Hi @Pippobaudo89 , the majority of nodes are unable to create additional rows, so java snippet for example will not be able to help you here.
For the situation you describe you, the “One Row to Many” node is your friend. It requires that there be an integer column present on the rows which states how many duplicates of each row to create. In your example, I’d suggest that the # of luggages column is probably an integer column which can be used for this purpose.
Typically, if you want to then create a sequence between two points, you could then use the Ranking node or similar to generate a sequence number which can then be used in some form of addition.
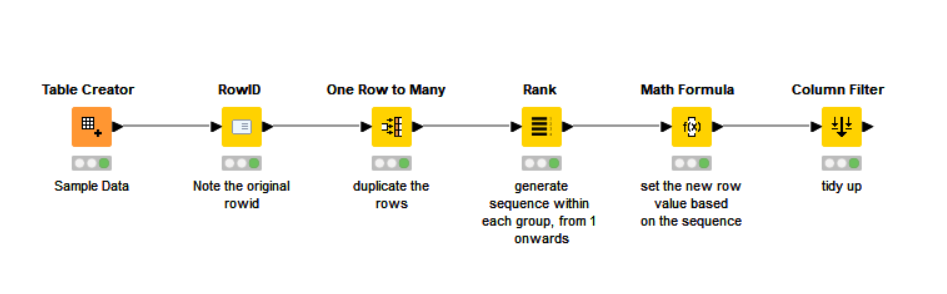
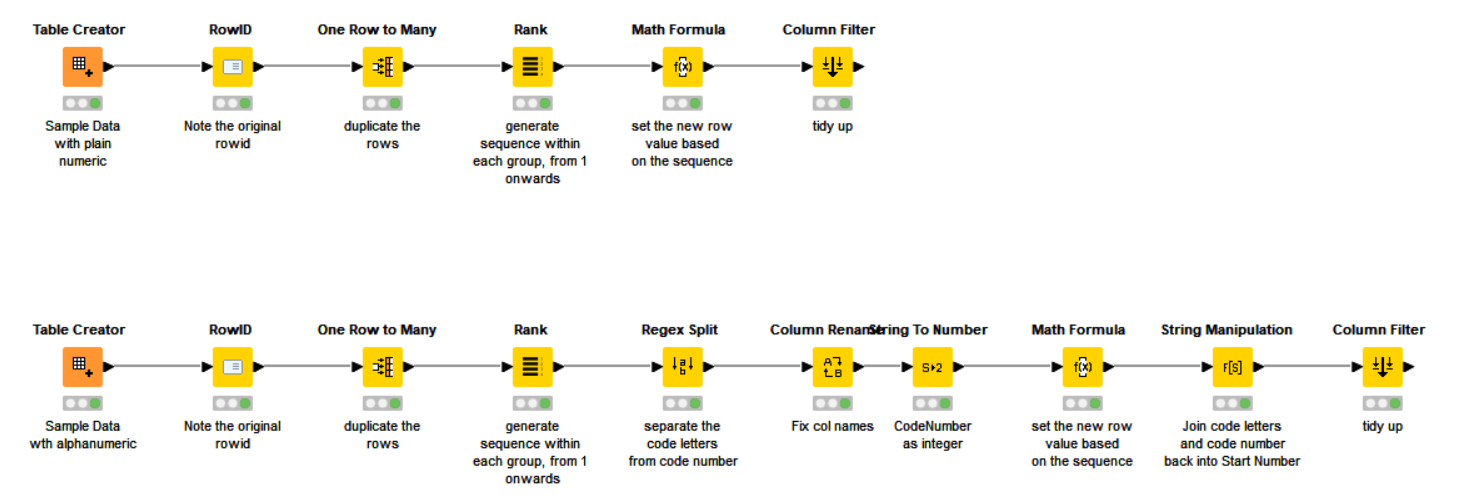
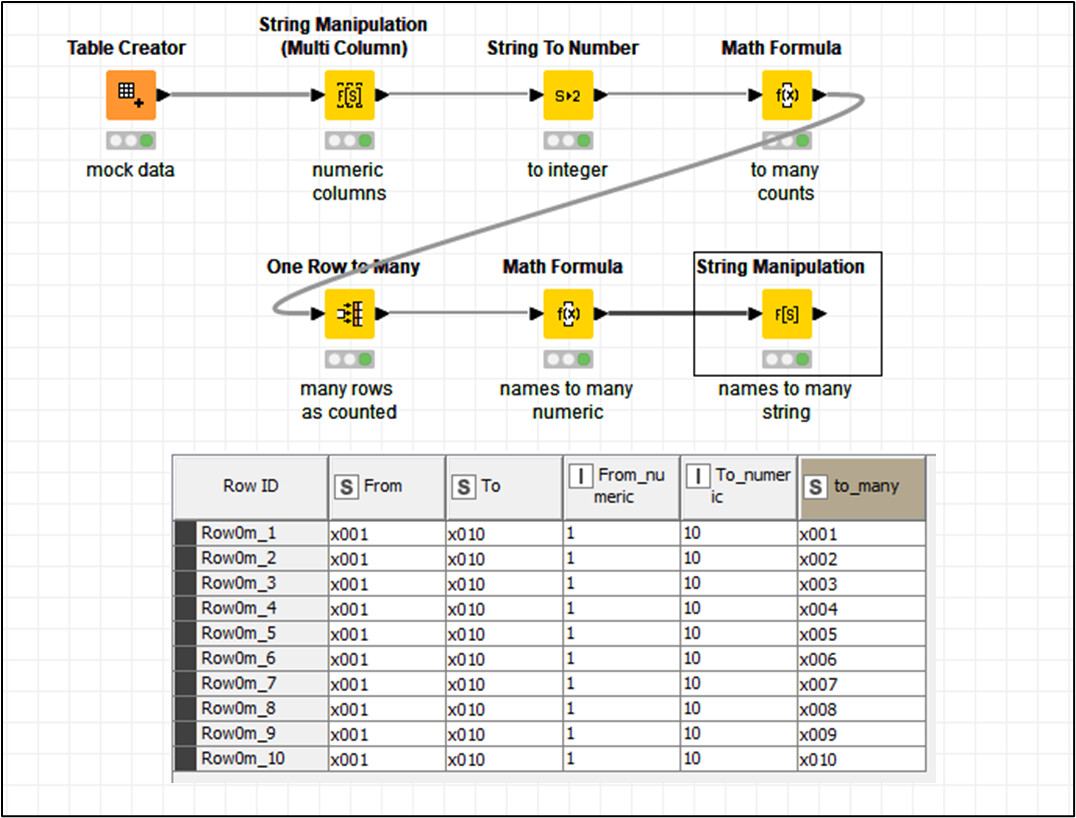
Here is a relatively generic example. (Workflow supplied)
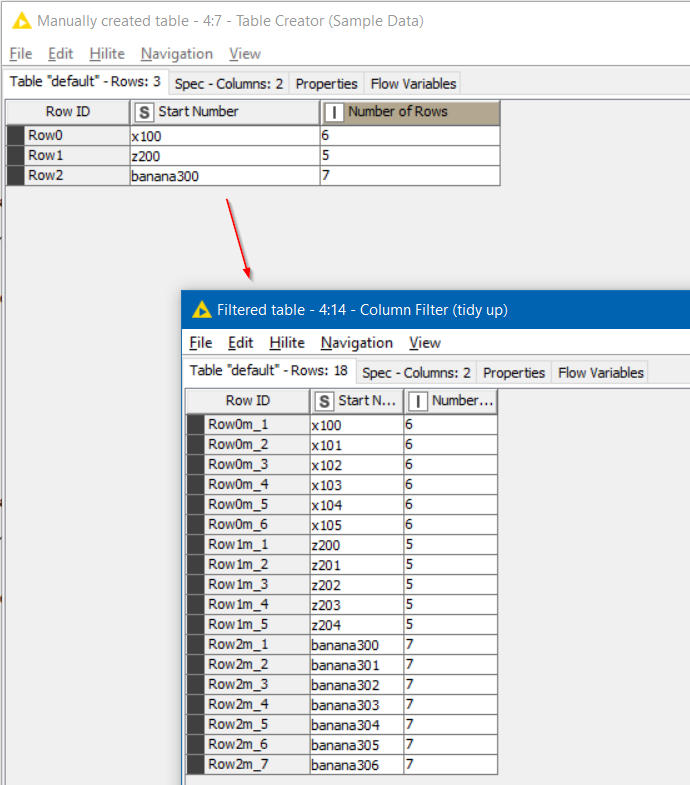
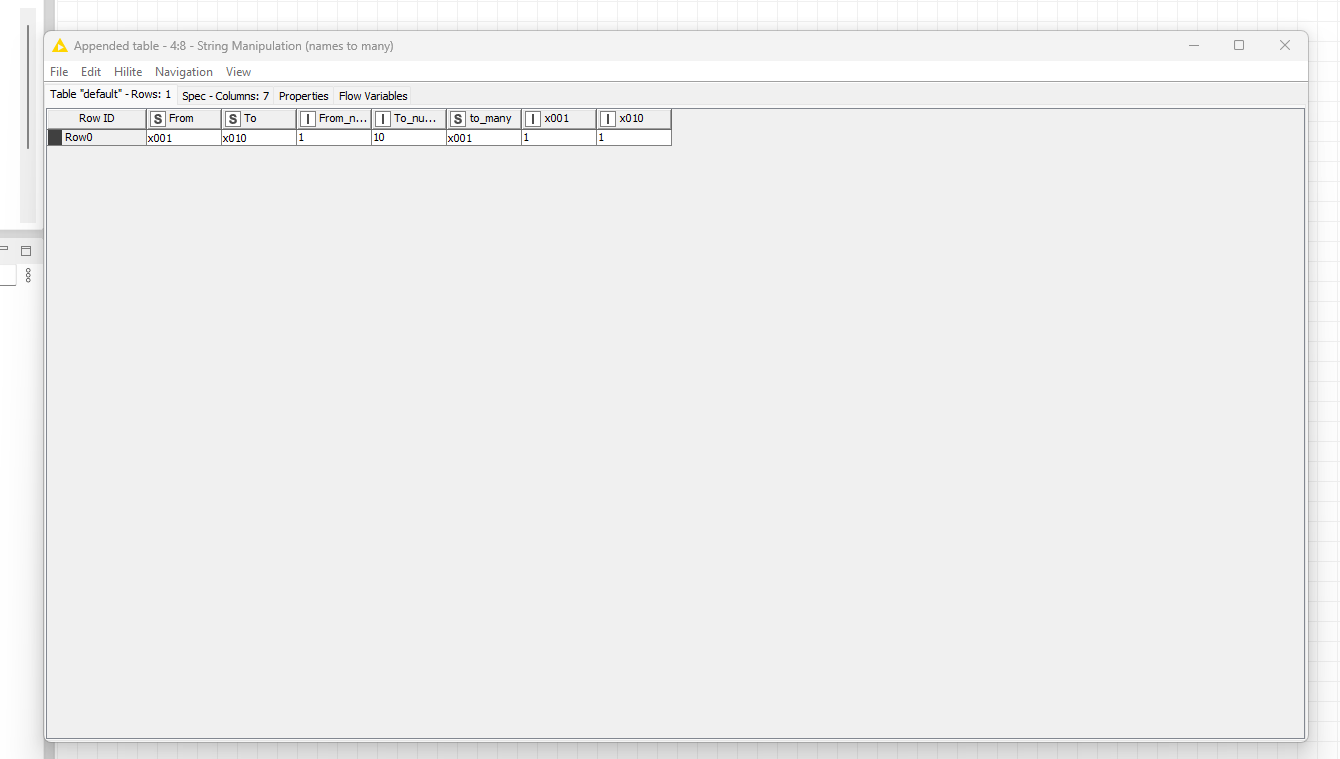
Suppose I have a table as follows

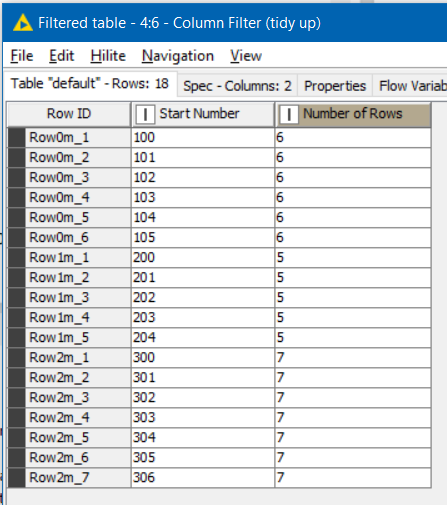
In this table, each row has a start number and the number of rows that are required. What we want at the end is for there to be extended ranges based on “Number of Rows”, so we would end up with Start Numbers 100 to 105, 200 to 204 and 300 to 306
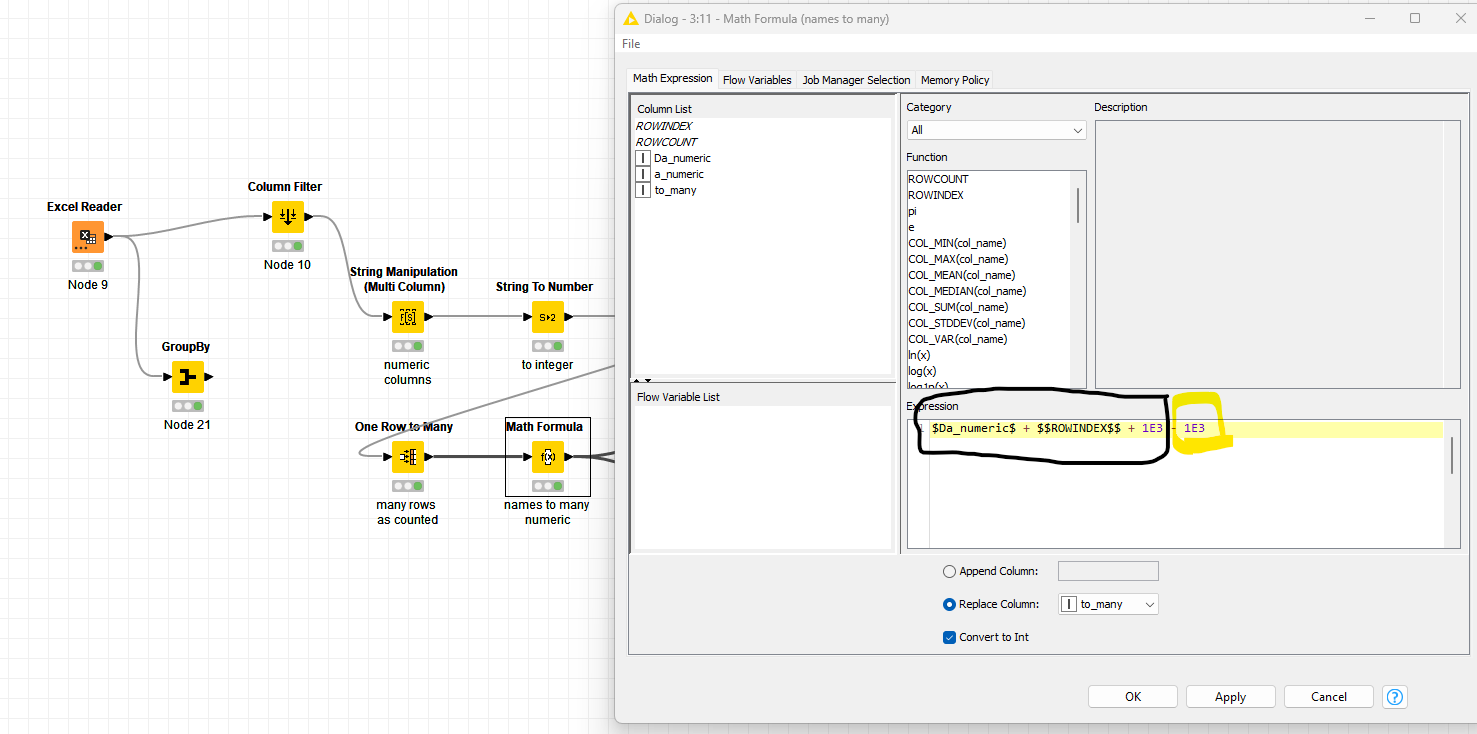
To achieve this, the following pattern can be used:
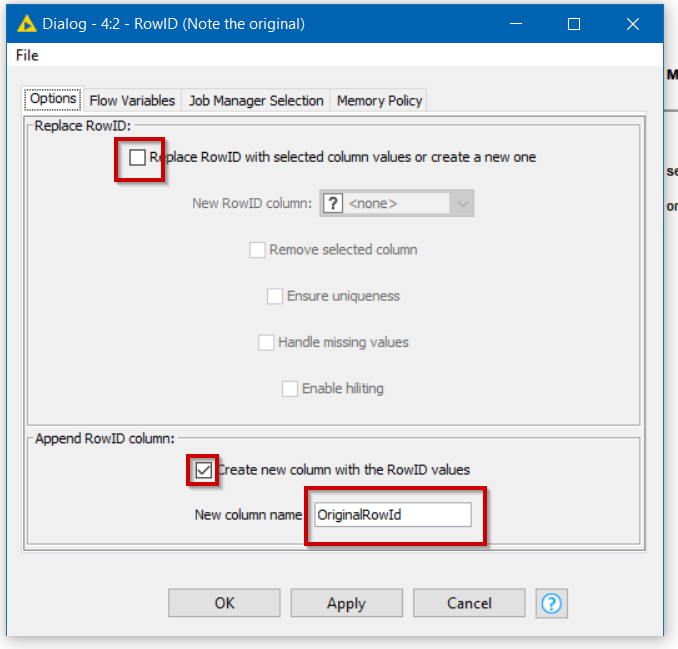
Firstly, we will need to know (later) for each row, which “group” it belongs to, so we can use a Counter Generation to give each row a number, or we can, as shown here, use the RowID node to make a copy of the current rowid in a new column “OriginalRowId”
After that we tell it to duplicate the rows using “One Row to Many”, and specify that the “Number of Rows” column (which must be an Integer column for it to be seen by the node) is to be used to determine how many duplicates of each to make. A value of 1 would mean “do not duplicate” as it identifies the number of rows for each that will be present at the end of the operation.
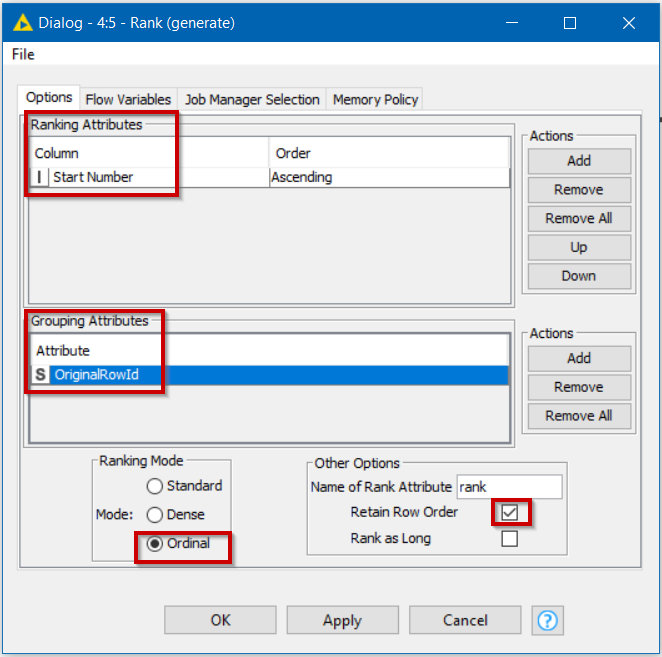
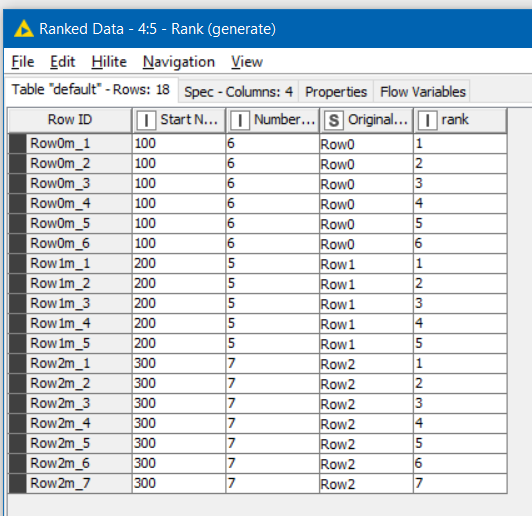
Next is the ranking node. It is also possible to use Moving Aggregation here, and many people find it preferable. I am demonstrating the Rank node here. The warning with the Rank node is that I find it buggy to configure. You can sometimes (often) find that it doesn’t properly detect the available columns during configuration, and no end of reset/execute fixes it. Even during writing this demo, I found I had to delete the node, execute the node prior to it so that the columns were present, and then re-add the Rank node before it allowed me to choose the grouping column. However, once configured, it works well.
The rows are to be grouped by OriginalRowId, and the Start Number can be chosen as the “ranking column”. It doesn’t matter which ranking column is chosen, because at this point within a group they all contain the same value. You must specify a column, though, so this will do!
Make sure the Mode is set to Ordinal which will give you an ordered sequence beginning at 1 for each group, and I have told it to retain row order (although that probably doesn’t matter in this case).
The result of this is the following table:
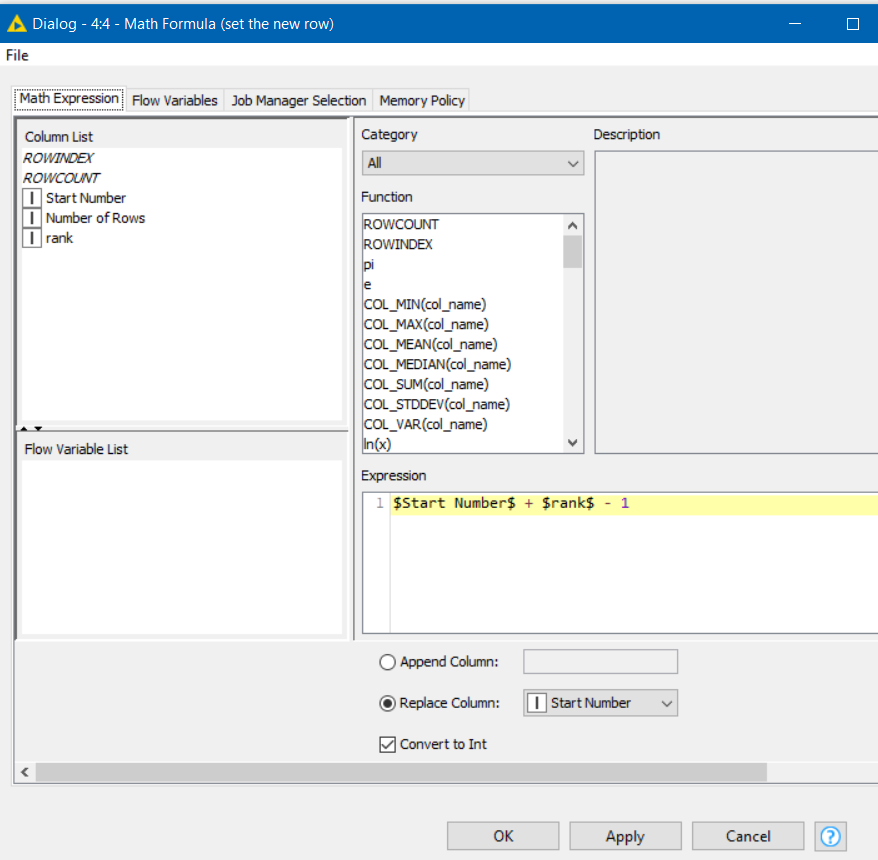
You can now do a calculation for new values of the Start Number, using the rank column on each row. So the new start number for each row will be Start Number + rank -1, to keep the first row in each group unchanged. This can be performed with a Math Formula.
After a column filter tidies up the required columns, the result is the required output as shown above.
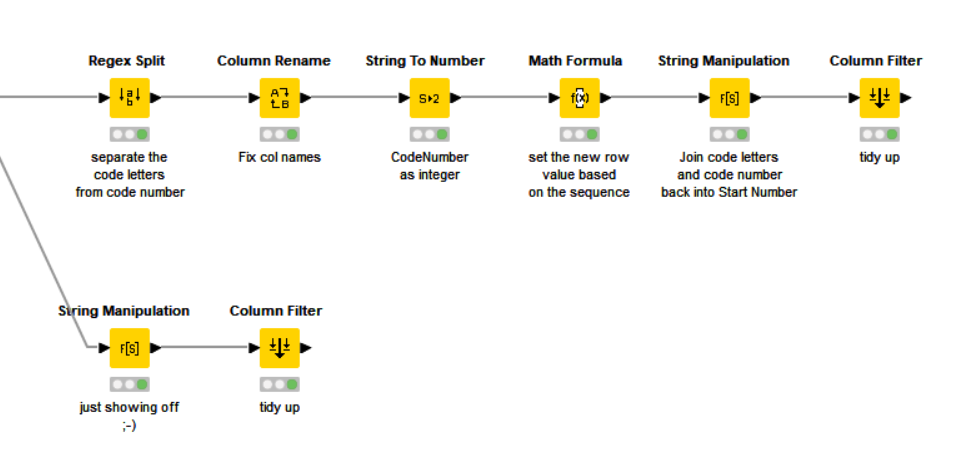
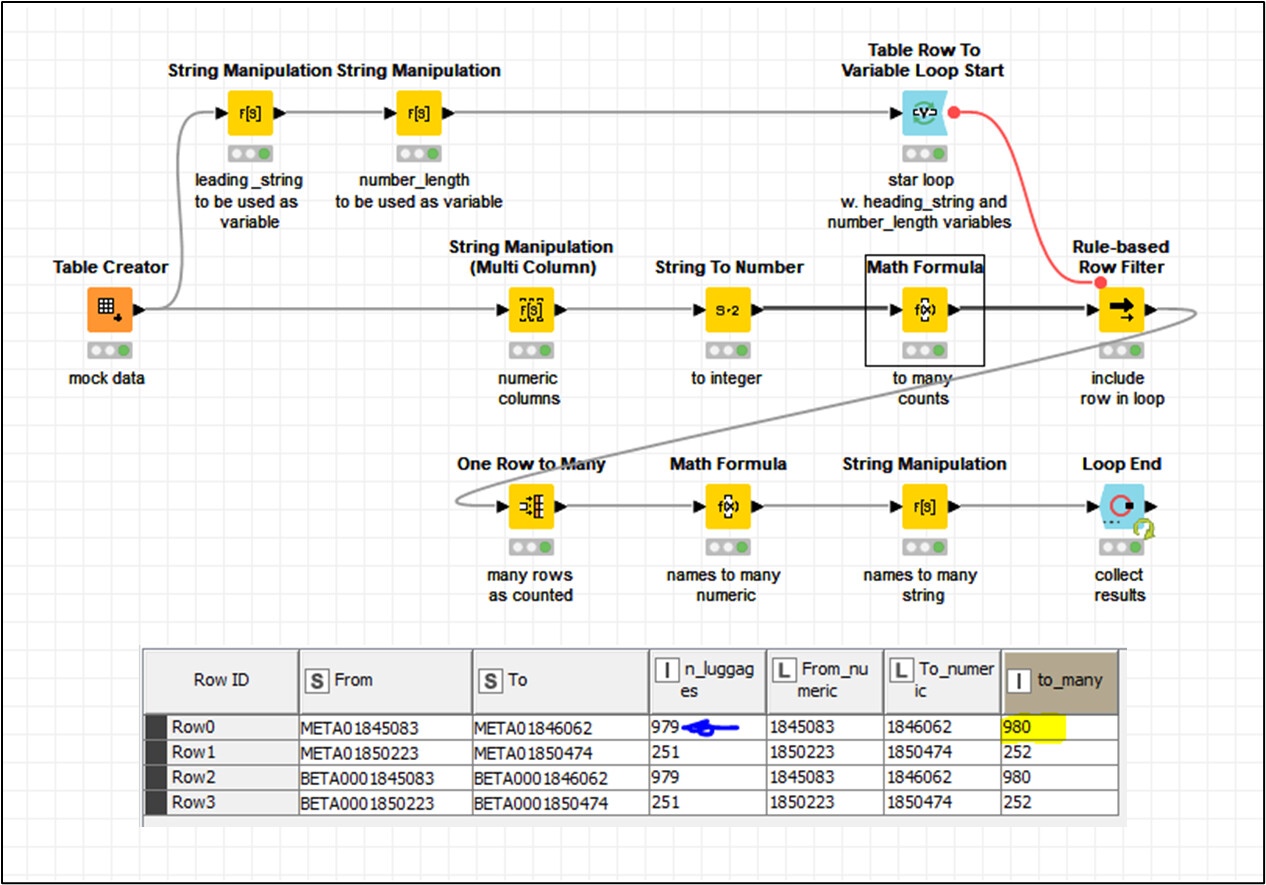
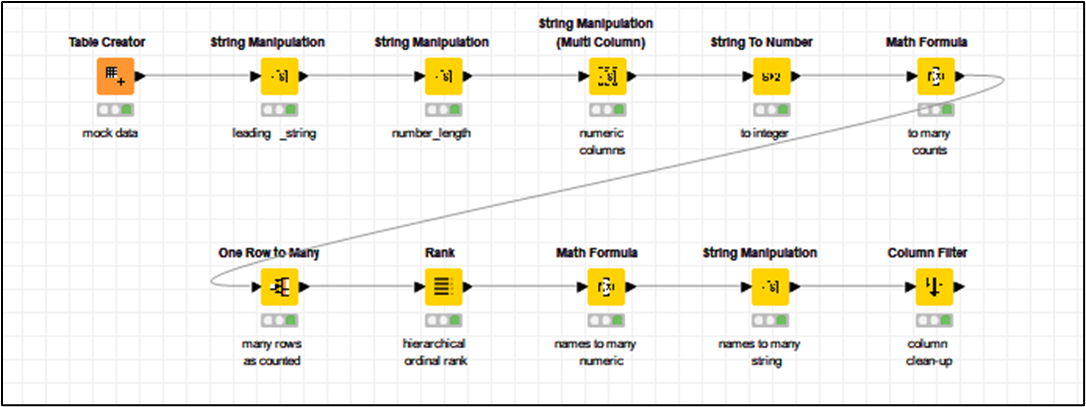
Dealing with Alphanumeric codes such as yours follows a similar principle, but you will need to perform additional manipulations on the string because you cannot just add to it with a Math Formula. There are a number of ways of achieving this, but I have included here a sequence of nodes to demonstrate one way of performing this:
The upper branch is the “numeric” version detailed above.
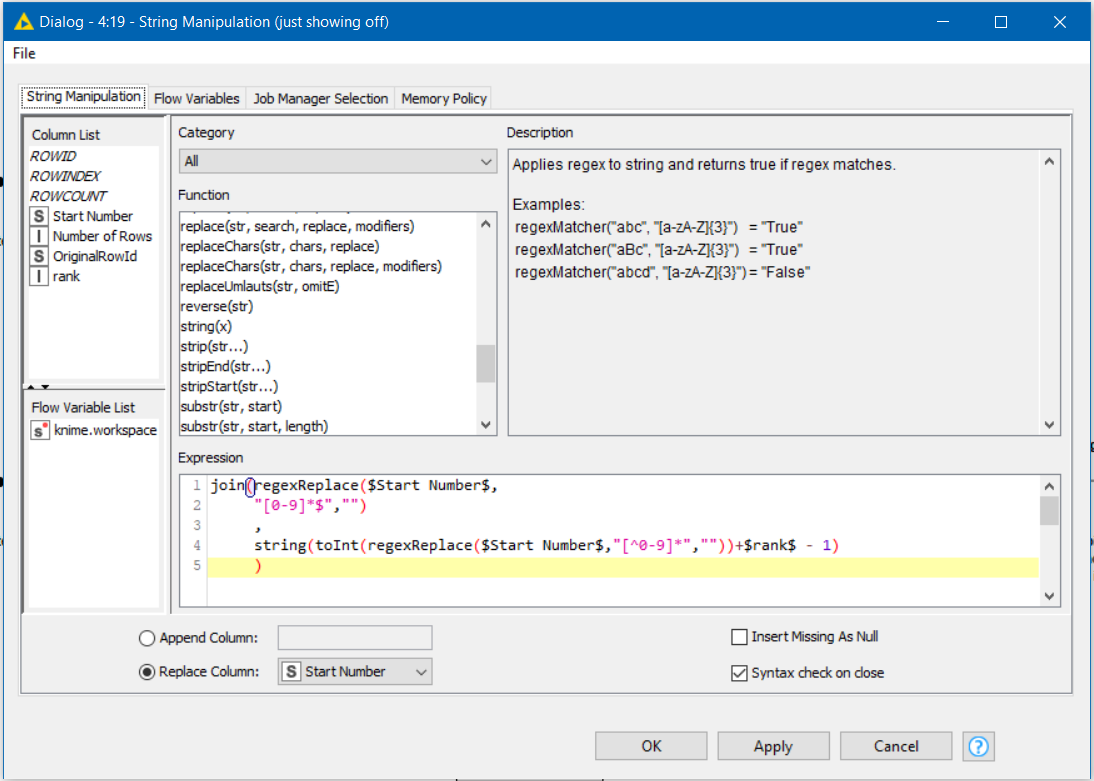
The lower branch contains additional manipulation of the string, which if you read through the nodes will hopefully be reasonably explanatory.
In this example, it was important to “retain row order” within the Rank node, because otherwise it reordered by “Start Number” in alphabetical order, resulting in “banana” codes appearing first. 
I hope that helps give you some pointers
Forum - build a sequence of rows.knwf (34.5 KB)