Hi,
I try to get XBRL files (xml) from [Consult | nbb.be].
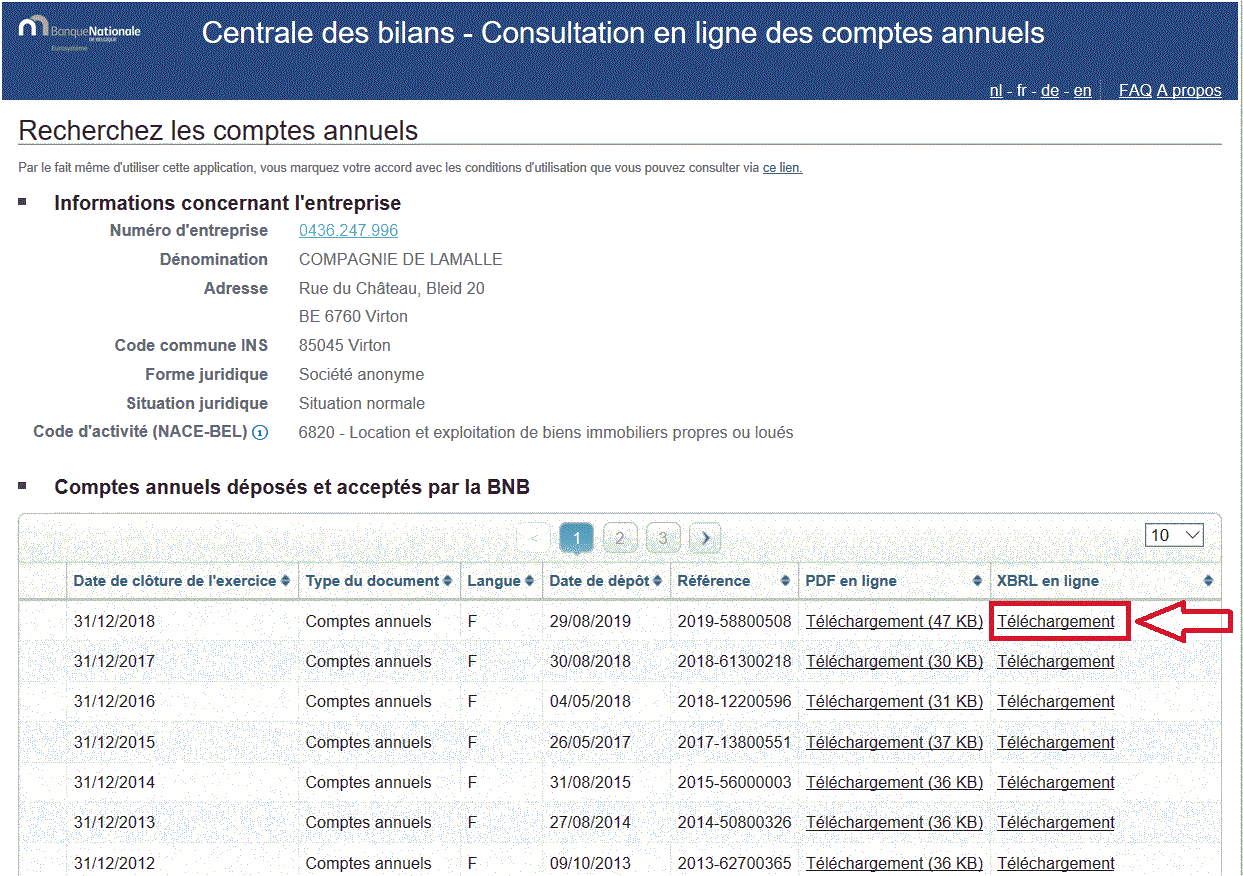
Is it possible to do it with the new WebPage Retreiver or the palladian HTTP Retriever and HTML Parser?
Hi,
I try to get XBRL files (xml) from [Consult | nbb.be].
Is it possible to do it with the new WebPage Retreiver or the palladian HTTP Retriever and HTML Parser?
Not really (at least not without a bunch of reverse engineering) – clicking the link performs a bunch of JavaScript code in your browser and at the end a POST request with several parameters which are generated on the fly.
For more background and a potential option see here (this was about an AngularJS-based website, but the same applies in above case):
– Philipp
Many thanks.
I’m ready to use the selenium nodes to do the job but I don’t have knowledge at this time to do it.
I try to find global solutions (easy to maintain, widespread and have a single tool for all the members of my Administration where I’m working). The goal is to propose the same capabilities to all members because all these members are a workforce to maintain and develop knowledge inside the organization.There are more ideas (and various) in multiple head instead of a unique.
For maintenance, it should be interesting to have a single organization licence and the difficulty at this time is to propose something with a fee against commercial tool (like SAS or Arbutus or ACL) used actually. There are at least 1000 people at the beginning and 20.000 potential users of the same tool or more if other administrations are interested (around European administrations).
I’m working to normalize the tools to enhance collaborations between people, services, administrations. At this time, 200 people (dataminer, e-auditors for Forensic, internal Business parteners are using commercial software for a big amount and I try to optimalize tools (autonomy, independance) for our citizens.
Best regards.
Hey PBJ,
no worries – in case you want to give it a try (now or later, anytime), feel free to get in touch directly with me at mail@seleniumnodes.com and we can discuss potential paths and strategies for introducing the nodes, our reference use cases, and support regarding your specific requirements.
Also, in case of specific questions which are of general interest, feel free to post here! Some scraping/extraction tasks can be definitely solved with the more basic and free solutions (i.e. the ones provided by KNIME or the Palladian nodes), and I’m happy to support there as well.
Kind regards,
Philipp
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.