Hi all,
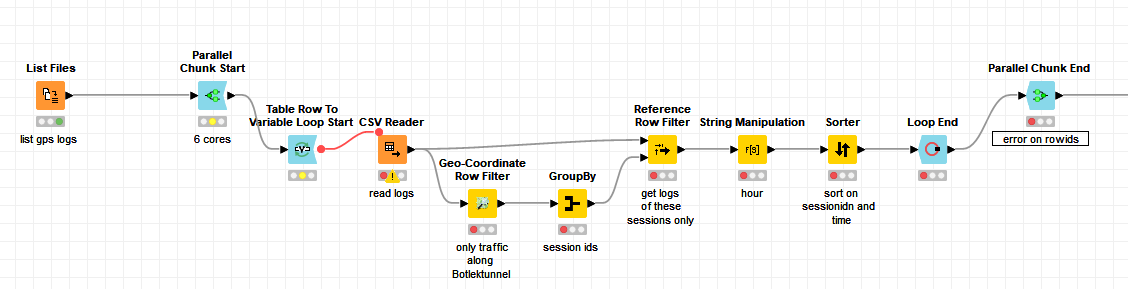
this is an issue in my workflows. I often read 24 hourly files of GPS logs to create a file for the full day.
I would like to do that in a parallel chunk loop, as the files are Huge. What I do first, is list the 24 files, open a Parallel chunk start, and then I use the Table Row to variable loop Start loop, which results in only 4 files per Processor core.
Now the inner Loop generates a Unique RowID by append a suffix. Which is unfortunately not unique, because ever nested loop starts counting at zero, adding the suffix. Which results in an error in the Parallel Chunk End:
ERROR Parallel Chunk End 3:45 Execute failed: Encountered duplicate row ID “Row0”
Are there any tricks, rather than generating my own RowIDs per loop, and use the RowID node?
Thanks!