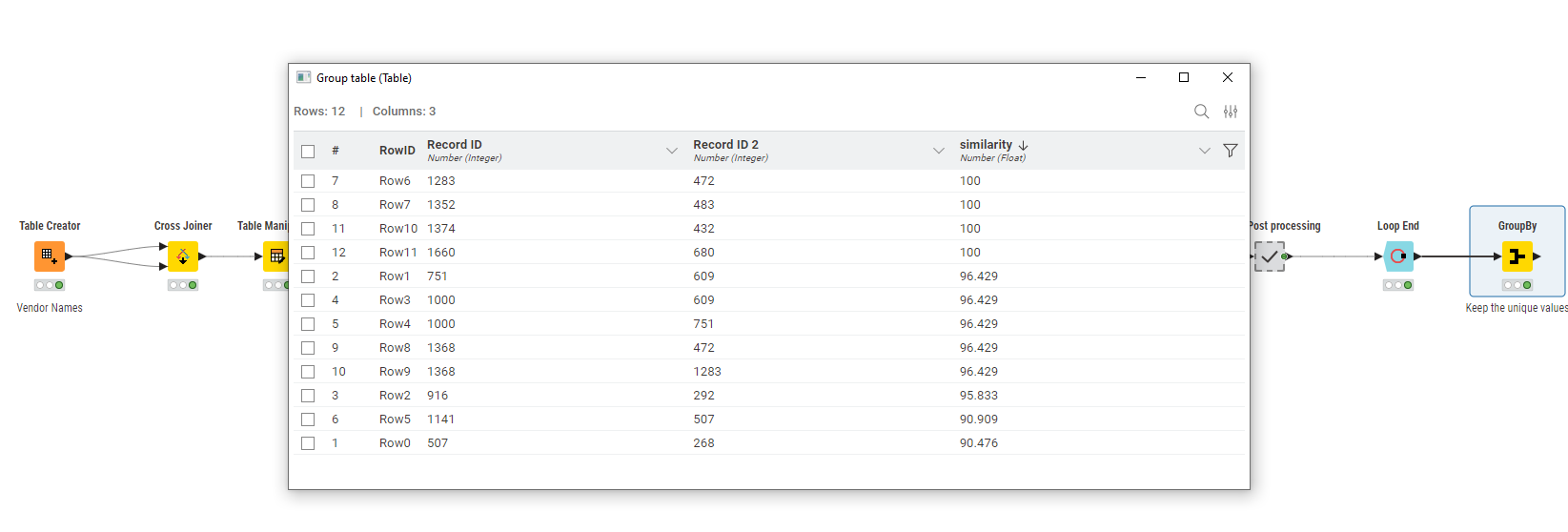
Try this. Uses String Similarity node with Levenshtein similarity measure. To use any of the similarity nodes you have to compare two strings. I accomplished this by cross joining the vendor columns. You should study how Levenshtein similarity works to make sure it meets your needs.
Thank you for the quick reply but here we have input as a Vendor Name only which you can use in your excel reader, remaining column has been derived from this input and i am having KNIME version 5.4.2 which doesn’t have string similarity node option to install
Try this. It appears that you’re trying to compare the first and last eleven rows although you didn’t explain that. If not, I’m totally lost. I also can’t understand how you expect to produce the output file other than the similarities. There’s not enough information to produce the other columns. Finally, you’ll need to install the Palladian extension to use the String Similarity node.
I am sorry in case of confusion , let me try this one and yes i am comparing vendor names one to another to see which vendor names are matching very closely.
One more time - are you comparing the first eleven rows to the last eleven rows or do you to want to compare every vendor name to every other vendor name? If the former, my second workflow should work. If the latter my first workflow does that.
@mshahn02 if you want to group similar names from a single column you could try to adapt this example where you would not compare to a ground truth.
You also might want to formulate your request in a more detailed way as @rfeigel has suggested. If you do not want to do this in English you could try in a language you are familiar with and either then translate it with a current LLM like ChatGPT or use Deepl
You can do this with the Approximate String Matcher node from the Exorbyte MatchMaker extension. It computes edit distance (or similarity) between names and lets you score & filter pairs.