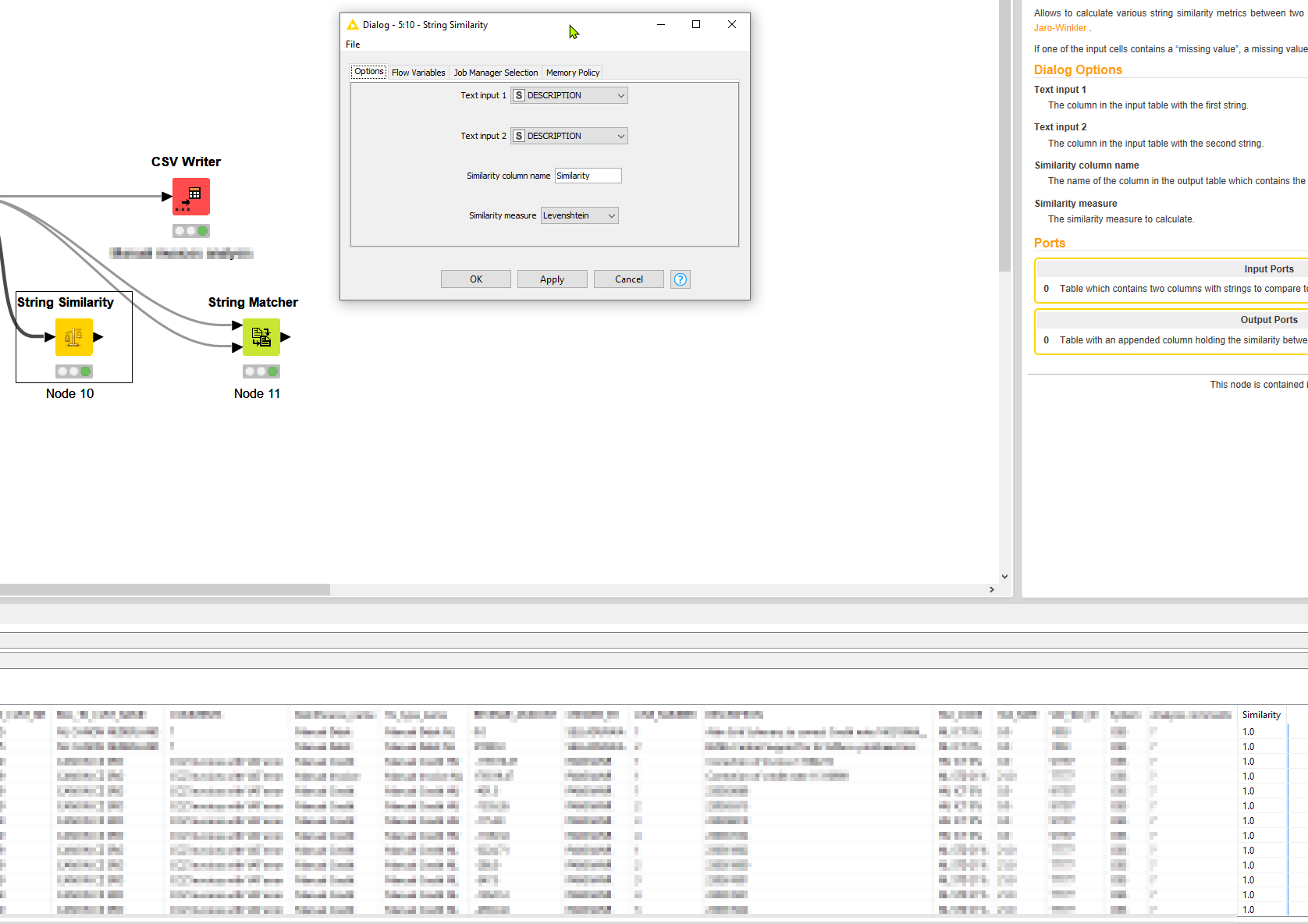
I already tried the STRING MATCHER and SIMILARITY RESEARCH whereby the source and comparing column are identical. But what happens is that it’s only picking up the exact same values. I want to check on similar things and not exact matches. Recharge examples.xlsx (10.6 KB)
I tried that one, but I don’t know how this would help. I only have one column with data and I want to have that grouped somehow. The String similarity is comparing two columns, which I don’t have
Hi @robvp
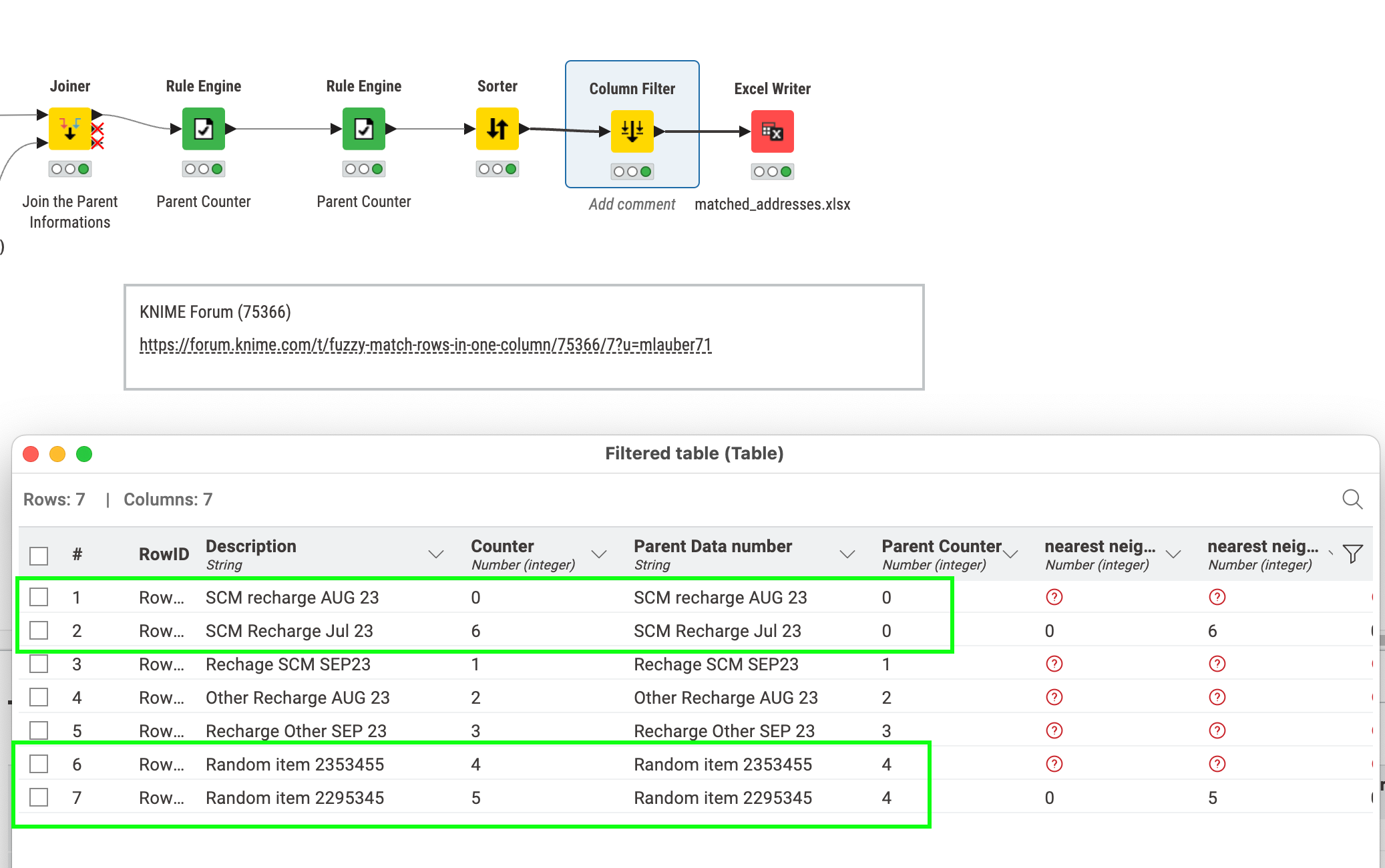
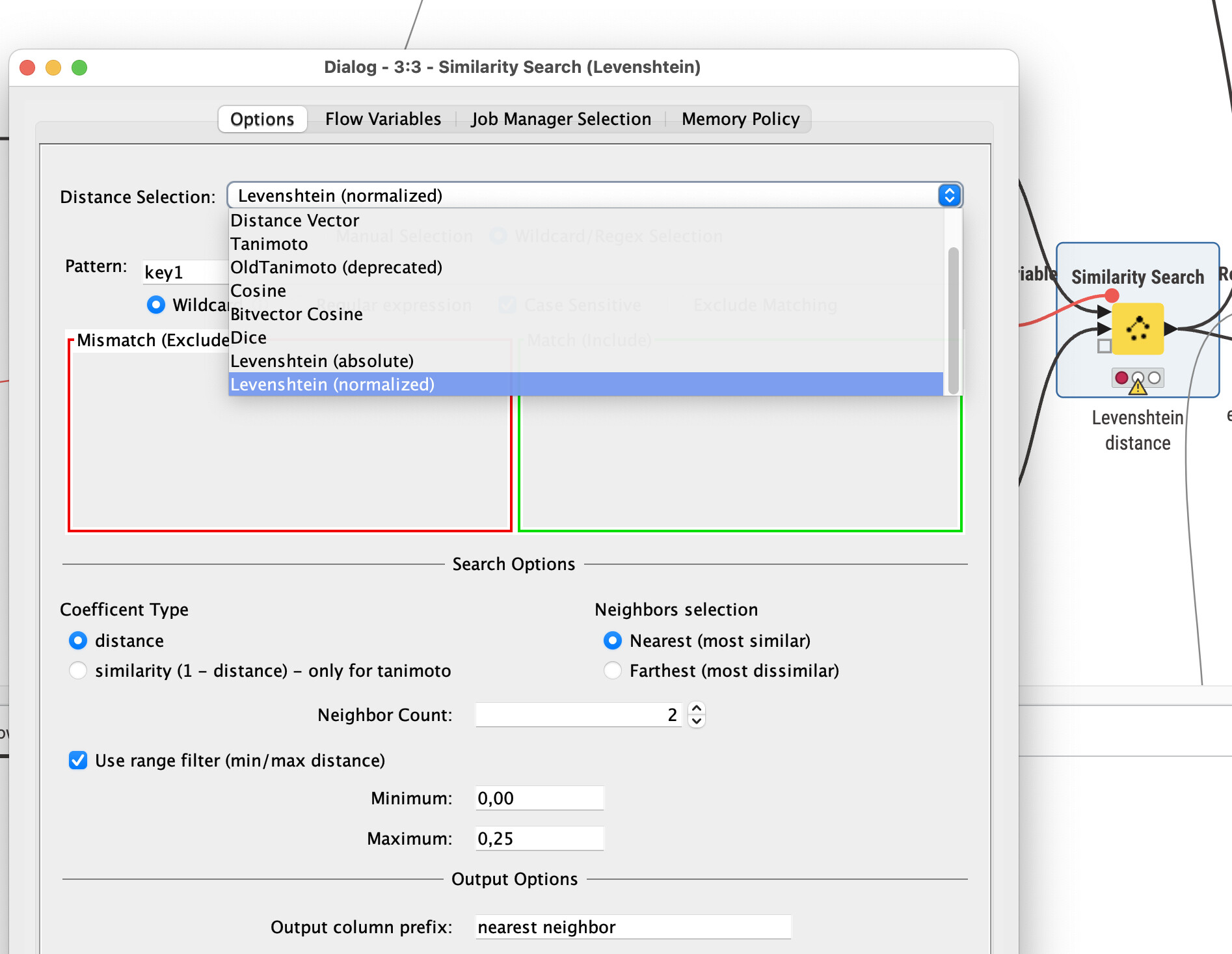
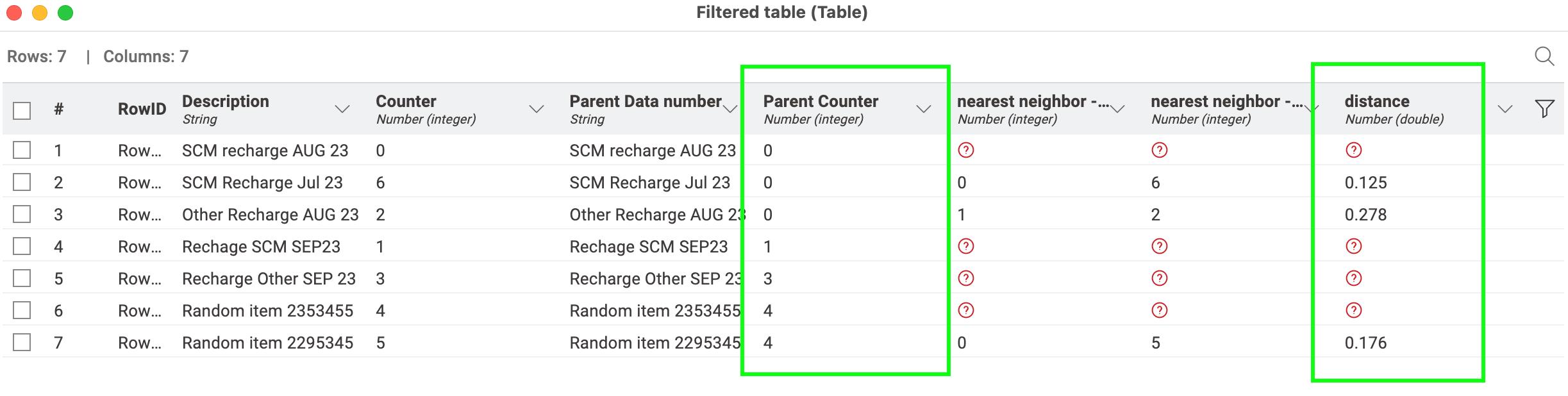
You could take @izaychik63 idea and send the same data into string similarity and increase the neighbor count.
Then you get more then just the same as matching
If you feed the same data twice you would always get 100% similarity for the same record. If you take more neighbors into account then you could filter out the 100% and take the second one
br
@robvp I had hoped that the descriptions given in the workflow might have helped. If you want you can ask further questions or I can try to add more information. My impression was that this approach might be able to help you - if the task still is relevant.
The examples could also be adapted for future tasks involving the matching of similar strings.
The task is obsolete in the mean time, but that doesn’t mean I don’t want to understand because it can benefit me in future situations.
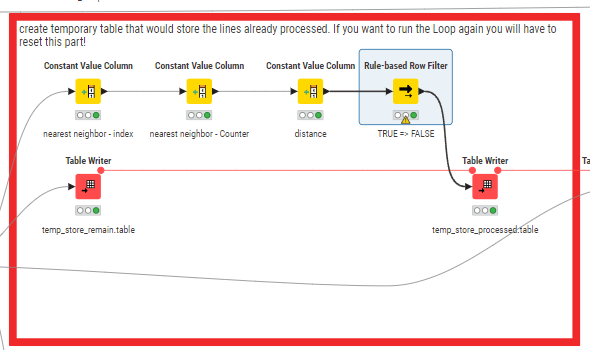
I’m always getting an empty table at the rule based row filter in the workflow. Logic in there is TRUE=>FALSE, so it makes sense. Am I missing something?
Ah, clear!
I’m running it now, but in total it’s over 200.000 lines. Would there be a possiblity to speed things up because looking at the speed it might take more than a day…
@robvp the problem could be that since this is an approach without a ground truth it will have to search all possible matches in each iteration (the ones not yet taken) so it will always need the whole pool of (remaining) options.
If you would have a list of ground truths against which to match you could try to parallelise it.
You might want to check general options how to speed up your KNIME experience: