I am very very new to anything ML and would like to use KNIME to get started with it. I am looking for advice on what approach to use to get started for my use case below.
I would like to train a model to identify on variations of a Business Name and then normalize it to a correct version of that name (that I provide) so when the dateset is introduced I can use the trained model to normalize the entries (again, based on ‘correct’ entries I provide).
For example:
Given the following list:
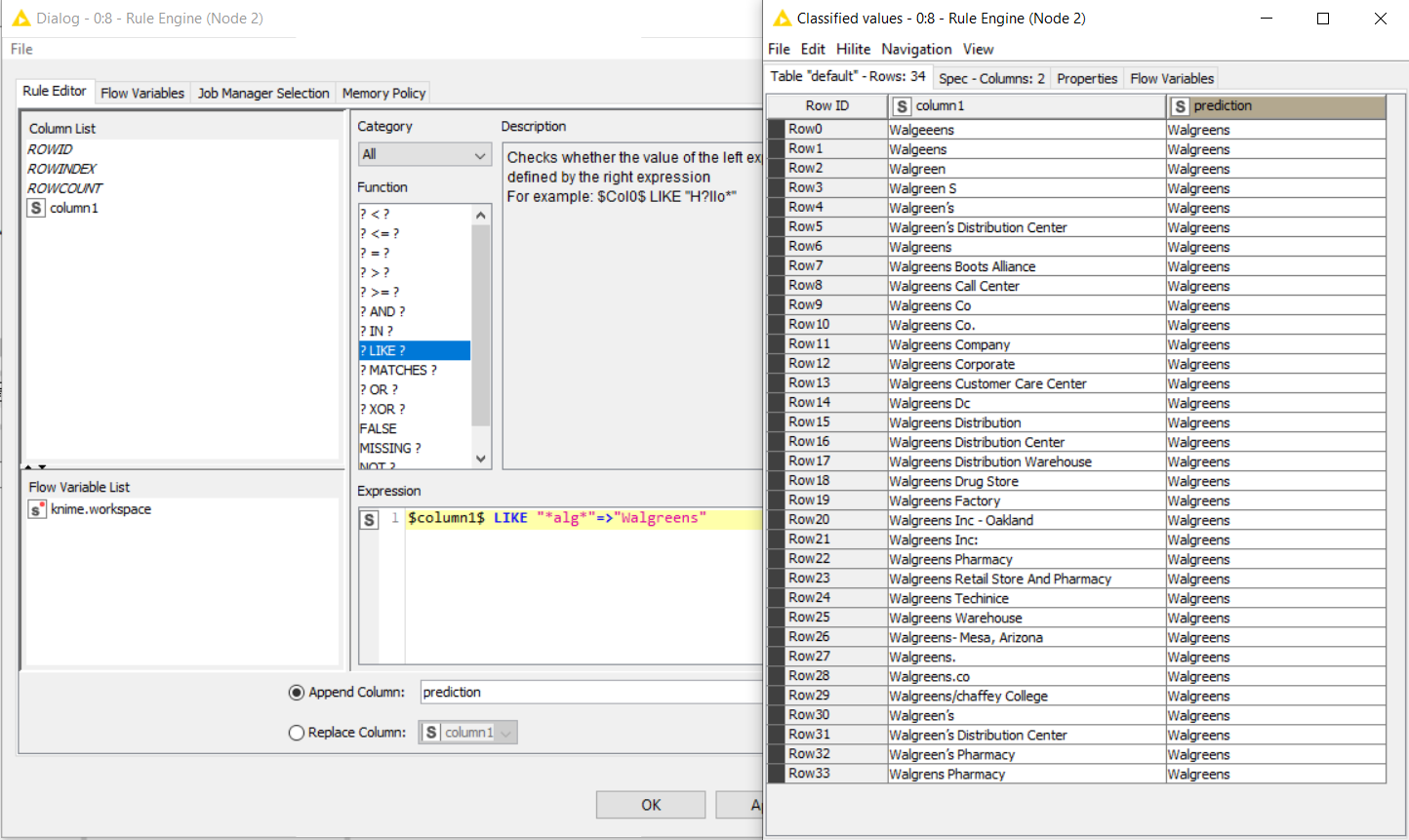
Walgeeens
Walgeens
Walgreen
Walgreen S
Walgreen’s
Walgreen’s Distribution Center
Walgreens
Walgreens Boots Alliance
Walgreens Call Center
Walgreens Co
Walgreens Co.
Walgreens Company
Walgreens Corporate
Walgreens Customer Care Center
Walgreens Dc
Walgreens Distribution
Walgreens Distribution Center
Walgreens Distribution Warehouse
Walgreens Drug Store
Walgreens Factory
Walgreens Inc - Oakland
Walgreens Inc:
Walgreens Pharmacy
Walgreens Retail Store And Pharmacy
Walgreens Techinice
Walgreens Warehouse
Walgreens- Mesa, Arizona
Walgreens. Walgreens.co
Walgreens/chaffey College
Walgreen’s
Walgreen’s Distribution Center
Walgreen’s Pharmacy
Walgrens Pharmacy
My training data would include those values and then the correct value would simply be Walgreens.
I have a large dataset of employers with this kind of variation and the correct names for them.
Any thoughts/guidance on how to approach this is greatly appreciated!
Another approach here might be to use the Similarity Search node with Levenshtein distance - you feed the misspellings to the top port and your dictionary to the middle port, and let the node find the best match.
I just made a simple workflow (based on an exercise from our L1-DW course) that uses your data:
Thank you all for the great ideas, I am still working on a solution. Ideally I would like to develop a workflow/process that moves new data through a comparison of a 28 million row dateset in as efficient a way as possible.
I would like to take a multi-step ‘ensemble’ approach to the processing and this includes so far this fuzzy matching and then some TF-IDF cosine similarity work to make as many matches as possible. The issue that I run into is that it’s extremely time consuming to try to make these different matches, which is why I was interested in a potential learning model that may already know how entries should be matched based on a training dataset.
@ScottF thankyou for providing the example you did, I really appreciate it!