Hi,
I try to create a flow which does this: Get data via an API GET REQUEST and update an TABLE in an MS SQL SERVER.
However some additional info to this:
I want to do this for multiple tables
Each Table concerns >100000 records and approx. 100 columns, sometimes less, sometimes more.
Currently I do this (high level process, obviously there are more little steps and tricks in it)
Get JSONs with GET Requests > Transform them to KNIME tables > insert the records into the DB Table.
I have these questions high level questions:
currently I experiment with the parallel chunk option to speed up the GET REQUESTs. > With this I result in a table with >100 rows of sub JSONS (each concerns about 1000 records) > What would be the best solution to get these >100 JSONS into the same SQL Table using the above general process.
is there a smart solution to get JSONs directly into an existing SQL table, without processing that amount of data into KNIME-Tables? E.g. using OPENJSON SQL statement or so, which I struggle with, as I do not know how to put this?
is there maybe a much smarter way, using KNIME, to get data from an API Table into an SQL Table, considering the amount of data is >100000 records with 50 - 200 columns?
If the questions are to broad, I am happy to adjust.
Hi @d00m , I would say there are 2 general ways to do this:
Process everything in Knime and write to DB;
OR
Process “everything” on the DB side.
To process everything in Knime, you would have to download all the json (GET REQUESTs), transform into table via Knime’s nodes (JSON to Table, etc), and once your data is ready in a table, write the table to MSSQL.
If you want to process everything on the DB side, you would still need to download all the json data first, then just write the json data as raw to a temp table in MSSQL. You can then process the data in MSSQL using OPENJSON via the DB SQL Executor, which allows you to execute any query on the db side. It’s kind of answering what you asked “is there a smart solution to get JSONs directly into an existing SQL table, without processing that amount of data into KNIME-Tables”. You can’t download directly into a db table, at least I don’t think so, but you don’t have to “process” the data. Download, then send to your db table.
For downloading the json data, it might depend on your source, how much it allows you to download, and of course, how much CPU and Memory your computer has. You can do concurrent requests with the GET Request, so it’s a matter of your source not banning you for being abused, or not bringing down your source, and also how much data can your computer process at the same time.
Thank you @bruno29a,
The first way is the way I did already.
I thought I can skip the step with the TransforToKNIMETable and push the JSON directly into the MSSQL DB Table (‘OPENJSON via the DB SQL Executor’), your second recommendation. Seems I am on the right path.
But I need a hint:
Assuming, I have the following: I got a column of multiple JSONs (approx. 100 or more), due to the parallel processing of multiple API calls each 1000 records. .
How do I get those JSONS at best into an SQL Executer statement in order to ‘OPENJSON’? transforming them into variables seems not to work?
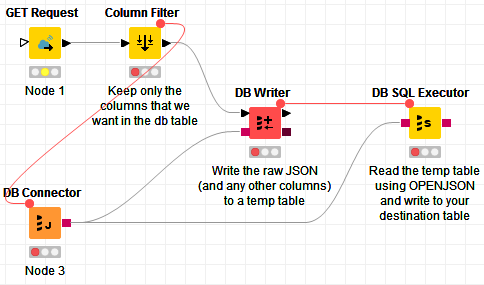
Hi @d00m , the DB SQL Executor is meant to execute an SQL statement on the db server side, so as I suggested, the idea is to send the raw JSON to your MSSQL server first, into a temp table (you can use the DB Writer node for this), and then use OPENJSON on the server to read from the raw JSON from the temp table via the DB SQL Executor.
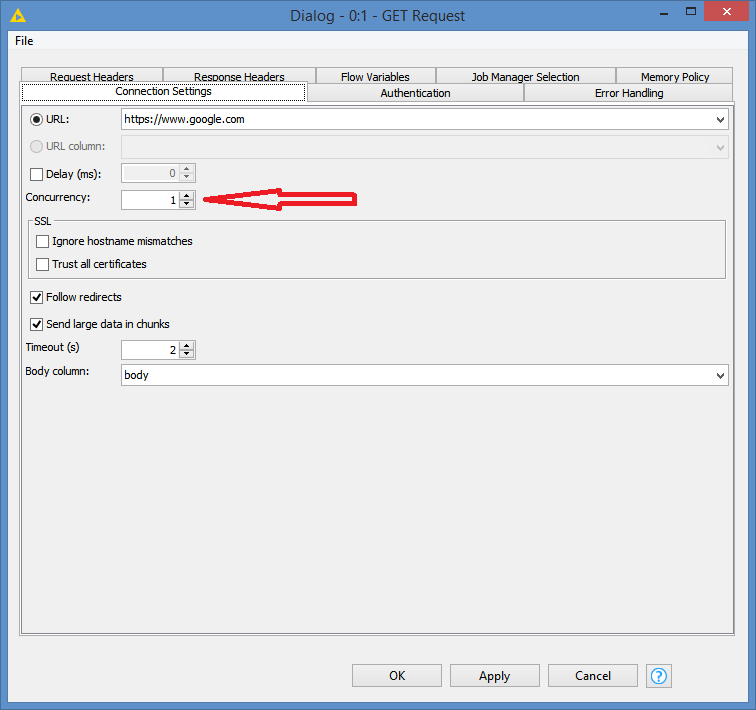
FYI, if you are using the Parallel Chunk loop only to be able to retrieve the JSON data in parallel, you can simply use the concurrency option that the GET Request offers:
You’re not “processing” anything in that loop, you’re just retrieving what the GET Request is returning, so you don’t really need the loop if it’s just to retrieve multiple JSON in parallel. Just make sure you don’t get banned for abusing the server.
A simplified workflow might look something like this:
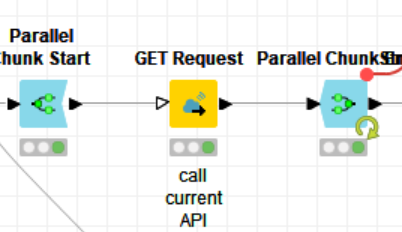
Hi @Daniel_Weikert , yes, this is because the GET Request could be a bottleneck and can take long to execute. The connection between the nodes is to make sure that DB Connector initiates the connection only after the GET Request is completed mainly, but might as well do it after the Column Filter.
If I don’t do that connection, the DB Connector will initiate a DB connection at the beginning, and will remain idle during the time that the GET Request (and Column Filter) is running. If these take long to run, your connection might expire by the time you try to write to the DB.
 .
.