I have a dataframe with hundreads of thousands of rows, and seven columns.
I know that some rows match for all the seven columns (they differ on the rowID).
I want to extract a list of all the rows that are matching. Not sure how to do this.
I have a dataframe with hundreads of thousands of rows, and seven columns.
I know that some rows match for all the seven columns (they differ on the rowID).
I want to extract a list of all the rows that are matching. Not sure how to do this.
Hi @RoyBatty296
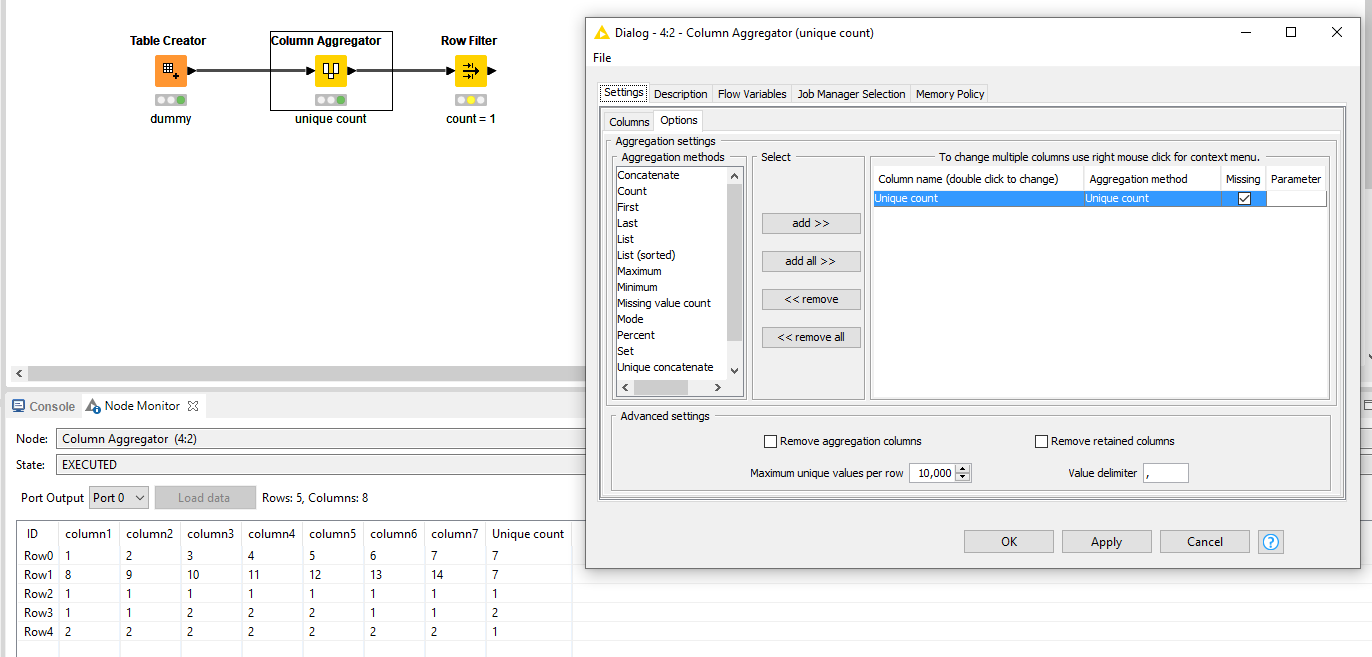
I would opt for a Column Aggregator node and use the Unique Count aggregation method. Where the count = 1, all seven columns contain the same value.
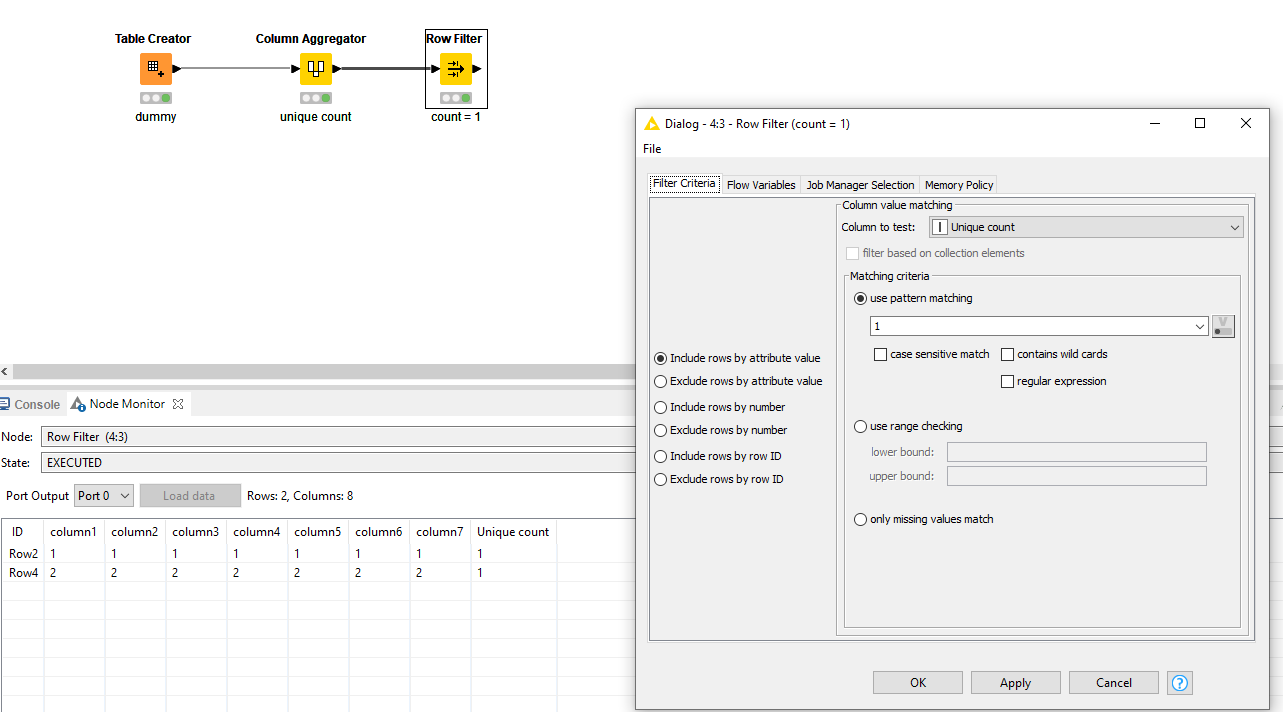
You can filter this quickly with a row filter.
Thanks @ArjenEX . I didn’t explain myself correctly in the question.
Which implies that you are looking for something different? In any case, it’s always beneficial to provide some sample input and drafted expected output to avoid this back and forth.
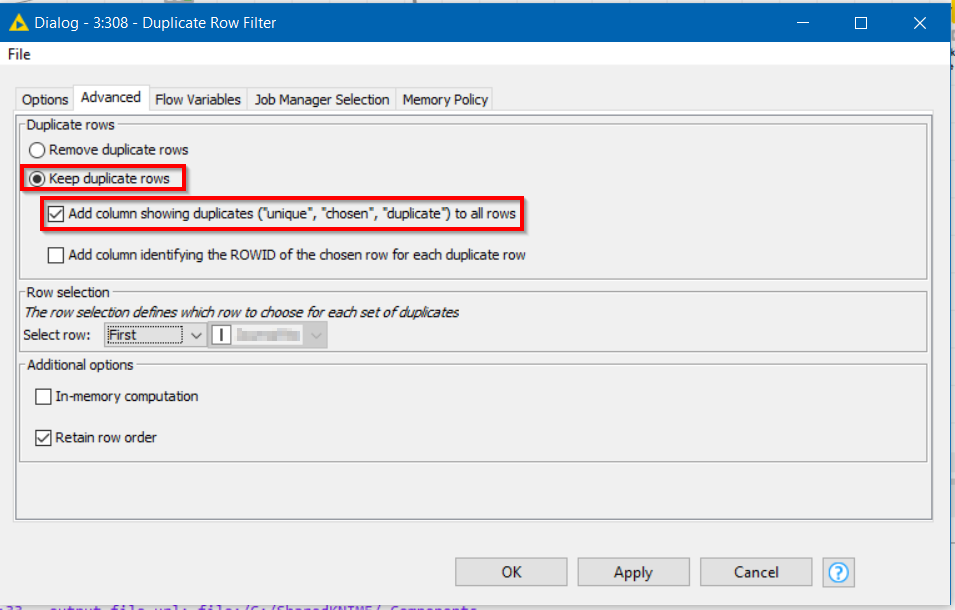
Hi @RoyBatty296 , so are you saying that you have a single table and you wish to find rows that are duplicated on those seven columns?
If so, use the duplicate row filter. Specify the seven columns of interest, and on the advanced tab, choose the following options:
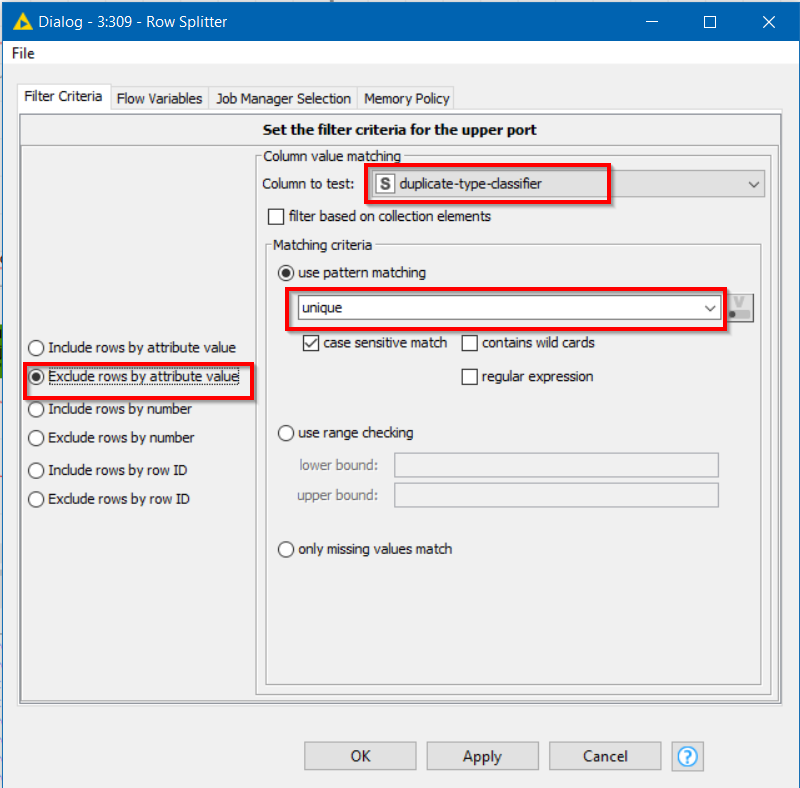
Follow this with either a row filter or row splitter, and for the filter criteria specify the following, to exclude those rows that are unique (i.e. don’t share the selected columns with at least one other row):
This will exclude those items that are unique, and retain the ones that are either marked as “chosen” or “duplicate”.
Those marked chosen or duplicate will be all the the rows which share the seven columns.
If that still isn’t what you are after, then as @ArjenEX says, you will need to be more specific and preferably give an example of data and the required output.
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.