Hi @tb_g_23 ,
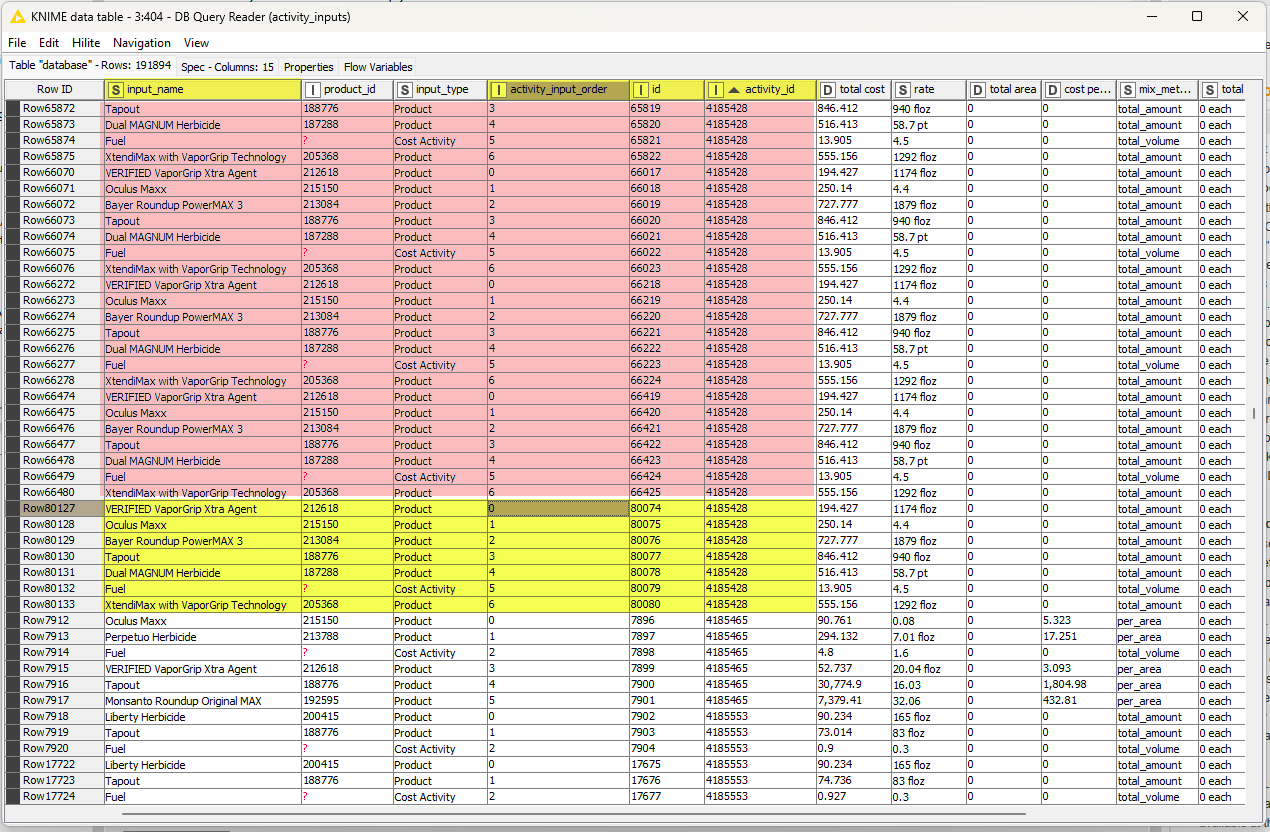
I’ve had a re-think and a re-read. I hadn’t spotted the additional features of your data, and I generally find it easier to analyse actual sample data rather than screenshots. 
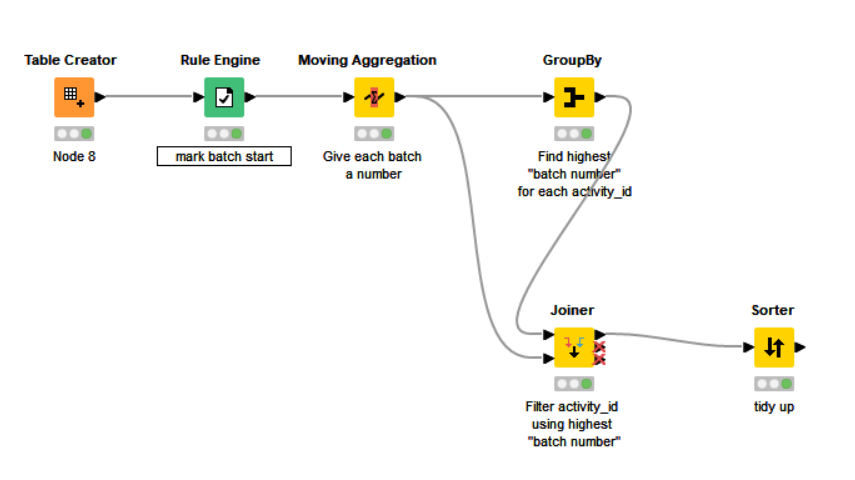
OK, so if we are to assume that every batch is marked by having an initial activity_input_order of 0, and that they are listed in ascending order, so that they batches are always grouped together in your data, with you data in id order, then this becomes a case of marking the batches, and a fairly common way of doing this in KNIME is by marking batch-start (activity_input_order=0) with a 1, and all other rows with a 0.
After this, a moving aggregation can be used to “cumulatively sum the ones”.
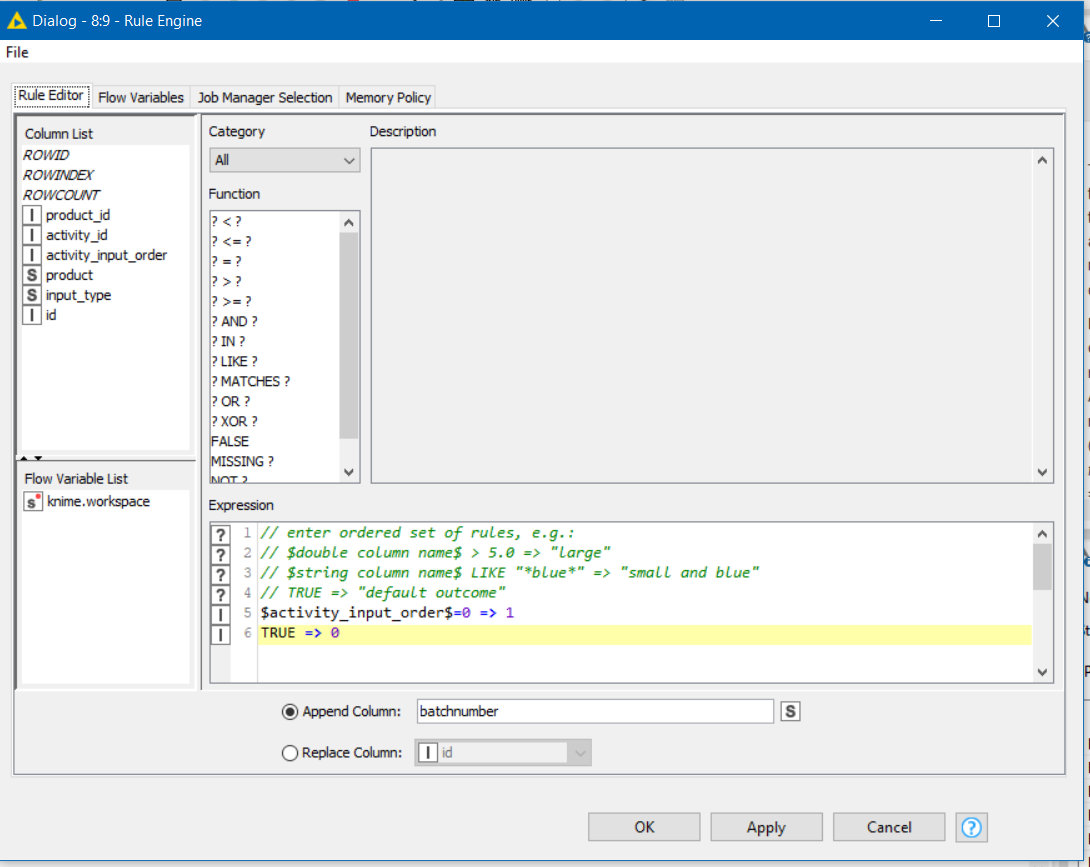
Start with a Rule Engine
$activity_input_order$=0 => 1
TRUE => 0
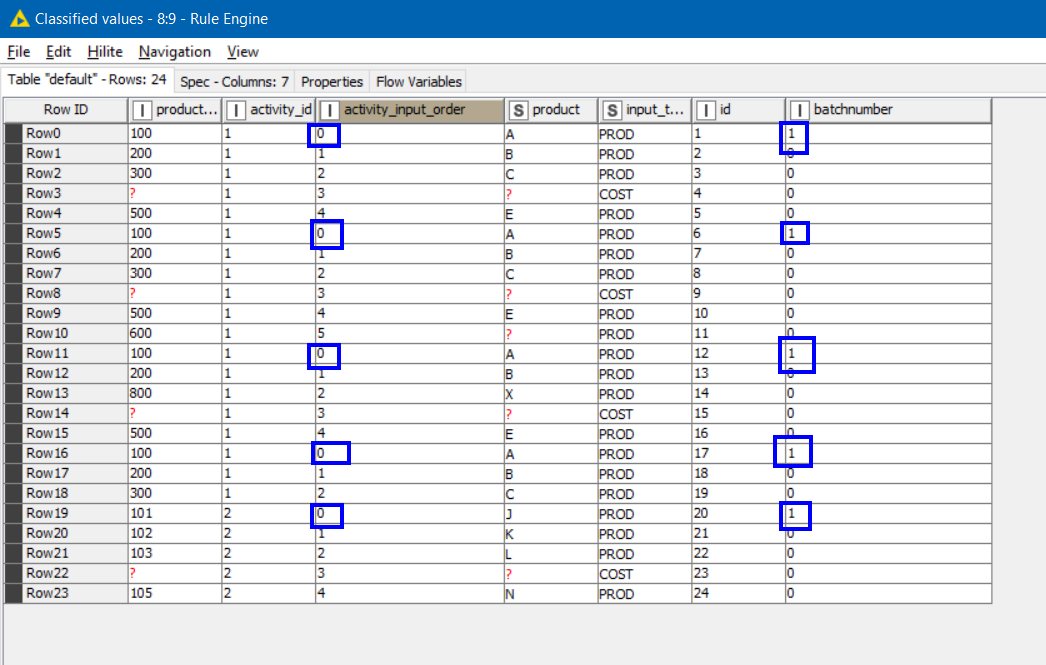
This is creating a column named “batchnumber” and the effect of this will be the following:
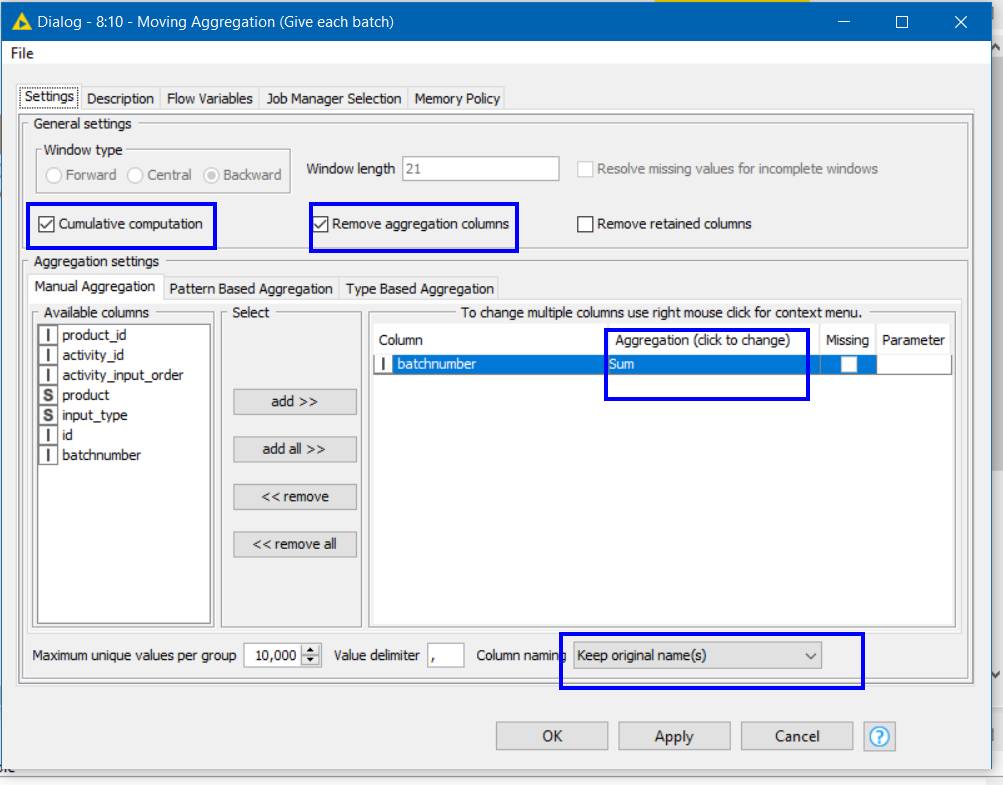
After that, a Moving Aggregation will cumulatively aggregate the batch numbers.
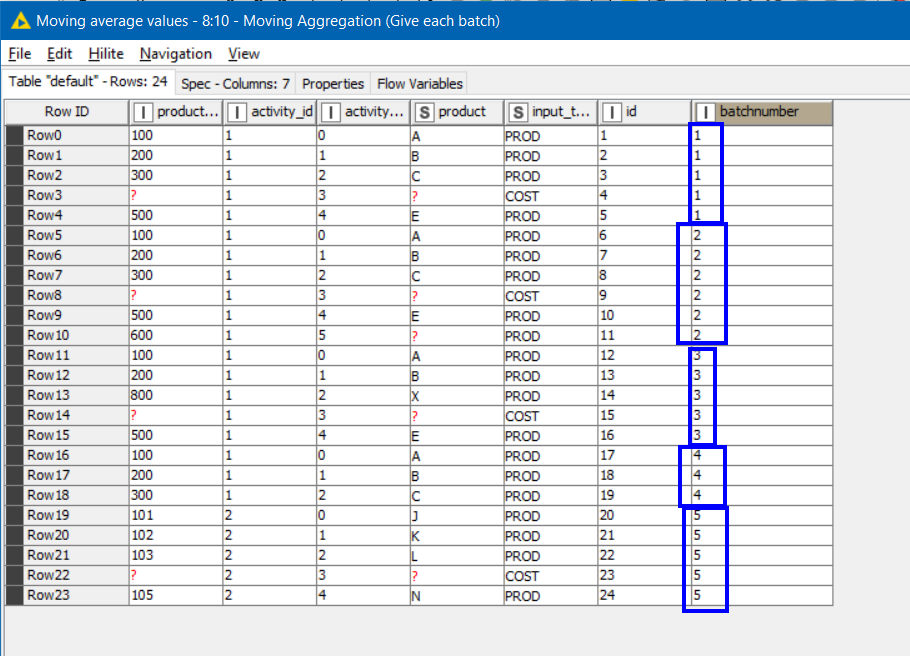
which generates the following:
As you can see this has now assigned a unique value to each “batch”
Following that, a group by can then be used to find the maximum batch number for each activity id, and then join back using the max batch numbers
Grouping Batches.knwf (19.3 KB)
Hopefully that gives some ideas. If it still doesn’t quite work, please upload some sample data that we can have a play with.