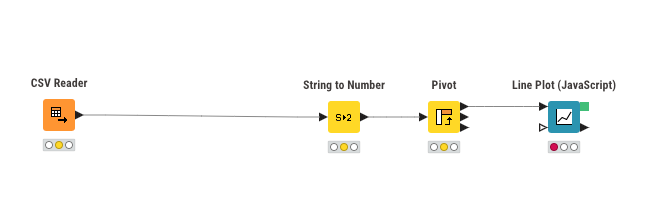
Sometimes we will find that the workflow cannot run, maybe just because there is too much data, it is not easy to see how the error occurred (especially we need to locate the wrong rows in the output table)
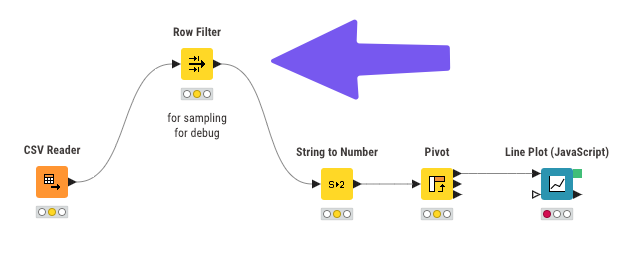
At this time, I usually sample the data based on some conditions:
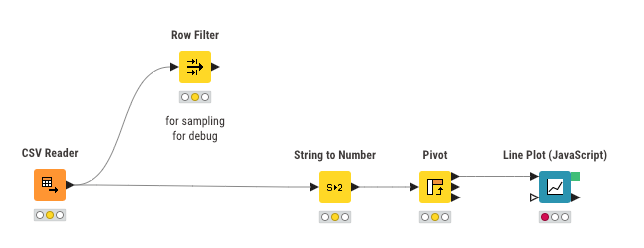
Then, the error will be much easier to detect. After the problem is located and solved, the workflow will become like this:
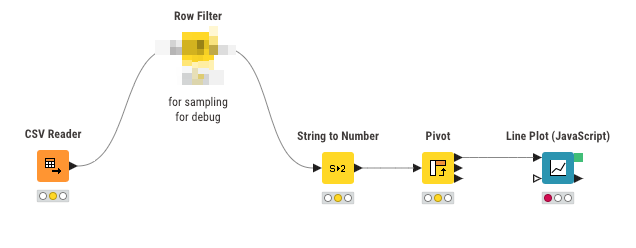
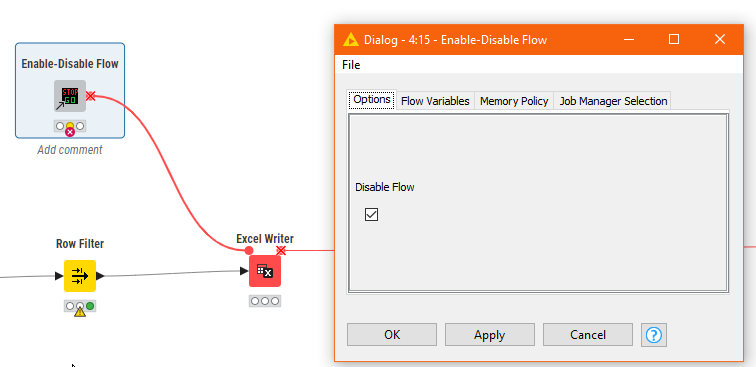
This is actually not a best practice for workflow(We have an orphan node). Maybe the Row Filter should be deleted, but in some cases, I want to keep this node. The reason is that if there is a problem next time, it will be useful to eliminate the error, so , this node remains.
I was wondering if it would be great to turn this node into a “gray” node state (disabled) and leave it in the original workflow (in the demo below, I just blurred it), just let the data flow through it, without doing any processing.
The above is just a small example.
Imagine that we can disable several nodes at will and observe the data. This will lead to a very good user experience when debug and experiment
So you would want to be able to keep nodes in place in the flow, but be able to switch them into a sort of “bypass mode”? I like it! I quite often have to repeatedly place and remove nodes temporarily to edit or review calcs. This is especially true for loops. Yes, you can place it in a component and create a bypass with a Case Switch, but that is far less convenient than a quick platform level bypass setting.
@iCFO Yes, exactly. bypass mode. And the node image is actually svg. I believe add gray layer is simple to denote it is bypassed. In principle, the code should not be difficult to implement, but it is indeed a relatively large change.
I didn’t spot this post back in June but I like the idea @HaveF. I’m often doing exactly the same process you describe and being able to turn on/off filter nodes (or other “debug” nodes) without having to remove them would be very useful.
You’re probably already aware of this, but just for completeness’ sake: You can build something similar yourself by wrapping the node in a component with an IF-Switch. I agree this is more opaque, though.
Doing this in a general manner is not as simple as it sounds though. For instance, any downstream node might depend on e.g. columns provided by the node. Disabling the node would then break the whole downstream part of the workflow. One might say that’s acceptable – not sure.
I would say that is certainly acceptable expected behavior, and likely an additional troubleshooting tool in many instances.
Another massive benefit would be that we could quickly disable the final steps of a workflow to allow us to sandbox during workflow tests / alterations and help mitigate the risk that incorrect data accidentally reaches a working environment if all nodes are executed. Disconnecting nodes (or groups of nodes) is cumbersome and can cause config setting loss.
Hi, @BenjaminMoser
I understand that this is not easy to implement, because each node needs to rely on the table spec of the upstream node. But for some types of nodes, it will not add or delete columns, such as row filter, such as expression row filter. For these nodes, it would be very good if there is a bypass mode. These nodes are critical nodes when debugging.
I agree with you that this function can be implemented with components. However, you cannot tell what the status of a component is just by looking at its icon, so my original suggestion was to use “gray node” so that we can see its status directly.
You need to have the Testing Framework extension installed. I ought to update it so that framework is not needed as I now know I could use Java Edit Variable to block the flow… It was one of the first components I wrote, and my understanding of KNIME has moved on a bit since then
@takbb - Good luck trying to find one of my components or workflows that don’t incorporate your component at least some variation of your Enable-Disable flow component design! I control them with flow variables, use them to disable / hide interactive view config settings when bypassed, force 1 time user interaction actions with loop resets… Not to worry. I am firmly riding on your coattails! In fact, I was only a few months into using KNIME when I realized I could shorten the curve by just opening all your components to study your approach and workarounds. There were probably only a few hundred shared components back then though…
I still think that building the bypass into the UI would simplify things, especially for new users and companies with outside component restrictions.
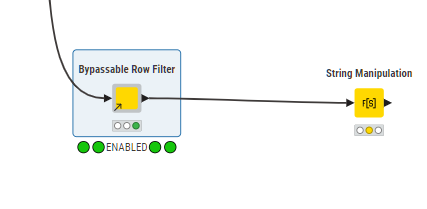
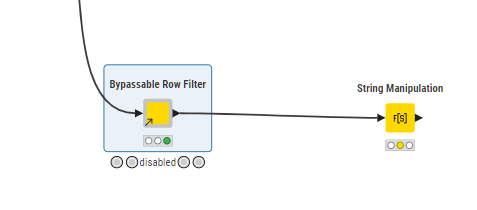
As a result of this thread, I was having a play with visually representing a “diversion” within the limitations of the current UI and nodes.
It’s ultimately just a switch, but with the “simple” aim of making it more visual.
It’s a pity there isn’t a way to apply the node annotation as soon as the config changes, It unfortunately has to wait until execution which kind of defeats the purpose to an extent, but it least it shows up clearly once executed one time.
(Using the Nodepit Power Nodes to achieve the above result)
That “Diversion” component is in my “Experimental” space on the hub, if interested.
The thing that makes it look more fancy than it really is, is the inclusion of emojis in the annotation!
I admire your dedication - some (most) of my components are like spaghetti inside. I sometimes go back to one to see how I did something and I just have a “wtf was I smoking when I wrote this” moment!
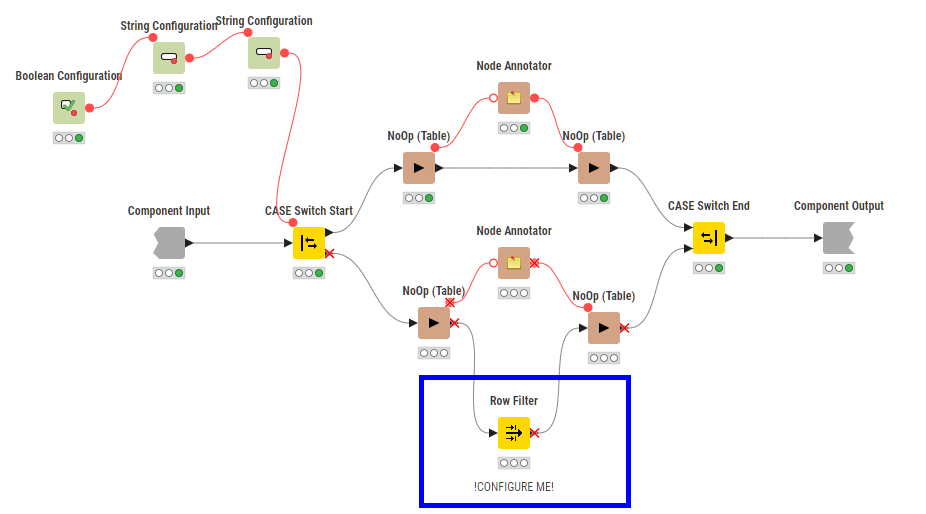
Talking of smoking… I was also looking at the concept of writing a component containing a Row Filter and then annotating the component similar to the “diversion” component above.
It of course suffers from the same problem of the config not being immediately reflected in the annotation, and whilst it kind of work, building the component and configuring the Row Filter would feel like a lot of effort…