I am fairly new to KNIME and I have been working with this tool since past 2 months now.
I have a doubt on fuzzy matching (text processing).
I have set of 600 names as a column (first name, middle name- optional and last name).
I want to get all the set of similar strings from this column. I did find few workflows which does this but it does by comparing one name of one column with another name in different columns.
I am not sure of any discussion relating to getting set of similar words from one column.
The algorithm of fuzzy search to be used should preferably be an algorithm which gives percentage of similarity like cosine similarity.
I do not have any words to compare the name field with. I have a single column with full name of people and I need to get set of similar words from these itself, so each name should be compared to all other 599 words and the set of words which are similar are to be marked as similar and those words are then checked with percentage of similarity it holds.
Kindly help me resolve this or direct me to any document/discussion which helps in the same.
Hey @natanaeldgsantos
Thanks for the quick reply!
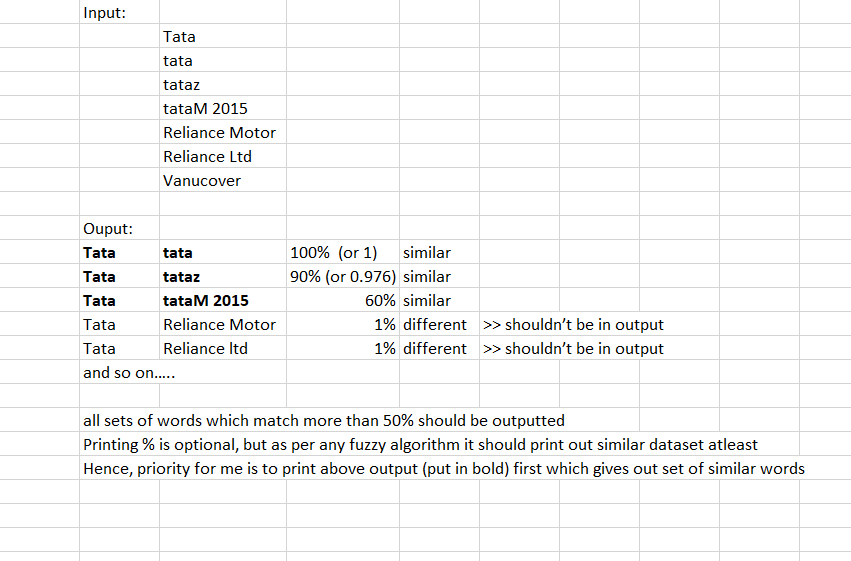
Sure I am sending it some sample data here (with very less data set).
Attaching screenshot from excel along with excel file which describes what I need as output:
This Workflow compares each register with the others, calculating the distance or similarity between them.
Always returns all similar ones above 50%
each of the algorithms is optimized to consider case sensitive when performing the calculations.
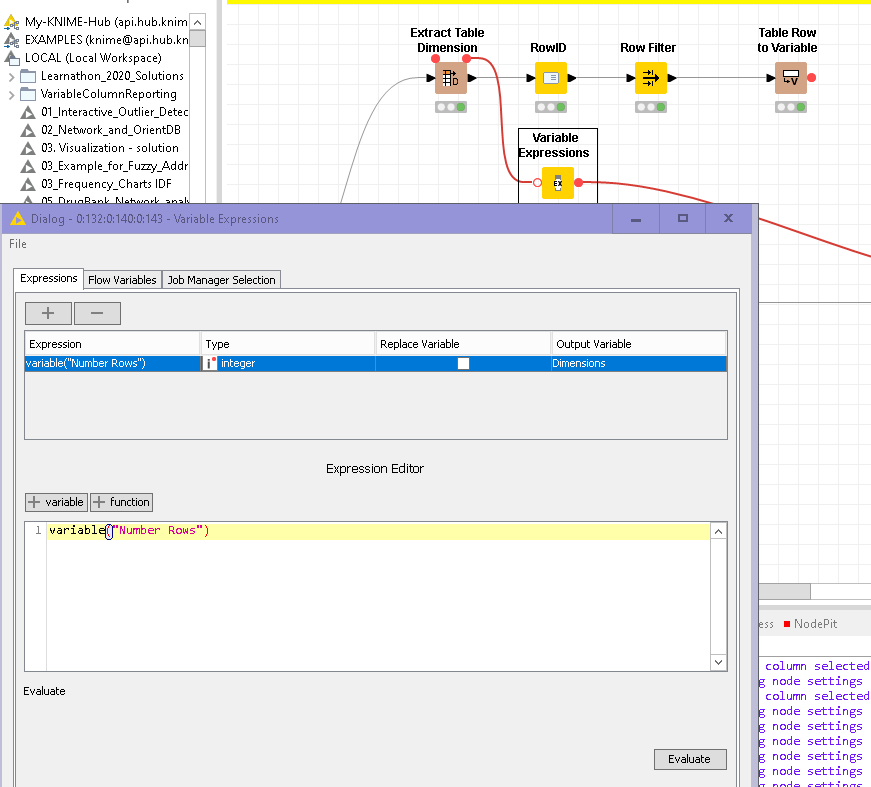
I use a flow variable to force the comparison of each record with all others in the column, assigning the number of records in the table to the “Neighbor Count” field of the Similiarity Search node.
please check if the example is useful for your need.
@natanaeldgsantos Thanks alot for the solution this helps too and also the solution given by @izaychik63 also is useful for the same and seems more simple to me
Thanks alot to all you experts!!