I have been breaking my head over this for days. I need to do a store-level inventory analysis on a retail chain. The API allows me to query either:
SKU+ZIP+100 mile radius - returns all stores and their respective inventory level
Sku+StoreID - returns just that stores inventory level
There are about 2278 SKUs and 1473 Stores.
Right now I am using a cross-join to create API Calls:
?storeId=X&skuId=Y
which gives me 3.3 Mil API calls which is too much!
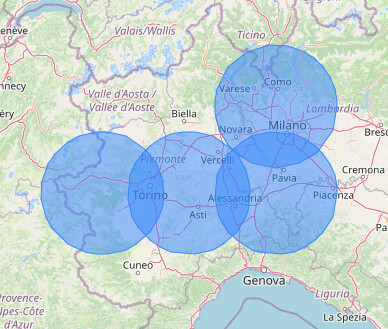
There must be a logical way to go through the store table and do some kind of calculation or grouping that eliminates all stores that are within 100 MIles of each other so that I can query the API based on the zip plus distance and that will include all stores in that radius.
For example, Los Angeles has 30 of them within a few miles, I know that I only need 1 zip code. However I also know that BumbleF#ck, Ohio has only one store so i need that zip code.
Something like:
Cluster all zipcodes that are based on their lat long within 100 miles of each other. My data shold allow that:
storeId|Zip|State|Country|Lat|Long
800460|6082|CT|US|42.00017|-72.582508|
Thanks, the cross-join works for now, but it creates way too many API calls. We still really need to find a way to reduce the calls. I think the above makes sense. But how do I eliminate the ones I don’t need?
Like Select Lat,Long from tables Group by 100 Mile Radius…
I think with a crossjoin, for each row, you have two points with Lat and Long. So, you can follow @danielesser aproach.
You can use Palladian nodes Latitude/Longitude to Coordinate to convert to coordinates.
2 Each one creates a Coordinate field. So you put them in paralel and join them later by RowID.
3 Calculate their distance with geo distance (Haversine Distance) and Column distance.
Afterwords you can filter for distances less then 161 kilometers
Or you can use this component:
If you attach your current workflow and post a sample of your input data, I can try a look.
Br
I have adapted an exercise from the “Center for Geographic Analysis at Harvard University” hub folder to (hopefully) meet your needs.
Here’s the strategy:
Get full list of stores + ZIP codes
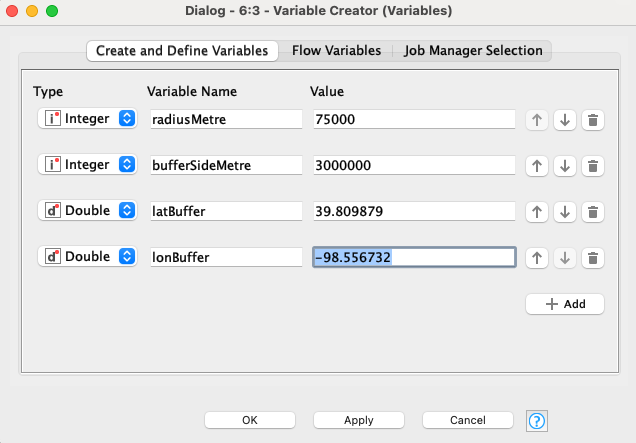
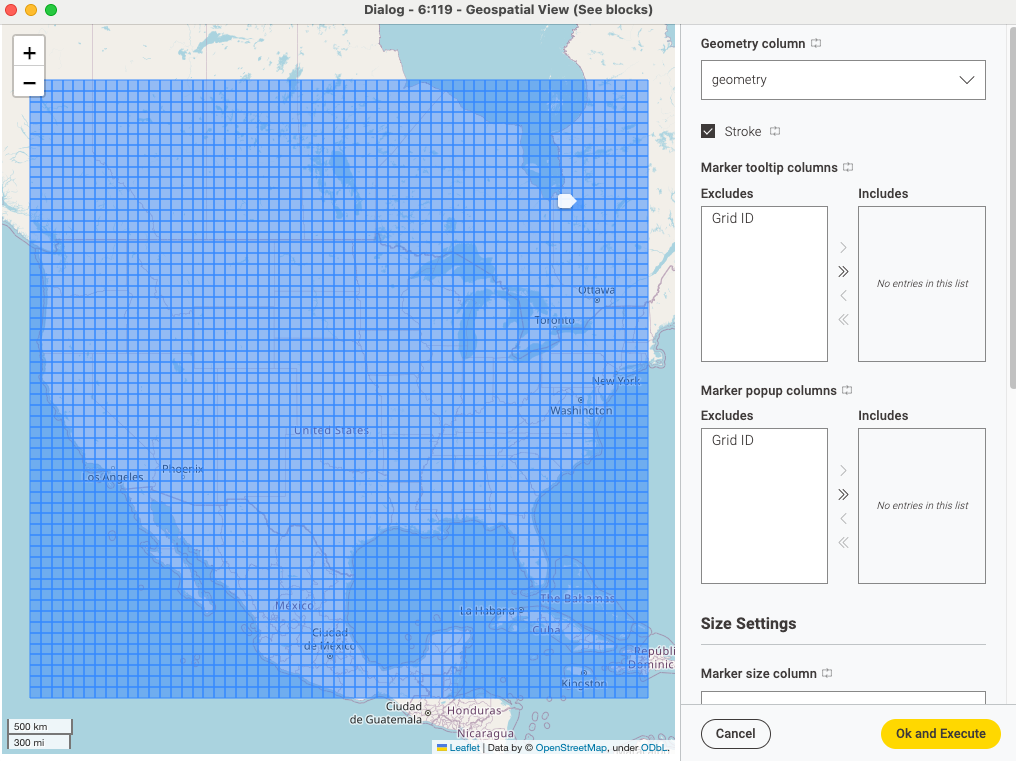
Make a map that is bigger than your covered area and divide it with a grid
Make a spatial join between the grid blocks and the stores, so you can see which blocks of the grid contain stores and which not
Compute the centre for each grid block and see which is the closest store to it; then associate the ZIP code of the nearest store to each block
Now you’ll have a list of ZIP codes that you can use with your cross joiner node and you will be able to reduce the number of API calls
Here is my solution:
Keep in mind that since the research area is a circle, there might be overlapping areas and one store result can be several times: you need to remove duplicate results if you use this method.
Hope it makes sense! Keep in mind I have used the metric system, so you might want to adapt it to your case.