Hi @svki0001 , there isn’t an out of the box solution for finding the first and last row in a grouping. There are techniques that can be employed using “moving aggregation” or “ranking” nodes, to provide an ordinal position which can then be used to find the start and end of a grouping but your groupings do not have a “unique” key (combination of uid and activity) as this can be repeated as per your example data. Such solutions would therefore probably find the very first, and very last item in each group which isn’t what you want.
For such a purpose, it is possible to use the java snippet to find the groupings. If you know some java, or are interested in learning more about that then could take a look at my post “java snippets have long memories” post to get an idea of how such a snippet can work, but that isn’t necessary if you don’t wish to as I encapsulated the functionality required to assist with such a task into a component on the hub:
It possibly isn’t immediately apparent how finding a “cumulative sum” is going to help, but hopefully that will become clearer in a moment.
What we can do is first of all create a “grouping key” to identify rows which belong to the same group. This will be uid and activity. For this, you could use any node capable of joining two columns into a new value, such as String Manipulation, Column Combiner, Column Expressions, Rule Engine and probably many others. I will use Column Combiner because its purpose is then reasonably self-explanatory. It will concatenate the uid and activity, delimited by a “:”.
After this, a Math Formula can be used to place an integer 1 into a new column (called key-sum).
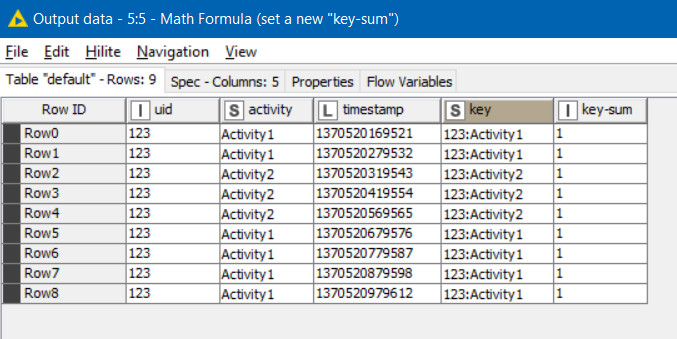
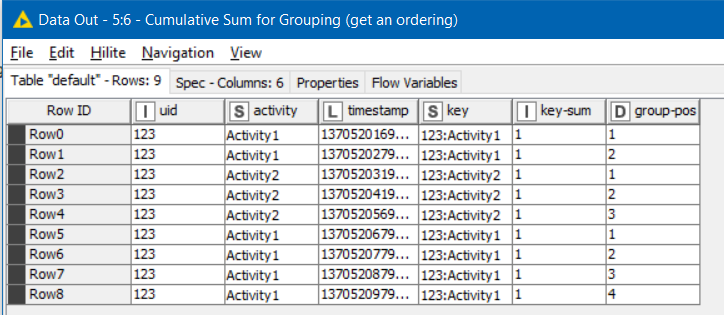
This column will then cumulatively summed for all occurrences of the same “key”, until the value of “key” changes. This is where the Cumulative Sum comes in, and it will generate a column I have called “group-pos”…
By cumulatively summing the key-sum column, Group Pos now identifies the ordinal row position for each row within each current group.
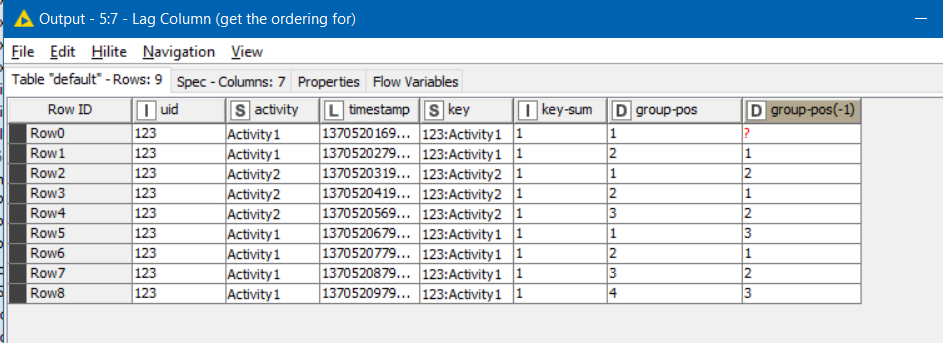
A Lag Column node then places on the row, the Group Pos for the next row.
This is important because it will define the start and end row for each group:
- The start of a group is identified by rows with a group-pos column value of 1
- The end of a group is identified by rows with a group-pos(-1) column value of 1 (i.e the next row is the start of a new group)
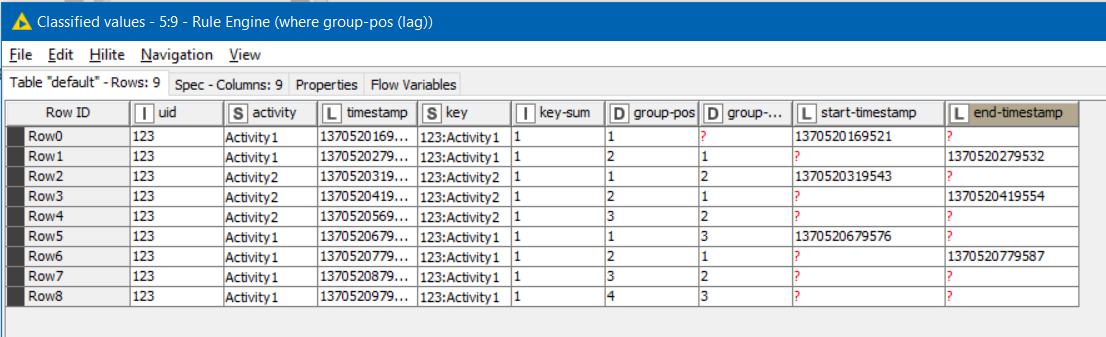
A pair of Rule Engines can then use the above rules to place into a new column the value of the timestamp but only for rows which are start or end of a group.
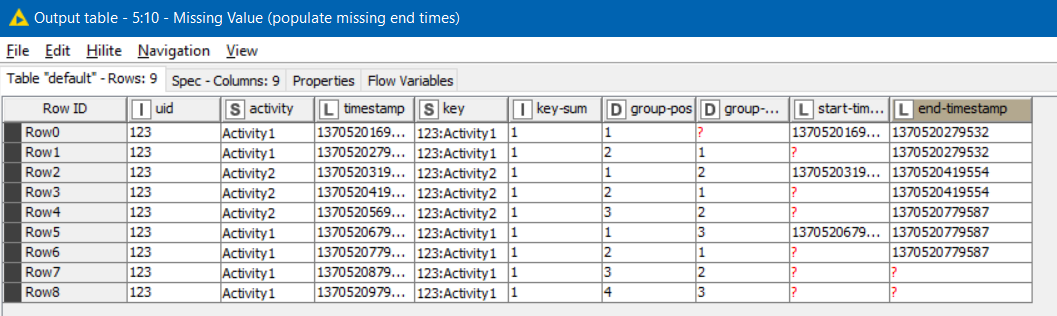
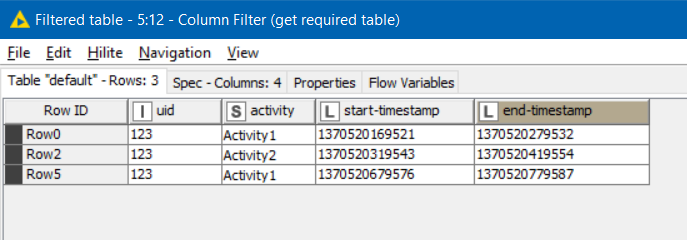
Using a Missing Value node to populate each missing end-timestamp with the next available end-timestamp helps us define rows that now show both a start-timestamp and an end-timestamp for the group:
Finally a row-filter can remove any row that is missing a start-timestamp, and a column filter to remove the superfluous columns, gives the table that you are looking for:
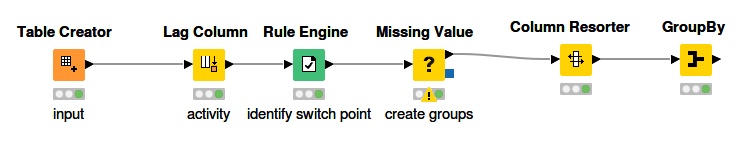
Bringing it all together:
(The initial “node” is actually just a component that allowed me to copy/paste your example easily)
Find first and last for contiguous groupings and retain timestamp columns.knwf (71.4 KB)
I hope that helps. You can of course look inside the Cumulative Sum for Grouping component if you want to see what the java snippet looks like to achieve this.