After reading data from CSV (or perhaps any input node), I’m looking to generate a new column with a unique ID, key ID, or a primary key for the dataset. The reason for this is to allow for the data table to be split and re-joined downstream after some work on select columns.
I was surprised not to find coverage on this topic already, so I’ve either not searched enough, searched the wrong terms, or I’m missing something blatantly simple. I realize that all three are my problem, and I apologize in advance. Any guidance extended would be sincerely appreciated.
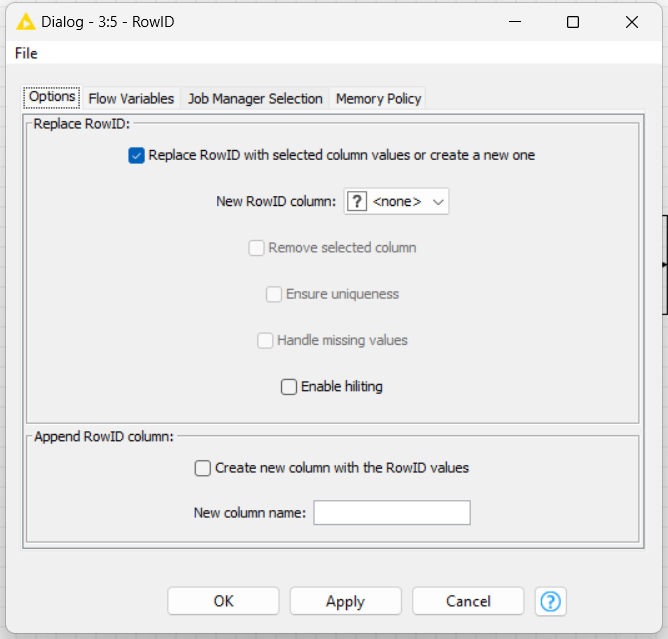
Thanks @HansS, alas - thank you. I think that should work, if I perhaps leave the first box unchecked, while checking the second box to create a new column to hard code a new RowID. Thank you.