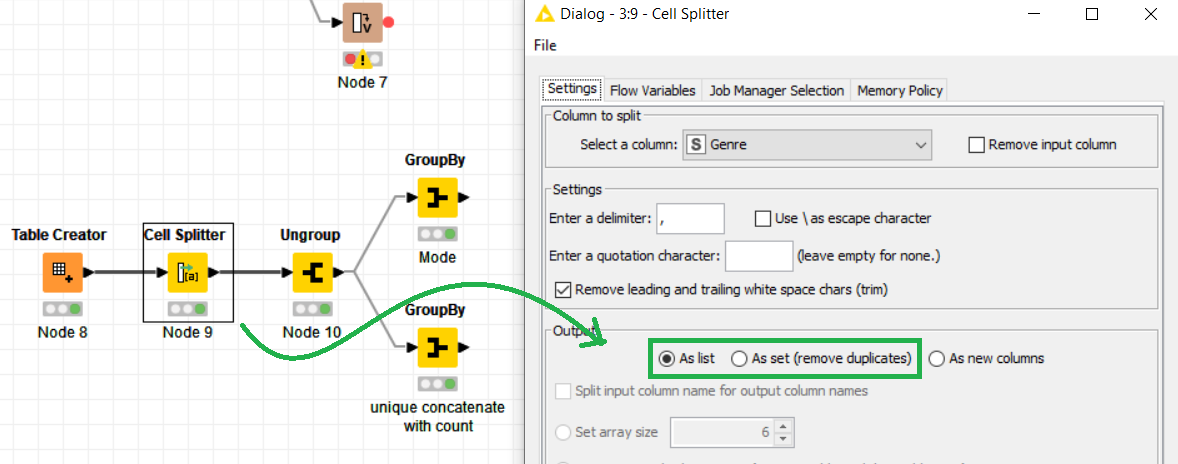
Hmm, for finding the most common genre it’s actually more efficient to not split the entries into multiple columns, but rather create a set (or list, doesn’t matter since there shouldn’t be any duplicates).
This set can then be “ungrouped” into multiple rows.
Finally, we aggregate the columns containing the split results. If you want the most common genre, using “Mode” is exactly that, otherwise you could also use “Unique concatenate with count” to count all occuring genres.