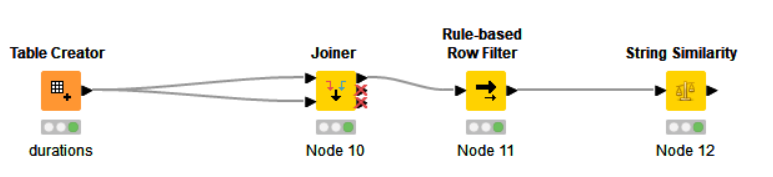
Hey Everyone,
I’m working through a problem where I’m trying to calculate similarities on one dataset of a specific column where I need two other columns already match. Specifically, I’m working with payment data, and I’m trying to identify where duplicate invoices were entered into the system but the ID was potentially typo’d via a missed/extra digit or transposed, but explicitly where the amount and inv date still match.
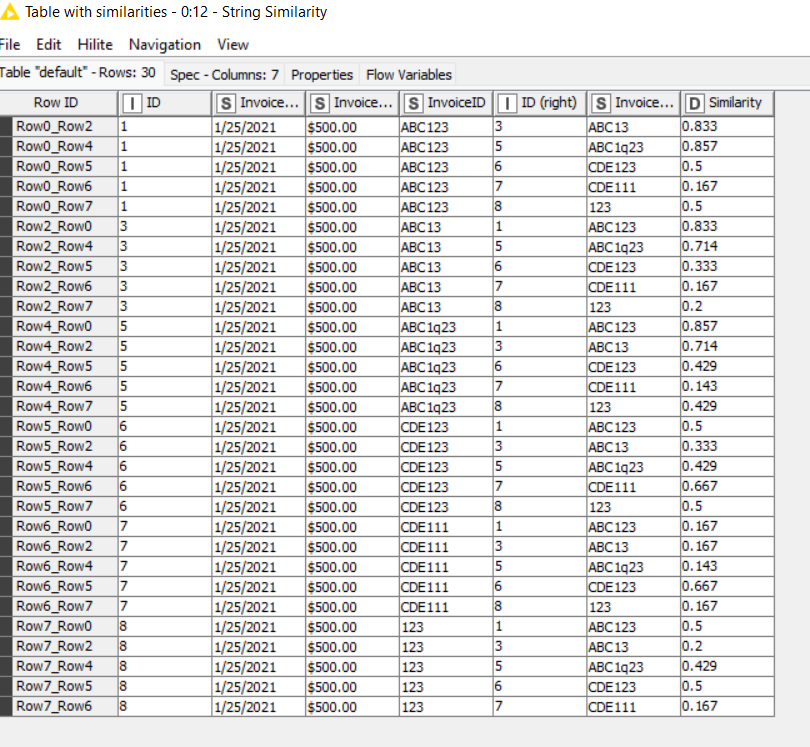
I’ve tried a similarity search where I concatenated the fields into one, however then small differences in key field would result in an invalid match
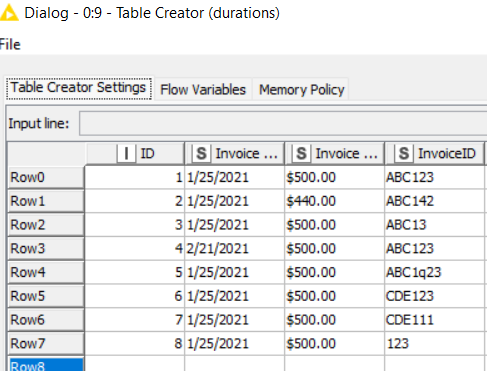
Example:
Row ID || Invoice Date | Invoice Amount || InvoiceID
1 || 1/25/2021 || $500.00 || ABC123
2 || 1/25/2021 || $440.00 || ABC142
3 || 1/25/2021 || $500.00 || ABC13
4 || 2/21/2021 || $500.00 || ABC123
For my 4 sample rows, I’d want to flag and look at the comparison for Rows 1&3, but I don’t care about any of the other combinations as the other fields disqualify them. I’m trying to build this out as a template to be reusable on tens of thousands of rows.
Thanks in advance,
Feaugh