After fetching secrets from the keyvault, request is sent with secrets to fetch token to access the Databricks.
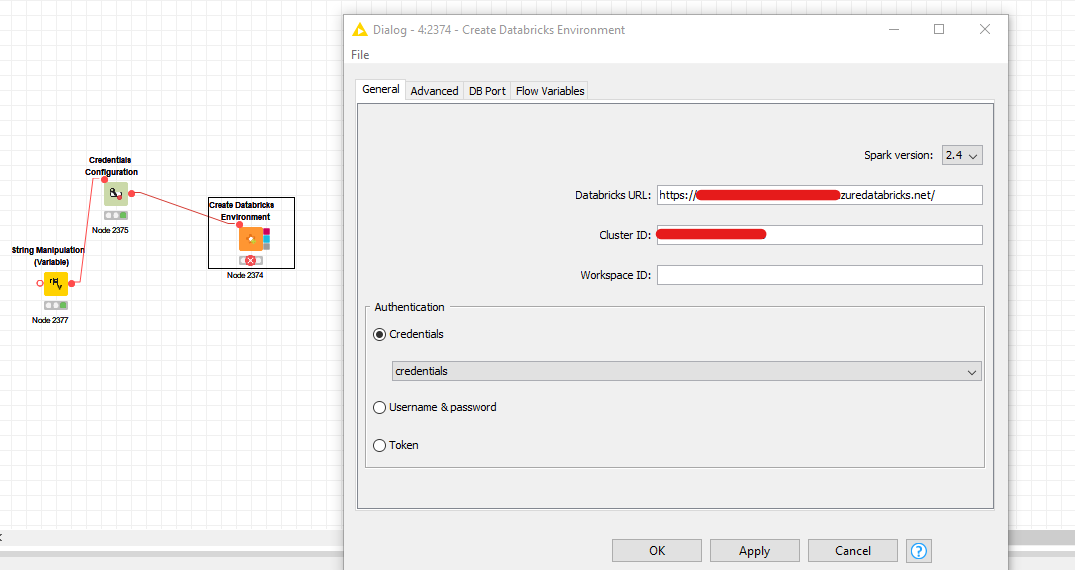
I used Create Databricks Environment node, and after passing required data to the node, I am getting 401 error.
ERROR : KNIME-Worker-5-Create Databricks Environment 3:1 : : Node : Create Databricks Environment : 3:1 : Execute failed: Could not open client transport with JDBC Uri: jdbc:hive2://db-url.azuredatabricks.net:443/default;ssl=true;httpPath=sql/protocolv1/o/0/clusterId;transportMode=http: Could not create http connection to jdbc:hive2://db-url.azuredatabricks.net:443/default;ssl=true;httpPath=sql/protocolv1/o/0/clusterId;transportMode=http. HTTP Response code: 401
java.sql.SQLException: Could not open client transport with JDBC Uri: jdbc:hive2://adb-db-url.azuredatabricks.net:443/default;ssl=true;httpPath=sql/protocolv1/o/0/clusterId;transportMode=http: Could not create http connection to jdbc:hive2://adb-db-url.azuredatabricks.net:443/default;ssl=true;httpPath=sql/protocolv1/o/0/clusterId;transportMode=http. HTTP Response code: 401
at org.apache.hive.jdbc.HiveConnection.openTransport(HiveConnection.java:231)
at org.apache.hive.jdbc.HiveConnection.<init>(HiveConnection.java:168)
at org.apache.hive.jdbc.HiveDriver.connect(HiveDriver.java:105)
at org.knime.database.connection.UrlDBConnectionController$ControlledDriver.connect(UrlDBConnectionController.java:95)
at org.knime.database.connection.UrlDBConnectionController.createConnection(UrlDBConnectionController.java:308)
at org.knime.database.connection.UserDBConnectionController.createConnection(UserDBConnectionController.java:249)
at org.knime.bigdata.database.databricks.DatabricksDBConnectionController.createConnection(DatabricksDBConnectionController.java:118)
at org.knime.database.connection.AbstractConnectionProvider.createConnection(AbstractConnectionProvider.java:89)
at org.knime.database.connection.impl.DBConnectionManager.lambda$2(DBConnectionManager.java:501)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.thrift.transport.TTransportException: Could not create http connection to jdbc:hive2://adb-db-url.azuredatabricks.net:443/default;ssl=true;httpPath=sql/protocolv1/o/0/clusterId;transportMode=http. HTTP Response code: 401
at org.apache.hive.jdbc.HiveConnection.createHttpTransport(HiveConnection.java:275)
at org.apache.hive.jdbc.HiveConnection.openTransport(HiveConnection.java:201)
... 12 more
Caused by: org.apache.thrift.transport.TTransportException: HTTP Response code: 401
at org.apache.thrift.transport.THttpClient.flushUsingHttpClient(THttpClient.java:262)
at org.apache.thrift.transport.THttpClient.flush(THttpClient.java:313)
at org.apache.thrift.TServiceClient.sendBase(TServiceClient.java:73)
at org.apache.thrift.TServiceClient.sendBase(TServiceClient.java:62)
at org.apache.hive.service.cli.thrift.TCLIService$Client.send_OpenSession(TCLIService.java:150)
at org.apache.hive.service.cli.thrift.TCLIService$Client.OpenSession(TCLIService.java:142)
at org.apache.hive.jdbc.HiveConnection.createHttpTransport(HiveConnection.java:267)
... 13 more
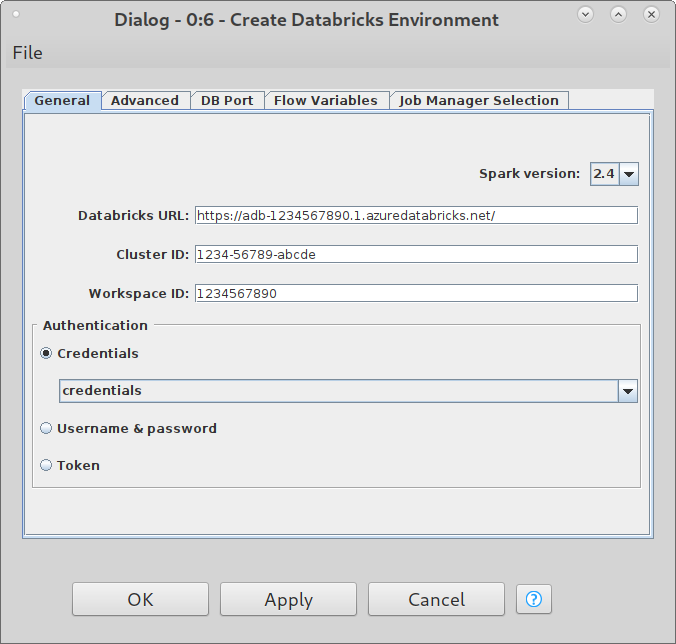
I need to use AAD authentication between JDBC databricks driver on KNIME to databricks cluster.
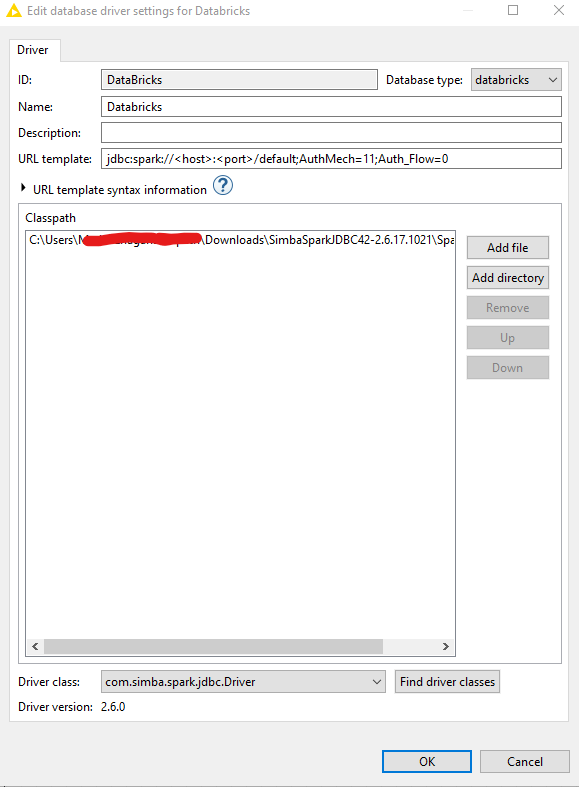
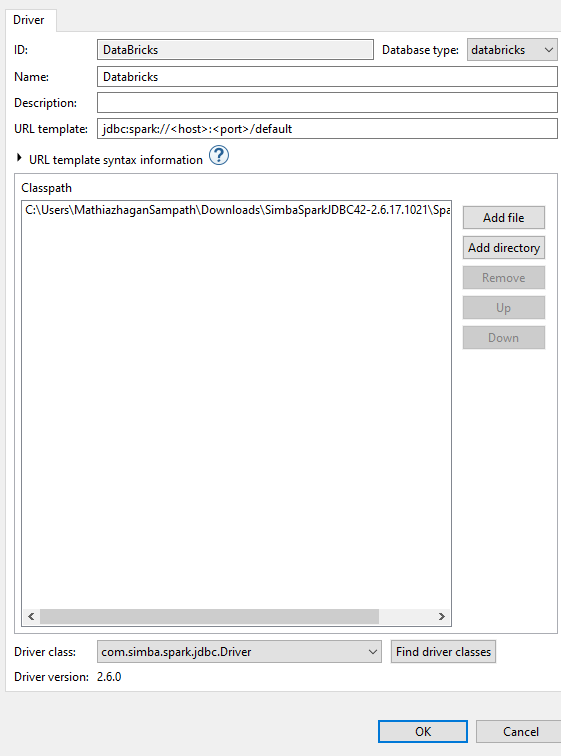
As per the documentation, to use AAD token (Workspace cluster), The URL template should be like jdbc:spark://databricks.azuredatabricks.net:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/xxxxxxxx;AuthMech=11;Auth_Flow=0;Auth_AccessToken=AAD_TOKEN
When I check the logs of KNIME , the template / URL is like below jdbc:spark://databricks.azuredatabricks.net:443/default and parameters: [UID, ssl, user, password, httpPath, transportMode, PWD, AuthMech]
we never know what is the value of AuthMech is used and how credentials FV value is mapped to user, password or PWD
I see that KNIME need to make changes in URL template of the driver to access Workspace cluster using AAD_Token. Currently it supports only personal access token/ user name & Password, which is not recommended way to use in production.
Is there any workaround please suggest. It is a blocker.
the Create Databricks Environment node supports only personal access tokens, not the Azure AD tokens. I do not have an Azure AD setup right now, but you can try the following:
Download and register the Databricks JDBC driver in KNIME with the following URL template:
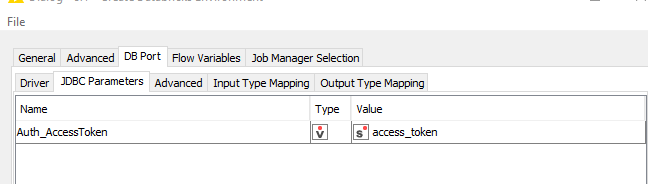
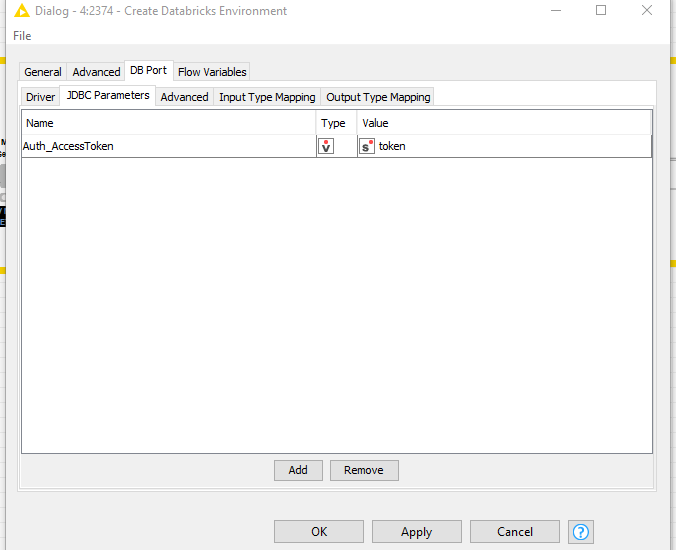
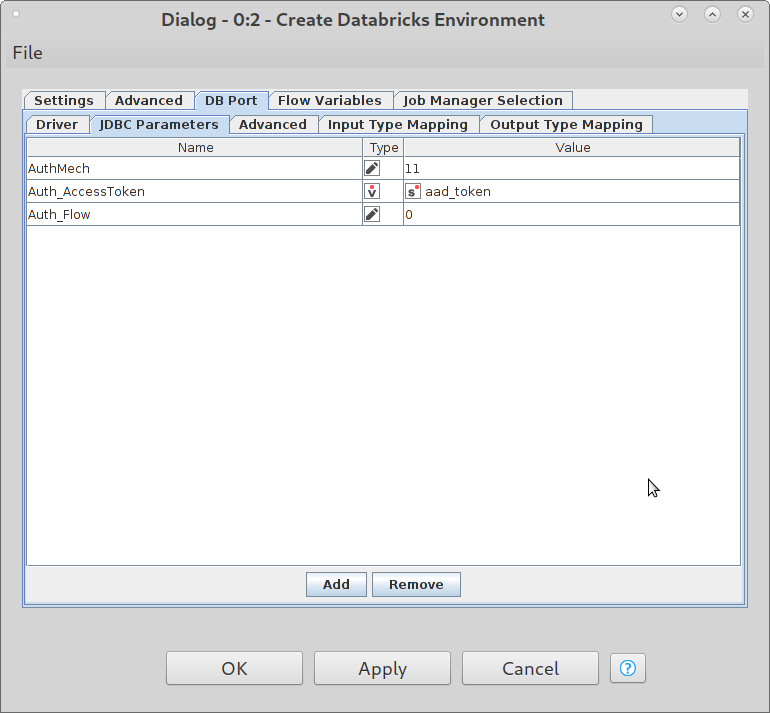
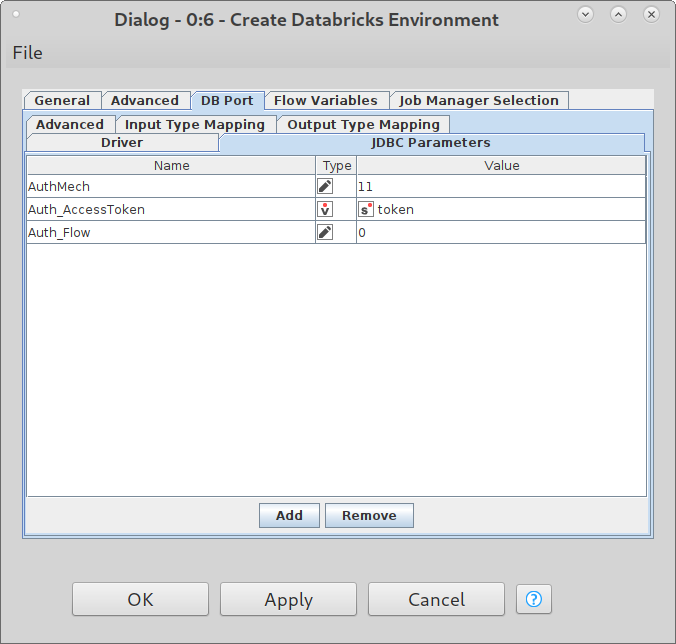
In the configuration dialog of the Create Databricks ENV node, go to DB Port and then the JDBC Parameters tab and add a new Parameter Auth_AccessToken with your token or a flowvariable to set the token.
As already mention, I did not have a setup to test this right now and It depends on the driver if it uses the AuthMech from the URL or parameters.
That’s true, user name and passwort is not recommended, but personal access tokens should do the job in production.
After execution in logs I see that URL to connect to databricks is
` > jdbc:spark://databricks.azuredatabricks.net:443/default;AuthMech=11;Auth_Flow=0;UID=token;ssl=1;httpPath=sql/protocolv1/o/0/clusterId;transportMode=http;PWD=AAD_TOKEN;
> AuthMech=3;Auth_AccessToken=AAD_TOKEN and parameters: [user, password]. Exception:
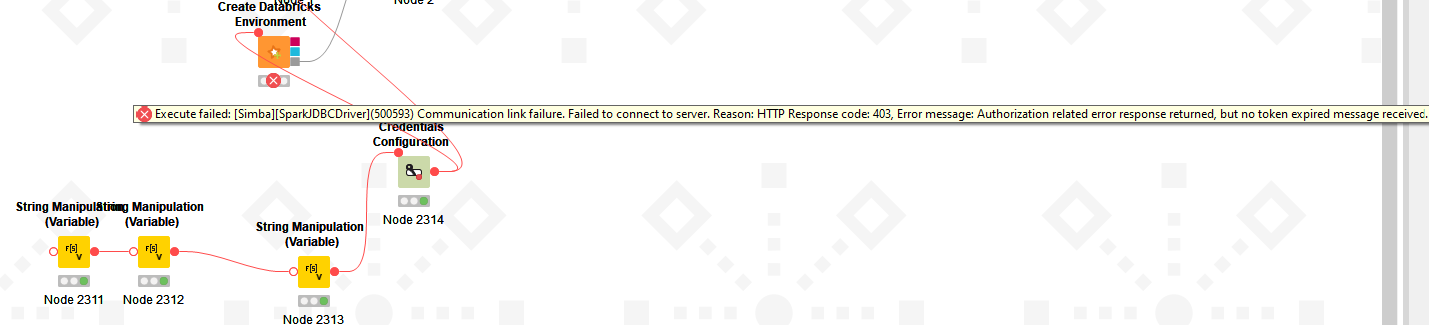
Error:
[Simba]SparkJDBCDriver Communication link failure. Failed to connect to server. Reason: HTTP Response code: 401, Error message: Unknown.`
My question is how to avoid the extra parameters that are injected into URL by default.
As per documentation, I need to have URL as follows -
we released KNIME 4.2.5 that contains a fix on this and now allows the user to overwrite the AuthMech parameter using the JDBC Parameters tab as a workaround. You have to use the Databricks JDBC driver, add the three parameters to the tab and you should be able to connect using Azure AD tokens: AuthMech=11, Auth_Flow=0, Auth_AccessToken=<token>
If I use Personal access token instead of AAD token with above setup, it is working fine.
The AAD token was not expired one (verified it).
Can you please share me a workflow or screen shot of successful scenario where you have achieved to connect to databricks with AAD token, it will be really helpful?
Hello mathi,
the additional JDBC properties are only necessary when the parameter needs to be enforced when the node is executed on the server as described in the DB documentation. So in your case I would remove the additional properties since they are anyway specified in the workflow and don’t need to be overwritten on the server.
Bye
Tobias