
Hello, just want to ask how to get these two details using REGEX or any approach you may suggest… I can’t find a step for now. Though, the data which is fixed here is “,0000” (the amount like 25 may vary depending on the KG). Hope someone can help! Thank you!
Hi @trafalgarlaw , and welcome to the KNIME community.
To define the regex for a particular string we would need to have examples of other strings that we are also going to need it to inspect, or be given more detailed information about the structure of your data . Otherwise the regex might work for this example, but would fail against other examples. Likewise to provide any other mechanism for extracting the values we would need to know if there is any standard to the field lengths, or delimiters or other “constants” that we can identify.
Also when you say “the amount like 25 may vary depending on the KG”, what do you mean by that?
Is 25 the value that varies, but it will always say “KG”?
Which values are you trying to extract? It looks like “34039900” and “KG”, so is “KG” always “KG” or could it be other letters?
Sorry if those questions seem odd to you, but please keep in mind that you may know your data but to us it is just a sequence of letters and numbers, even if “KG” may appear to look like it might mean “Kilograms”.
Are you able to post this and other examples as text rather than a screenshot, and give more insights on the general format that is expected?
For somebody to assist, I think they would need to be able to “play” with the data. thanks ![]()
1 Like
Thanks for responding @takbb, appreciate your inputs!
By the way here’s the data in text: 0043370157 Graxa lubrificante sintetica - ISOFLEX TOPAS L 32, 09274422 34039900 510 6653 KG 25,0000 227,4284 5.685,71 5.685,71 682,29 639,64 12,00 11,25
To answer most of your questions: KG may change to L which means Liter so I am thinking given that “,0000” in “25,0000” is fixed, we can use “,0000” as identifier for getting the “KG” and “34039900” data.
I was trying to use “/s.,0000” - which is after “,0000” and its space, we will get the next word and our splitter will be the spaces. Because the format is fixed when it comes to the sequence of details for these: “34039900 510 6653 KG 25,0000” - even the 510 and 6653 will always be 3 and 4 digit respectively.
My approach will be (but I cant do it) - get the next word after “,0000” then also get the “34039900” by counting the how long it is from “,0000” like for example “-21” in substring but not sure.
Hope this clarifies my concern or provide a bit of information but still if not, let me know ![]() Happy to add details into it! Thank you!
Happy to add details into it! Thank you!
Thanks for the additional information @trafalgarlaw . Although you have said it is fixed format, it sounds like it isn’t totally “fixed” if “KG” can become the single letter “L”, so I’m assuming the whole row format isn’t fixed length? (Does what appears to be the description “Graxa lubrificante sintetica - ISOFLEX TOPAS” vary in length?)
If the whole thing were fixed format then we could include character lengths within the regex for example, or the substr function in String manipulation, or maybe the “Cell Splitter by Position” node.
Using the Regex Split, the following might work. I believe it works from my understanding of the example data:
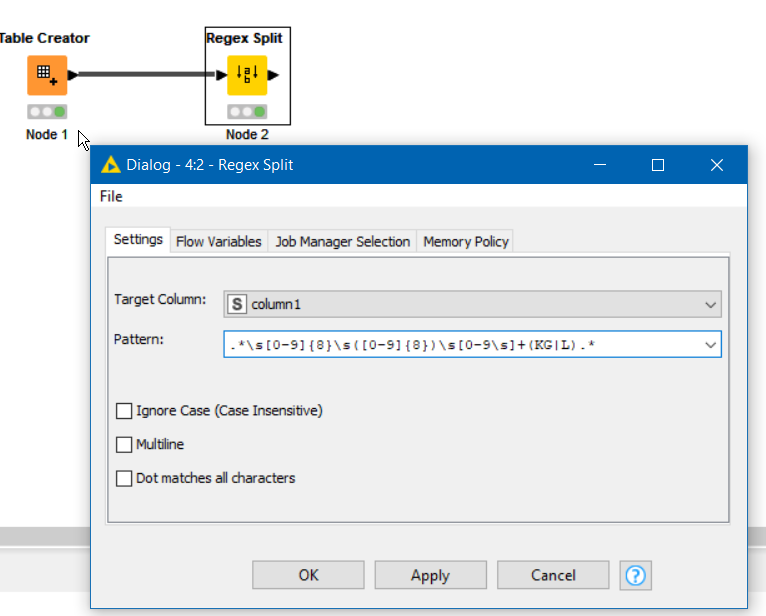
.*\s[0-9]{8}\s([0-9]{8})\s[0-9\s]+(KG|L).*
This looks for an 8 digit string that is after the first 8 digit string and whitespace and captures it. It then ignores all numerics and white space up to the KG or L, and then captures the KG or L, and ignores the remainder of the string:

Does that work for you?
EDIT: an alternative regex based on your thoughts for locating the “,0000” might be:
.*([0-9]{8})\s[0-9\s]+(KG|L)\s[0-9]+,0000\s.*
2 Likes
Thank you @takbb, I will check it and confirm if this works tomorrow morning. I am also planning to add details if I saw one. Again, thank you will get back asap
Hello @takbb, I’ve tried and it worked however yes you are correct the length of this column data is not fixed because when I tried another invoice the data is this:
Data: 31081800 OEM SYNTHETIC DEO 5W30 27101932 830 6651 L 9.801,0000 13,1454 128.838,07 0, 00 0, 00 0, 00
And what I need to get is same set of data which is: “27101932”, “L” - data after “,0000”
Also here’s some sample data for reference:
Data: 31081800 OEM SYNTHETIC DEO 5W30 27101932 830 6651 L 9.542,0000 13,1454 125.433,41 0, 00 0, 00 0, 00
Data to get: “27101932”, “L” after “,0000”
Hope you could help me resolve this mystery! ![]()
Hi @trafalgarlaw , I see that the format of this new data differs in several places to the original data sample, and there appear to be a different number of “fields” or individual items in this line so my initial attempt which looked for multiple 8 digit strings as a reference point cannot work.
However, the second regex (included in my “edit” at the end) which was based on the position of “,0000” can still be made to work, if we also allow for “.” within the “number string” preceding the comma.
i.e. in the Regex Split instead of
.*(\d{8})\s[0-9\s]+(KG|L)\s[0-9]+,0000\s.*
try this:
.*(\d{8})\s[0-9\s]+(KG|L)\s[0-9.]+,0000\s.*

5 Likes
It worked, thank you so much @takbb. But just a curious question, can this be done instead of Regex Split node into a Column expression or String Manipulation node?
Also - lets say another unit will appear like Barrel instead of KG or L, I will just add it in the code like (KG|L|BBL) ?
If it is always same position you could try substring function in string manipulation and yes regarding your regex adjustment
br
1 Like
thanks Daniel. but can this be done in column expression node instead of regex split?
Hello @takbb, i think column expressions will do? But not sure how to integrate the regex coding into column expressions node.
Hi @trafalgarlaw , I hardly ever use Column Expressions so I’m by no means an expert on it, but if you are just using it to return the different fields you can use the regexReplace function like this:
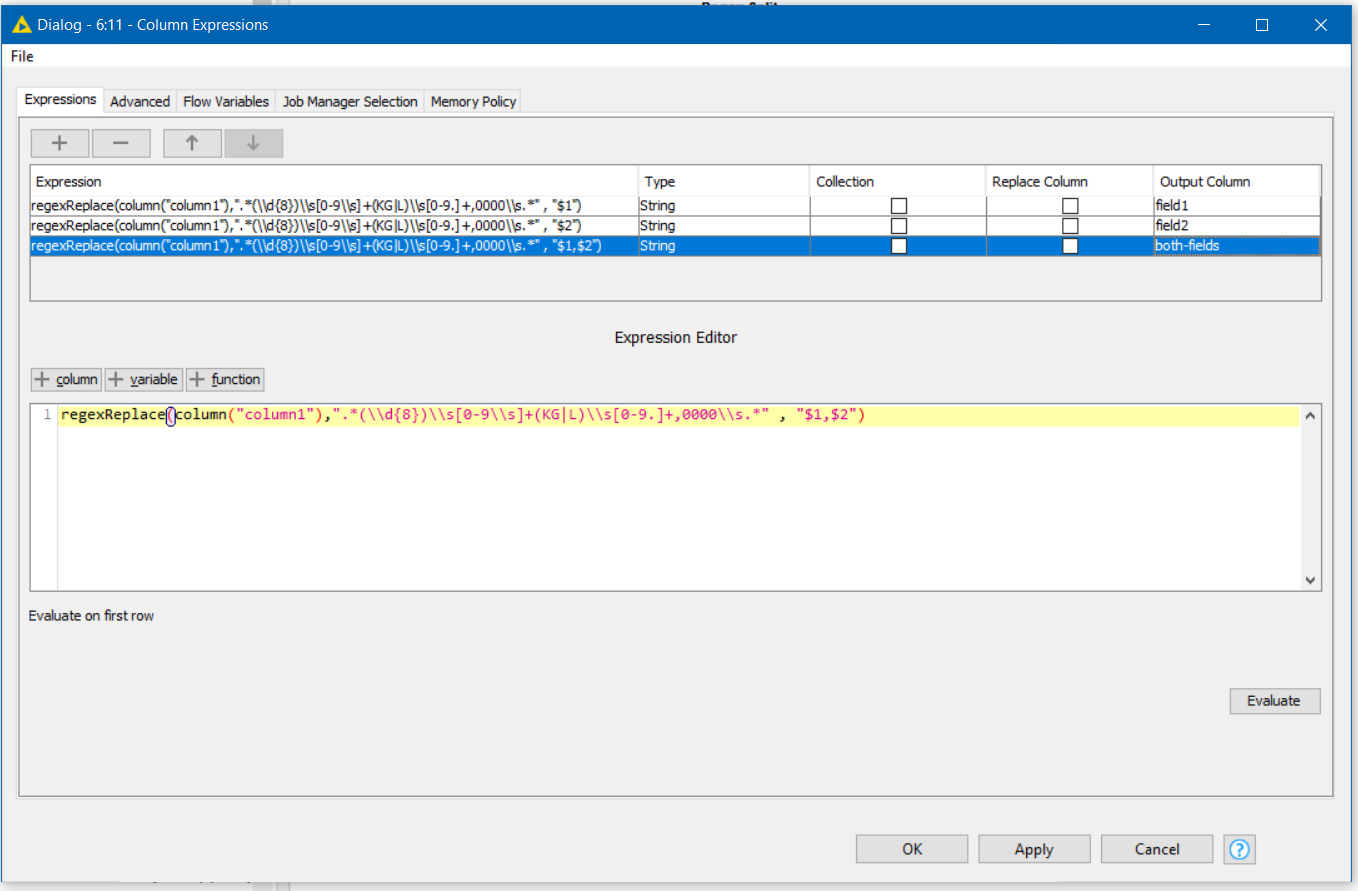
In the screenshot I have three outputs defined:
field1 which is the first capture-group
regexReplace(column("column1"),".*(\\d{8})\\s[0-9\\s]+(KG|L)\\s[0-9.]+,0000\\s.*" , "$1")
field2 which is the second capture-group
regexReplace(column("column1"),".*(\\d{8})\\s[0-9\\s]+(KG|L)\\s[0-9.]+,0000\\s.*" , "$2")
both-fields which returns both concatenated with comma:
regexReplace(column("column1"),".*(\\d{8})\\s[0-9\\s]+(KG|L)\\s[0-9.]+,0000\\s.*" , "$1,$2")
Note that when using the regex expression within a string in a scripting node, you need to use double backslash \\ instead of \ as otherwise the node’s parser will misinterpret it.

forum 71689 - regex example.knwf (11.9 KB)
Edit: If you are planning on writing a longer script utilising both of the fields to produce other output, you can of course just return each value into variables within the script, and manipulate these.
e.g. to produce a message ![]()
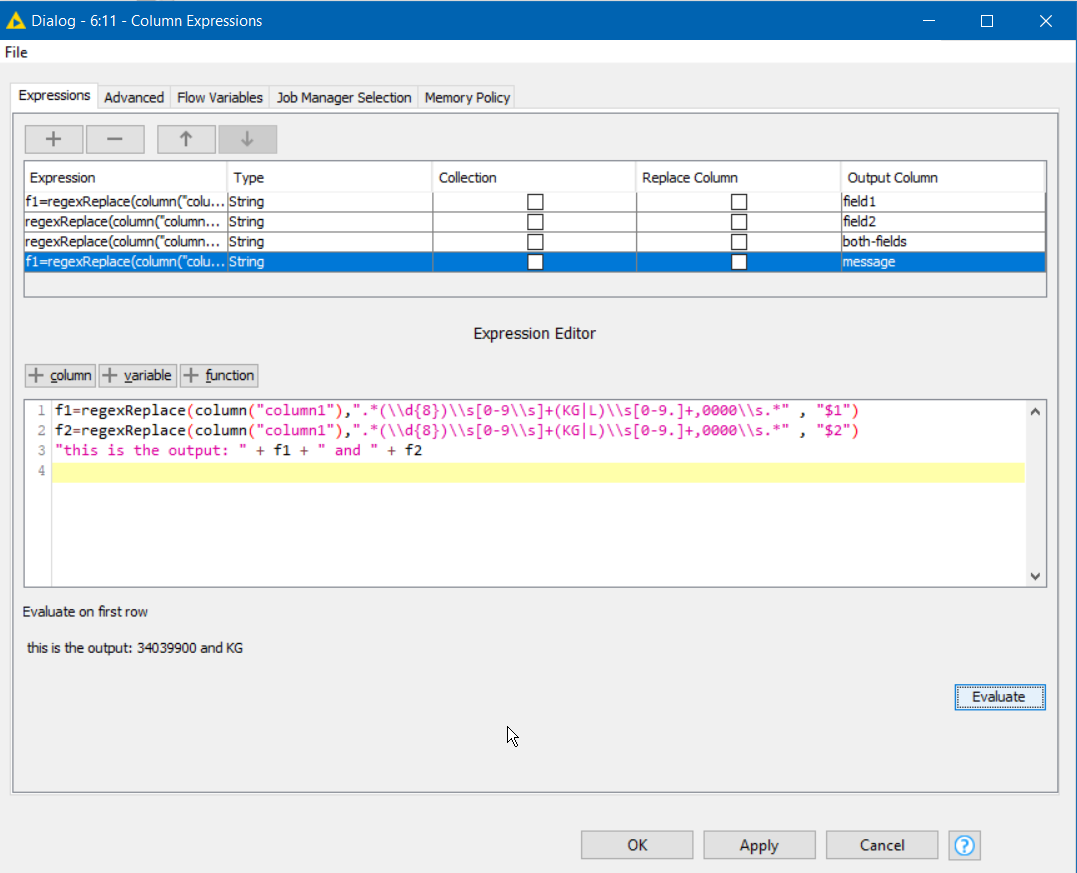
f1=regexReplace(column("column1"),".*(\\d{8})\\s[0-9\\s]+(KG|L)\\s[0-9.]+,0000\\s.*" , "$1")
f2=regexReplace(column("column1"),".*(\\d{8})\\s[0-9\\s]+(KG|L)\\s[0-9.]+,0000\\s.*" , "$2")
"this is the output: " + f1 + " and " + f2
3 Likes
Thank you @takbb!! This is my first time in KNIME Hub and I regret every second of not creating an account before. It was an awesome experience here, again thanks a lot for the new learnings! Hope everyone can see this too and learn from it. Amazing human @takbb!
1 Like
@trafalgarlaw
You might have found the “One Piece”
br
@Daniel_Weikert Indeed, Nakama! ![]()
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.