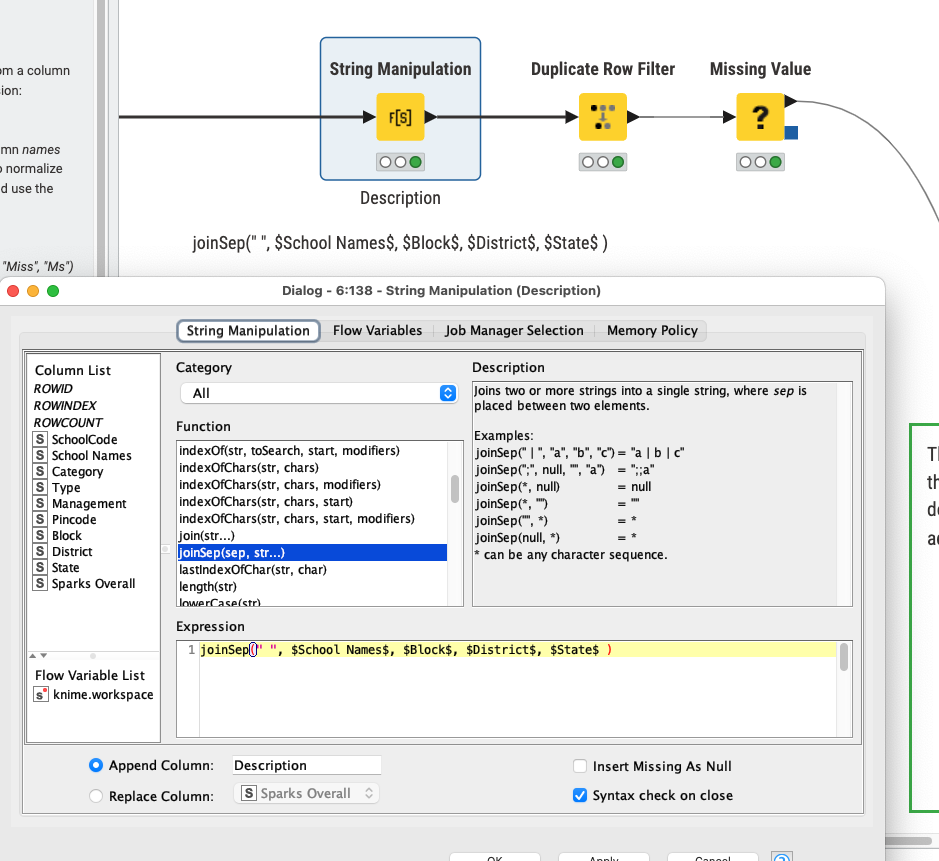
I am trying to perform a fuzzy match of the “School Names” column in the attached workflow. There is no dictionary file, so the fuzzy match is on its own column. For values that are similar in name (say, +90% similar), then we would identify those as part of the same group for the purposes of a Group ID. The Group ID would increment for each group.
The workflow attached is inspired from two other similar discussions, but not quite taken to the finish line.
2 issues currently:
In my attached workflow, the Group ID isn’t incrementing correctly
The Jaro-Winkler component is not able to handle a dataset of 200K (ran for 2 hours, no progress)
The workflow aims to use fuzzy match, Postal Code, District, and State to determine what rows are part of the same group or not.
It does work without a ground truth but just will try to group the Term you create into distinctive groups based on the items you put into the string (called “Description”) …
Hey @mlauber71 - actually that was one of the first workflows I was looking at. Was still trying to understand it , but I’ll give it a second look now.
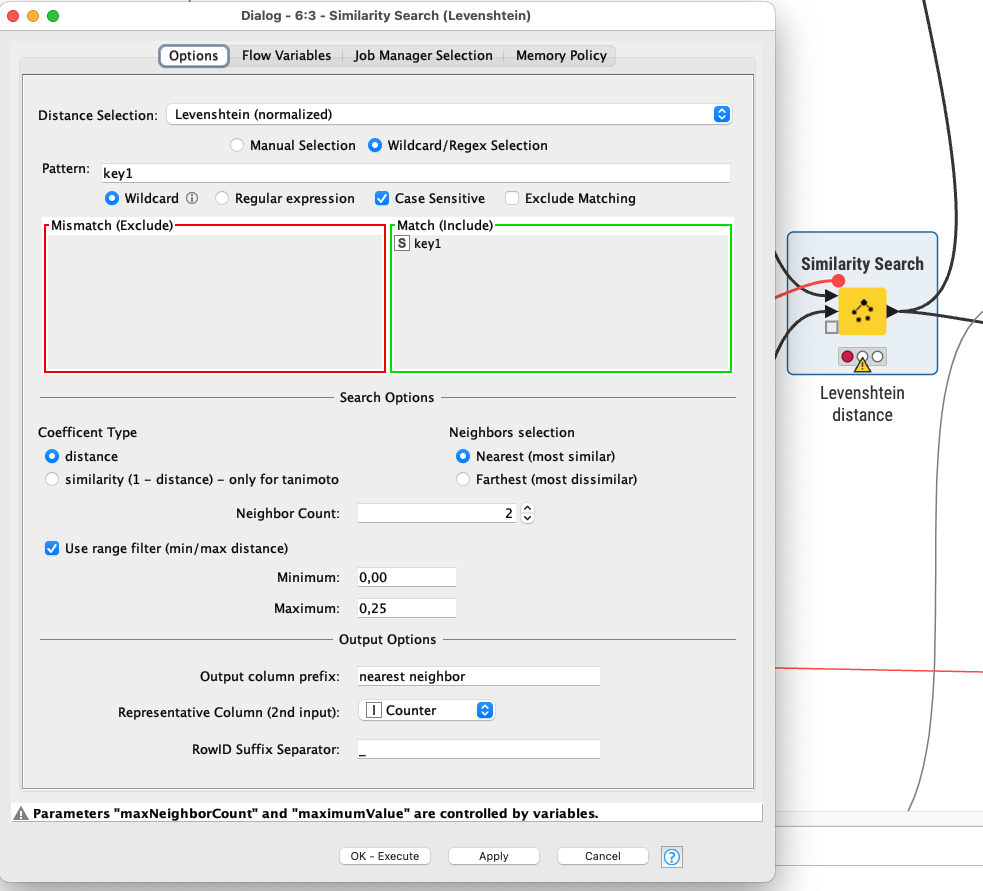
Hey @mlauber71 - I think I might have it adapted and going. Wanted to clarify the settings piece. In this case, if, say, the threshold for match is ~90% to be part of the same group (assuming the same Pincode, District, and State), is that changed in which of the following two sections:
or
I’m experimenting with the latter, but wanted to be sure.
Edit:
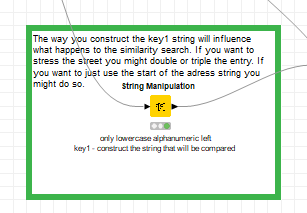
It’s clicking now - key1 is the important input, so I’ve tripled the School Name, since that is really the key driver of similarity search. The range filter then dials in the sensitivity. Values between 20 and 30 in this case seem to produce the interesting results.
So far tested and works fast for 100 rows, running it now on 200K.
@qdmt glad it seems to work. Attached to the workflow are additional links with examples and discussions about address deduplication and similarities.
And indeed it is a good idea to double or even triple the important parts of the string to give it more weight. If you have groups where you know they will be together like regions you can do the whole thing by them in order to reduce the processing load.
If you do it for example for all schools in NY instead of the whole country in one go processing time should be reduced.
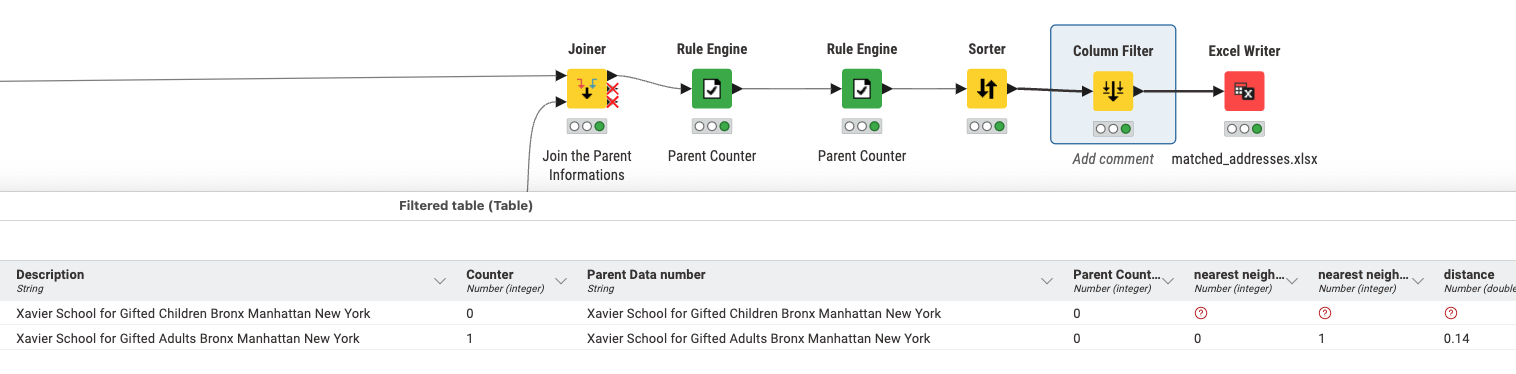
So this took about 8 hours on my system. There were ~29,000 unique regional groups, and each group had at most ~700 school names. So, employing a group loop node near the beginning and a loop end node near the end, the regional groups were cycled through over a period of 8 hours.
When I tested on a sample of 1,000 (without group loop), it only took a few minutes.
Asides from the speed, the result itself is of course on point . Thanks again @mlauber71
Hey @izaychik63 - Thanks! I’m a big fan and follower of your suggested nodes/workflows. That was one of the first workflows I tried for this topic, but will give it another whirl now that I have a good baseline.