I’m new to Knime, so hope someone can help with a rather basic question.
I’m working with IMdB database. In the Genre column there are sometimes multiple different genres. By using the Cell splitter i now have separate columns for every genre that a movie might have. Now i have to find out which genre is more common. How do i do that?
I’ll do a speculative guess though:
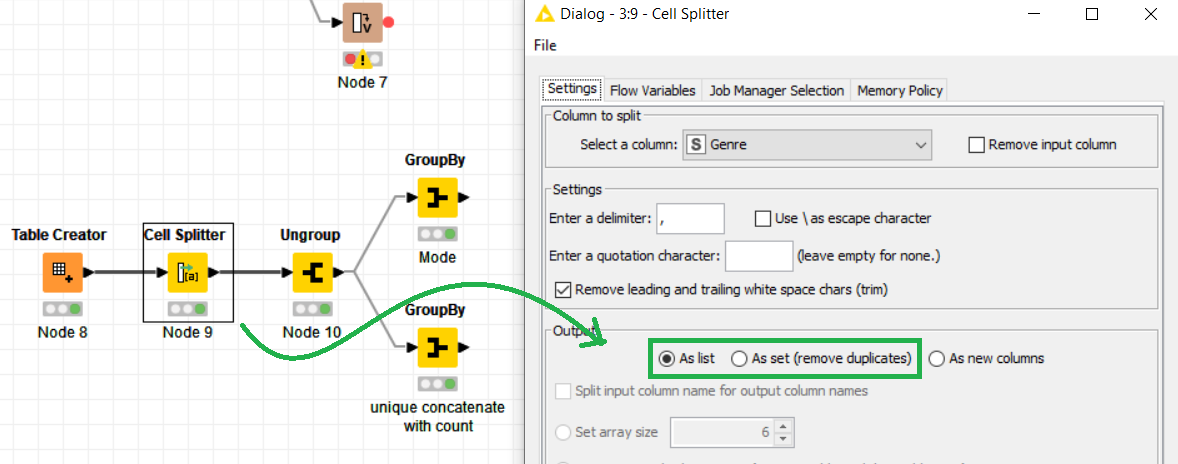
Set the Cell Splitter to “List” or “Set” instead
Ungroup that List
GroupBy (genre as group column, aggregate any column with count)
I’ve put my CSV file in a file reader, used the Cell splitter to break up the genre column (on imdb a movie can have multiple genres), and now I have to see which genre is more common.
As I wrote before, i’m just getting in to it so it’s rather basic.
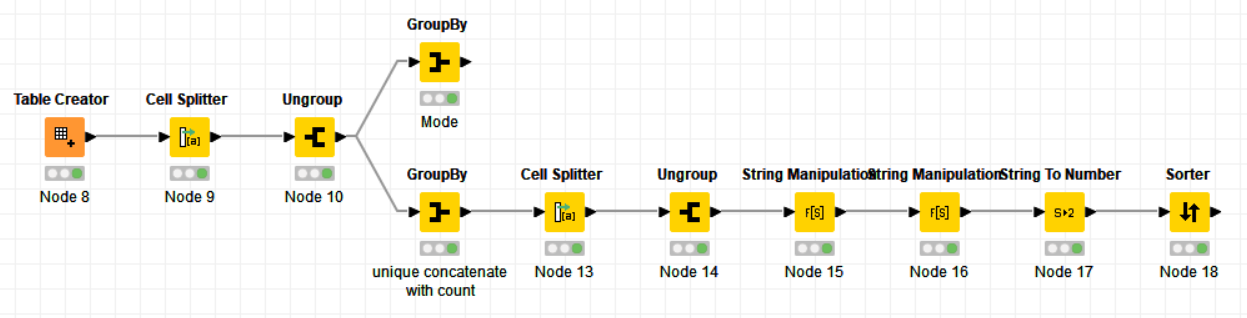
Hmm, for finding the most common genre it’s actually more efficient to not split the entries into multiple columns, but rather create a set (or list, doesn’t matter since there shouldn’t be any duplicates).
This set can then be “ungrouped” into multiple rows.
Finally, we aggregate the columns containing the split results. If you want the most common genre, using “Mode” is exactly that, otherwise you could also use “Unique concatenate with count” to count all occuring genres.
It’s order of appearance. To sort the results, we’d have to do another Cell Splitter, Ungroup. Then some string manipulation to get the frequency so we can sort by that.
This get’s you the genre name (everything until the first round bracket):