Hi everyone, hope you are having a great weekend.
Google does not offer official API for Google Trends https://trends.google.com/trends/explore so I am trying to automate the process using Google Trends UI. I was able to automate the workflow using UiPath Studio X, but since Studio X doesn’t have a scheduler and is not scalable, I wanted to build it in KNIME. With Studio X, I have no problem looping thru 800 requests over time from the same IP as my KNIME.
I’m rendering the URL with all the parameters embedded in Selenium and I’m clicking the download icon to download the CSV file. It works fine when able to render the page and graph.
I checked the Network tab in Google Chrome DevTool console (F12) and located the backend API calls, but every call even with same parameters generates a new, different token and I cannot think of a way to automate using these backdoor calls. If you have an idea, I’d love to test it out. Thank you.
The other problem I need to resolve is this below post, although I obviously have to resolve the issue #1 first.
If I’m able to resolve this, I’d like to implement similar flows against more properties as ongoing process. Thank you very much in advance for anyone’s review and help. Hope you have a nice weekend. Take care.
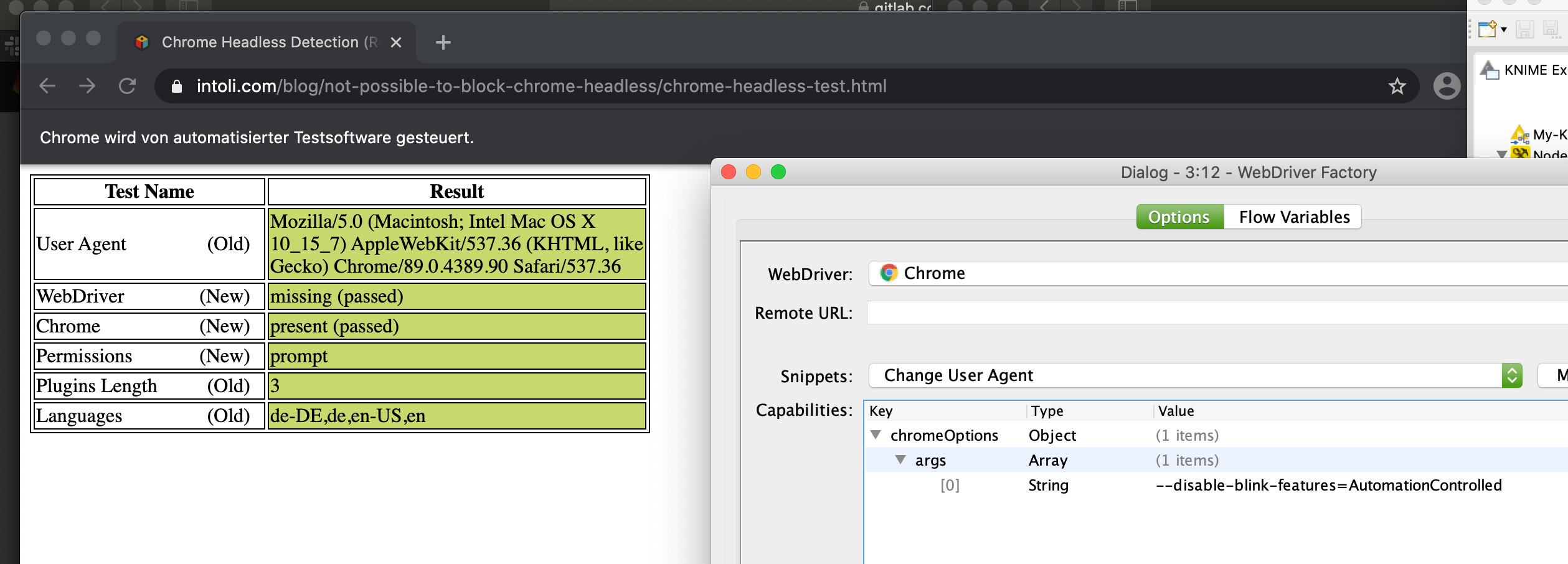
I currently do not have time to investigate this in detail, but my first assumption would be, that the target page checks the navigator.webdriver property, which states whether the browser is “automated”.
You might check if other browsers do not set this property (e.g. Firefox, or probably just give PhantomJS a try, even though it’s no longer maintained)
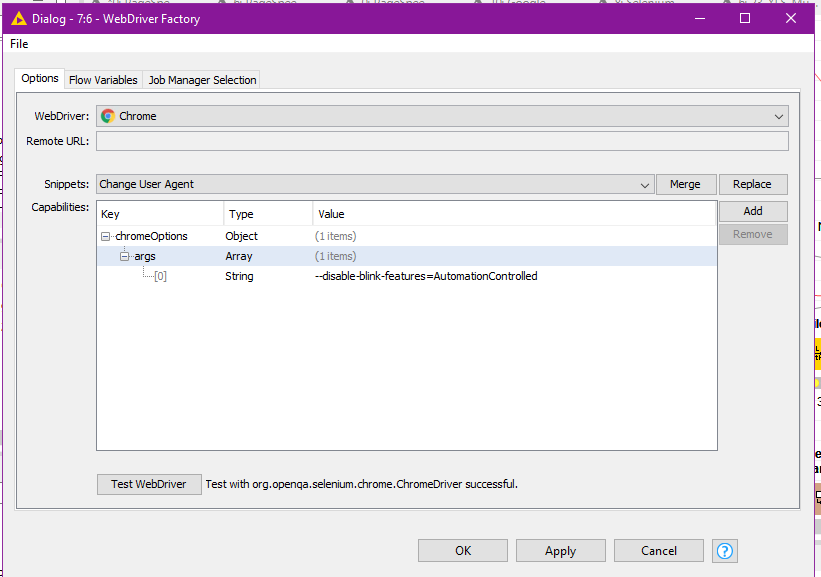
It seems to be possible to disable the flag through a command line toggle which you can provide through the capabilities. Check this link to get an idea.
Flagging @armingrudd here, as I remember a similar conversation about this topic with you a while ago (I think back then, the mentioned flag did not yet exist)
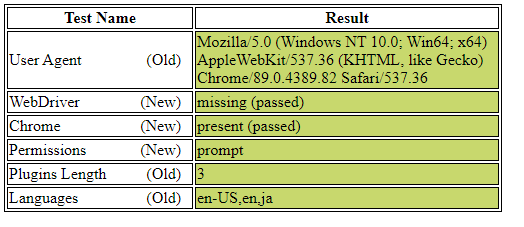
I’m still getting errors, either the below too many requests error or being served their image Captcha screen. I’m running this KNIME from Amazon server and cannot change the IP so I’m going to wait for 24+hrs and try again. Thank you as always, @qqilihq !!
Exactly this might actually be a reason. Requests from AWS instances are often be classified as bots (which is the case obviously, but I also observe it when being connected via VPN to an AWS instance). You could circumvent this by using a proxy provider to cycle IP addresses though
I waited over 24 hours and I am now running the KNIME instance on the residential ISP connection using regular Windows10 instead of AWS Workspace server. Sadly, I’m still getting too many requests error page. It won’t even let me render this https://trends.google.com/trends/explore? URL. I am able to load https://www.google.com/. The odd part is that I can run the automated scripts against this Google Trends site using the same process of rendering the URL with parameters and clicking download icon from the same home IP.
I’ll try to see if I can learn anything from pytrends · PyPI and other unofficial processes. Thank you!!